Object-Centric Action-Enhanced Representations for Robot Visuo-Motor Policy Learning
作者: Nikos Giannakakis, Argyris Manetas, Panagiotis P. Filntisis, Petros Maragos, George Retsinas
分类: cs.RO, cs.CV
发布日期: 2025-05-27
💡 一句话要点
提出基于对象中心和动作增强的视觉表示学习方法,用于提升机器人视觉运动策略学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人视觉 视觉运动策略学习 对象中心表示 语义分割 Slot Attention 领域外预训练 模仿学习
📋 核心要点
- 现有方法通常将语义分割和视觉表征生成视为独立过程,忽略了两者之间的内在联系。
- 论文提出一种对象中心的编码器,耦合语义分割和视觉表征生成,并利用Slot Attention机制。
- 实验表明,该方法能够增强强化学习和模仿学习的训练,并能有效利用领域外预训练模型。
📝 摘要(中文)
本文提出了一种对象中心的编码器,用于从观察到的动作中学习视觉表征,以促进机器人视觉运动策略的生成。该方法模拟人类的认知功能和感知,并受到人类以对象为基础处理场景的心理学理论的启发。与将语义分割和视觉表征生成视为独立过程的现有方法不同,本文提出的编码器以耦合的方式执行语义分割和视觉表征生成。该方法利用Slot Attention机制,并使用在大型领域外数据集上预训练的SOLV模型,在人类动作视频数据上进行微调。通过模拟机器人任务,实验结果表明,视觉表征可以增强强化学习和模仿学习的训练,突出了所提出的集成方法在语义分割和编码方面的有效性。此外,研究表明,利用在领域外数据集上预训练的模型可以使该过程受益,并且在描绘人类动作的数据集上进行微调可以显著提高性能,因为它与机器人任务密切相关。这些发现表明,该方法能够减少对带注释或特定于机器人的动作数据集的依赖,并具有利用现有视觉编码器来加速训练和提高泛化能力的潜力。
🔬 方法详解
问题定义:现有的机器人视觉运动策略学习方法通常将语义分割和视觉表征学习作为两个独立的任务进行处理,忽略了它们之间的内在联系。此外,依赖于大量标注数据或特定于机器人的数据集,限制了模型的泛化能力和应用范围。
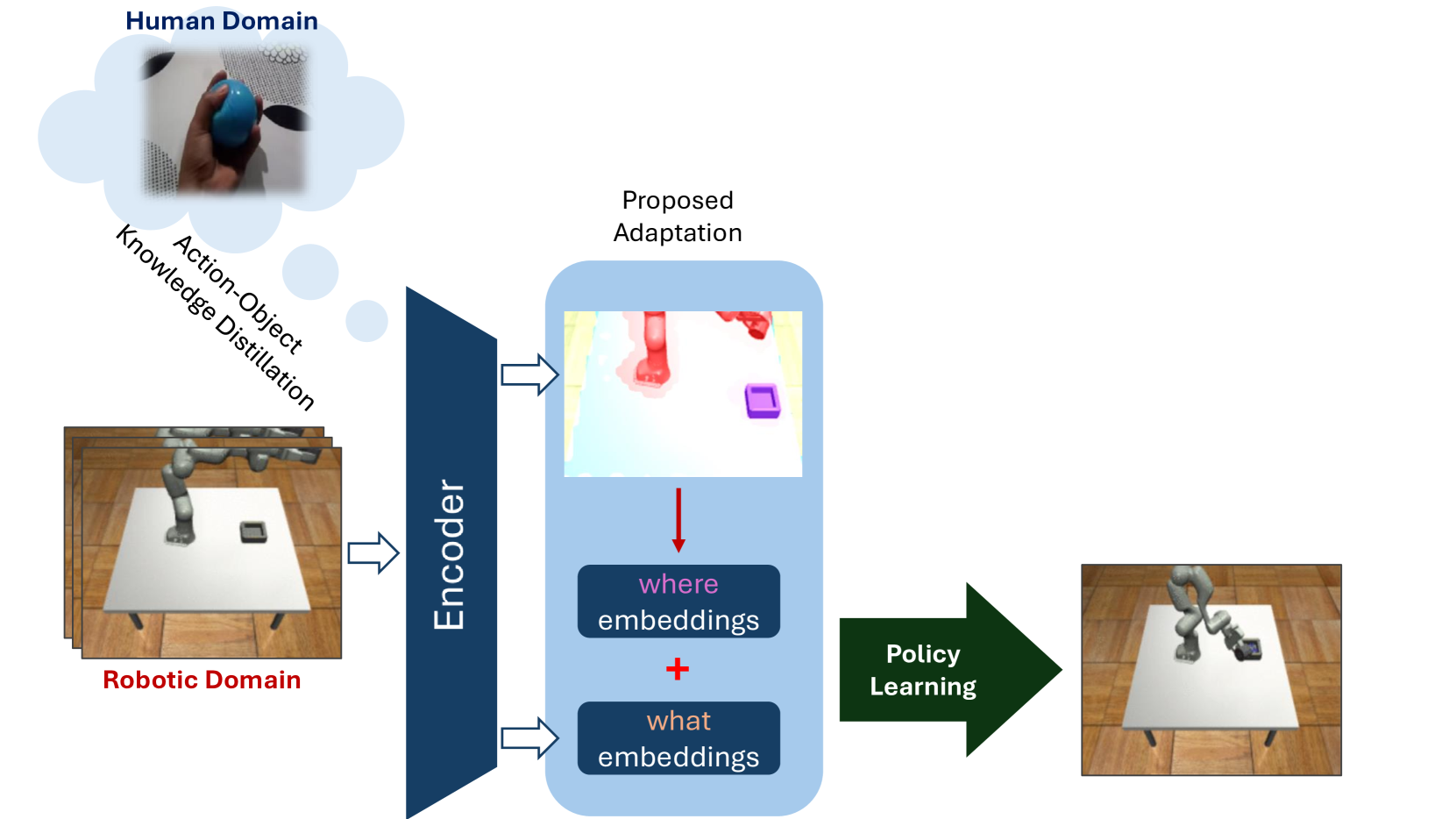
核心思路:论文的核心思路是将语义分割和视觉表征学习集成到一个统一的框架中,通过对象中心的方式进行处理。这种方法模仿了人类的认知过程,即以对象为基础来理解和处理场景。同时,利用在领域外数据集上预训练的模型,减少对特定领域数据的依赖。
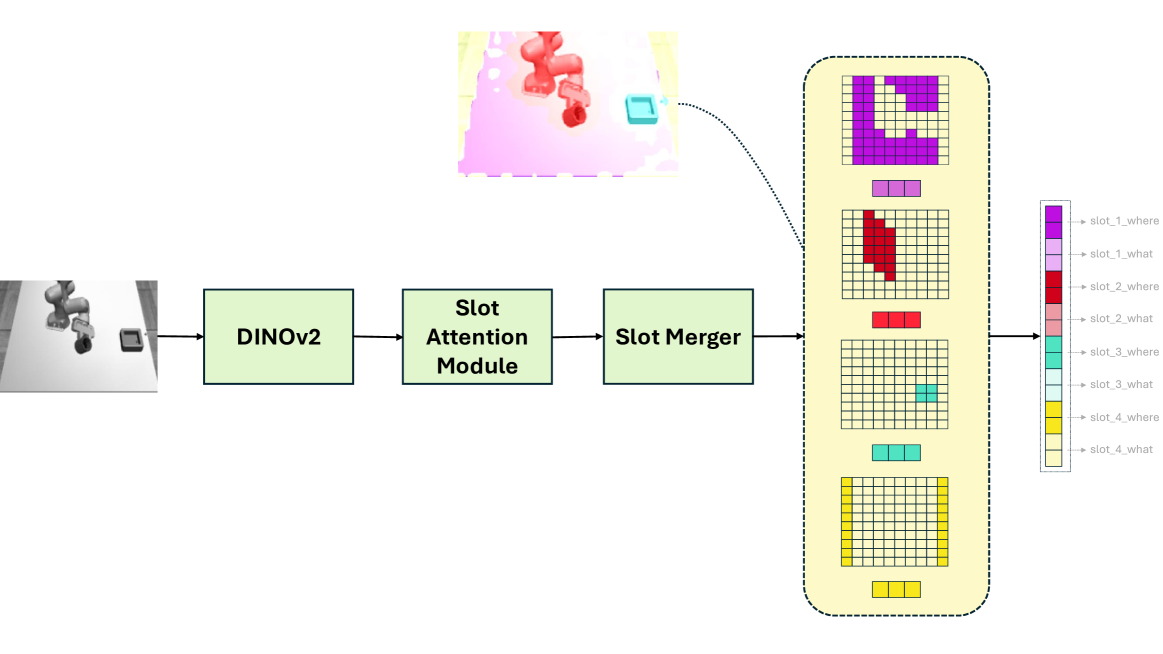
技术框架:整体框架包含一个对象中心的编码器,该编码器基于Slot Attention机制和SOLV模型。SOLV模型首先在大型领域外数据集上进行预训练,然后在人类动作视频数据上进行微调。编码器接收视觉输入,通过Slot Attention机制将场景分解为多个对象槽,并为每个对象槽生成相应的视觉表征。这些视觉表征可以用于后续的强化学习或模仿学习训练,以生成机器人视觉运动策略。
关键创新:最重要的技术创新点在于将语义分割和视觉表征学习集成到一个统一的框架中,并以对象中心的方式进行处理。与现有方法相比,该方法能够更好地捕捉场景中的对象信息,并生成更有效的视觉表征。此外,利用在领域外数据集上预训练的模型,减少了对特定领域数据的依赖,提高了模型的泛化能力。
关键设计:SOLV模型在ImageNet等大型数据集上进行预训练,以获得通用的视觉特征提取能力。Slot Attention机制用于将场景分解为多个对象槽,每个对象槽对应一个潜在的对象。损失函数包括语义分割损失和重构损失,用于约束编码器的学习过程。在人类动作视频数据上进行微调时,可以采用不同的微调策略,例如固定部分网络参数或全部参数进行微调。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的方法能够显著提高机器人视觉运动策略学习的性能。例如,在模拟的物体抓取任务中,使用该方法训练的机器人能够以更高的成功率抓取目标物体。此外,通过在人类动作视频数据上进行微调,可以进一步提高模型的性能,表明了利用领域外数据进行迁移学习的有效性。
🎯 应用场景
该研究成果可应用于各种机器人视觉运动控制任务,例如物体抓取、导航和操作。通过利用领域外数据和对象中心的表示学习方法,可以降低对特定领域数据的依赖,提高机器人的泛化能力和适应性。该方法还有潜力应用于自动驾驶、智能监控等领域。
📄 摘要(原文)
Learning visual representations from observing actions to benefit robot visuo-motor policy generation is a promising direction that closely resembles human cognitive function and perception. Motivated by this, and further inspired by psychological theories suggesting that humans process scenes in an object-based fashion, we propose an object-centric encoder that performs semantic segmentation and visual representation generation in a coupled manner, unlike other works, which treat these as separate processes. To achieve this, we leverage the Slot Attention mechanism and use the SOLV model, pretrained in large out-of-domain datasets, to bootstrap fine-tuning on human action video data. Through simulated robotic tasks, we demonstrate that visual representations can enhance reinforcement and imitation learning training, highlighting the effectiveness of our integrated approach for semantic segmentation and encoding. Furthermore, we show that exploiting models pretrained on out-of-domain datasets can benefit this process, and that fine-tuning on datasets depicting human actions -- although still out-of-domain -- , can significantly improve performance due to close alignment with robotic tasks. These findings show the capability to reduce reliance on annotated or robot-specific action datasets and the potential to build on existing visual encoders to accelerate training and improve generalizability.