EquAct: An SE(3)-Equivariant Multi-Task Transformer for Open-Loop Robotic Manipulation
作者: Xupeng Zhu, Yu Qi, Yizhe Zhu, Robin Walters, Robert Platt
分类: cs.RO
发布日期: 2025-05-27
💡 一句话要点
提出EquAct,一种SE(3)等变Transformer,用于开放式机器人操作任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 SE(3)等变性 Transformer 点云处理 多任务学习
📋 核心要点
- 现有Transformer在处理机器人操作任务时,缺乏对3D几何结构的内在约束,导致在空间变换下性能不稳定。
- EquAct利用SE(3)等变性,设计了等变点云U-net和不变特征调制层,保证模型在空间变换下的几何一致性。
- 在RLBench模拟和真实机器人任务上的实验表明,EquAct显著提升了空间泛化能力,达到了当前最佳水平。
📝 摘要(中文)
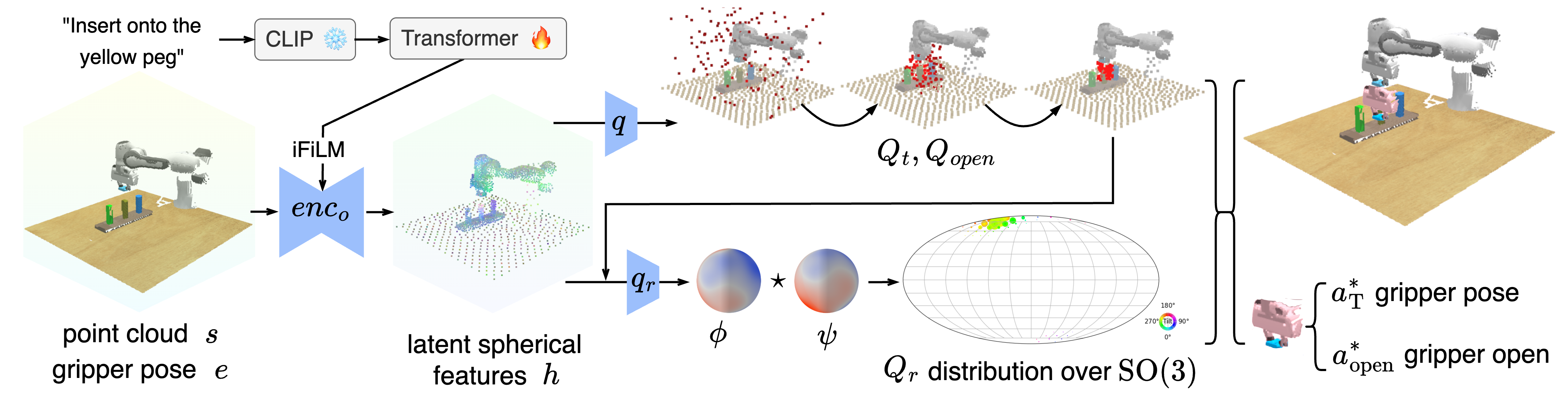
本文提出了一种名为EquAct的SE(3)等变多任务Transformer,用于从演示中学习语言条件下的多任务3D开放式机器人操作策略。该架构通过联合处理自然语言指令和3D观测来实现。尽管机器人策略和语言指令都蕴含丰富的3D几何结构,但标准Transformer缺乏内在的几何一致性保证,导致在场景的SE(3)变换下行为不可预测。EquAct利用SE(3)等变性作为策略和语言共享的关键结构属性,包含两个关键组件:(1)一个高效的基于点云的SE(3)等变U-net,使用球面傅里叶特征进行策略推理;(2)用于语言调节的SE(3)不变特征线性调制(iFiLM)层。在18个RLBench模拟任务(包括SE(3)和SE(2)场景扰动)和4个物理任务上评估了EquAct的空间泛化能力。实验结果表明,EquAct在这些模拟和物理任务中均达到了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决在开放式机器人操作任务中,标准Transformer模型缺乏对3D几何结构内在约束的问题。现有方法在处理具有SE(3)变换的场景时,由于不具备等变性,容易产生不可预测的行为,泛化能力较差。
核心思路:论文的核心思路是利用SE(3)等变性作为机器人策略和语言指令共享的关键结构属性。通过构建SE(3)等变的网络结构,保证模型在空间变换下输出结果的一致性,从而提高模型的泛化能力和鲁棒性。
技术框架:EquAct的整体架构是一个多任务Transformer,包含两个主要模块:(1) SE(3)等变点云U-net,用于处理3D点云观测,提取具有SE(3)等变性的特征;(2) SE(3)不变特征线性调制(iFiLM)层,用于将语言指令融入到视觉特征中,实现语言条件下的策略推理。整个流程是先通过U-net提取点云特征,然后使用iFiLM层进行语言调节,最后输出机器人动作。
关键创新:EquAct的关键创新在于其SE(3)等变性的设计。与标准Transformer相比,EquAct通过等变点云U-net和不变特征调制层,保证了模型在空间变换下的几何一致性。这种等变性使得模型能够更好地理解和处理3D场景,从而提高泛化能力。
关键设计:EquAct的关键设计包括:(1) 使用球面傅里叶特征来表示点云,从而实现SE(3)等变性;(2) 设计SE(3)不变的iFiLM层,用于将语言指令融入到视觉特征中;(3) 使用多任务学习框架,同时学习多个机器人操作任务,提高模型的泛化能力。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
EquAct在18个RLBench模拟任务和4个物理任务上进行了评估,结果表明其性能优于现有方法。在模拟任务中,EquAct在SE(3)和SE(2)场景扰动下均表现出更强的鲁棒性。在物理任务中,EquAct也取得了显著的性能提升,证明了其在真实环境中的有效性。
🎯 应用场景
EquAct的研究成果可应用于各种需要机器人进行复杂操作的场景,例如智能制造、家庭服务、医疗辅助等。通过提高机器人的空间泛化能力,可以使其更好地适应不同的环境和任务,从而实现更智能、更灵活的自动化。
📄 摘要(原文)
Transformer architectures can effectively learn language-conditioned, multi-task 3D open-loop manipulation policies from demonstrations by jointly processing natural language instructions and 3D observations. However, although both the robot policy and language instructions inherently encode rich 3D geometric structures, standard transformers lack built-in guarantees of geometric consistency, often resulting in unpredictable behavior under SE(3) transformations of the scene. In this paper, we leverage SE(3) equivariance as a key structural property shared by both policy and language, and propose EquAct-a novel SE(3)-equivariant multi-task transformer. EquAct is theoretically guaranteed to be SE(3) equivariant and consists of two key components: (1) an efficient SE(3)-equivariant point cloud-based U-net with spherical Fourier features for policy reasoning, and (2) SE(3)-invariant Feature-wise Linear Modulation (iFiLM) layers for language conditioning. To evaluate its spatial generalization ability, we benchmark EquAct on 18 RLBench simulation tasks with both SE(3) and SE(2) scene perturbations, and on 4 physical tasks. EquAct performs state-of-the-art across these simulation and physical tasks.