Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation
作者: Peiyuan Zhi, Peiyang Li, Jianqin Yin, Baoxiong Jia, Siyuan Huang
分类: cs.RO
发布日期: 2025-05-27 (更新: 2025-10-04)
备注: website: https://unified-force.github.io/
💡 一句话要点
提出一种用于腿足机器人定位与力控的统一策略,无需力传感器。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿足机器人 力控制 位置控制 强化学习 统一策略 无力传感器 模仿学习
📋 核心要点
- 现有腿足机器人操作策略通常只关注位置或力控制,忽略了二者的联合学习,限制了其在复杂环境中的应用。
- 提出一种统一策略,通过强化学习联合建模力和位置控制,从历史状态估计力并进行补偿,无需力传感器。
- 实验表明,该策略在多种任务中表现出良好的通用性和鲁棒性,并能显著提升模仿学习的成功率。
📝 摘要(中文)
本文提出了一种用于腿足机器人的统一策略,该策略能够联合建模力和位置控制,且无需依赖力传感器。通过模拟各种位置和力指令以及外部扰动力的组合,我们使用强化学习训练策略,使其能够从历史机器人状态中估计力,并通过调整位置和速度来补偿这些力。该策略支持各种操作行为,包括位置跟踪、力施加、力跟踪和柔顺交互。此外,我们证明了所学习的策略通过其力估计模块整合了关键的接触信息,从而增强了基于轨迹的模仿学习流程,在四个具有挑战性的接触操作任务中,成功率比仅使用位置控制的策略高出约39.5%。在四足操作机器人和人形机器人上的大量实验验证了该策略在各种场景中的通用性和鲁棒性。
🔬 方法详解
问题定义:腿足机器人操作任务通常涉及与环境的接触交互,需要同时控制机器人的位置和作用力。然而,现有的视觉运动策略通常只关注位置控制或力控制,忽略了二者的联合建模,导致在复杂接触场景下的性能受限。缺乏力传感器也增加了精确力控制的难度。
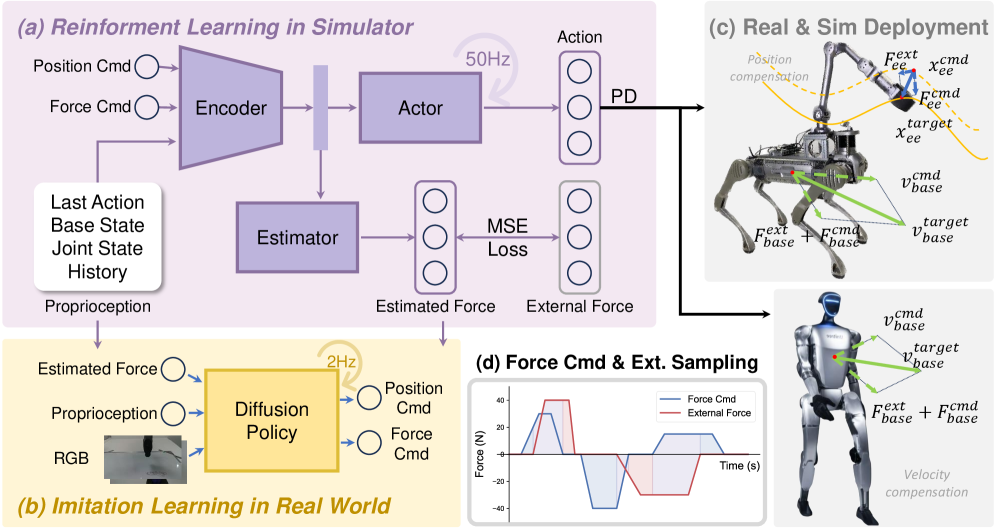
核心思路:本文的核心思路是利用强化学习,训练一个统一的策略,该策略能够从历史机器人状态中估计作用在机器人上的力,并通过调整机器人的位置和速度来补偿这些力。通过模拟各种位置和力指令以及外部扰动力的组合,使策略能够学习到力与状态之间的映射关系,从而实现无需力传感器的力控制。
技术框架:该方法采用强化学习框架,训练一个策略网络。该网络以历史机器人状态(包括位置、速度等)作为输入,输出机器人的位置和速度调整量。在训练过程中,模拟器会施加各种位置和力指令以及外部扰动。策略网络通过学习,逐渐掌握从历史状态估计力并进行补偿的能力。该框架包含环境模拟器、策略网络和强化学习算法三个主要模块。
关键创新:该方法最重要的创新点在于提出了一个统一的策略,能够同时进行位置和力控制,并且无需依赖力传感器。通过强化学习,策略能够学习到力与状态之间的复杂关系,从而实现精确的力控制。此外,该策略还可以作为力估计模块,增强现有的模仿学习流程。
关键设计:策略网络采用多层感知机(MLP)结构,输入为历史机器人状态,输出为位置和速度调整量。损失函数包括位置跟踪误差、力跟踪误差和动作惩罚项。强化学习算法采用近端策略优化(PPO)。在模拟器中,需要精心设计各种位置和力指令以及外部扰动,以保证策略能够学习到鲁棒的力控制能力。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
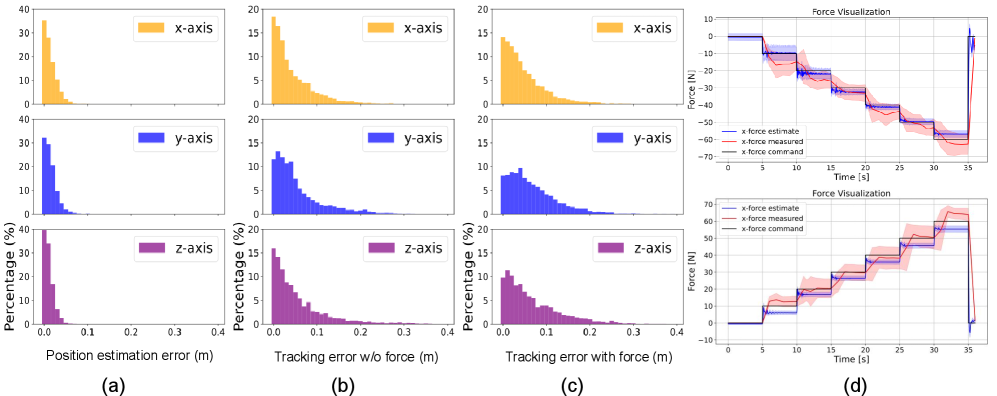
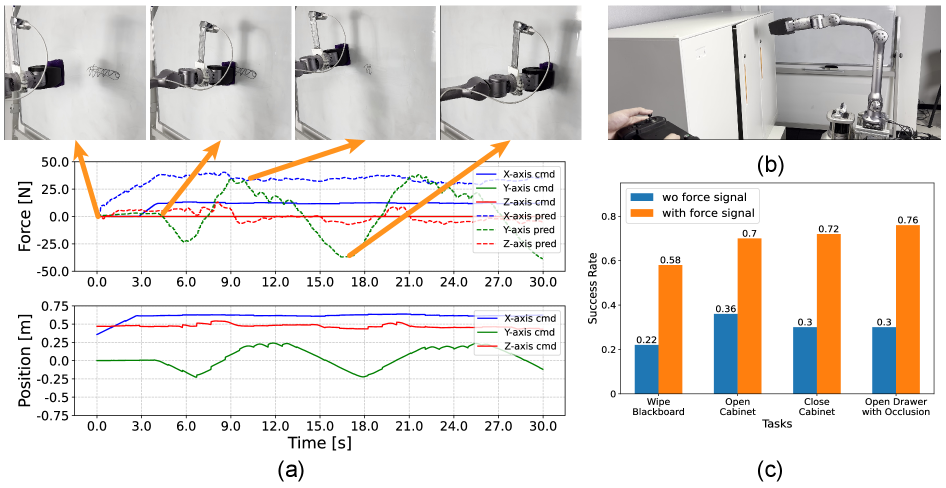
实验结果表明,该策略在四足机器人和人形机器人上都表现出良好的通用性和鲁棒性。在四个具有挑战性的接触操作任务中,该策略增强的模仿学习流程的成功率比仅使用位置控制的策略高出约39.5%。这些结果验证了该策略在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于各种需要腿足机器人进行精细操作的场景,例如:灾难救援、工业制造、医疗康复等。通过精确的力和位置控制,机器人可以完成更加复杂和精细的任务,例如:在复杂地形上搬运重物、进行装配操作、辅助病人进行康复训练等。该研究还有助于推动腿足机器人在未知和动态环境中的应用。
📄 摘要(原文)
Robotic loco-manipulation tasks often involve contact-rich interactions with the environment, requiring the joint modeling of contact force and robot position. However, recent visuomotor policies often focus solely on learning position or force control, overlooking their co-learning. In this work, we propose the first unified policy for legged robots that jointly models force and position control learned without reliance on force sensors. By simulating diverse combinations of position and force commands alongside external disturbance forces, we use reinforcement learning to learn a policy that estimates forces from historical robot states and compensates for them through position and velocity adjustments. This policy enables a wide range of manipulation behaviors under varying force and position inputs, including position tracking, force application, force tracking, and compliant interactions. Furthermore, we demonstrate that the learned policy enhances trajectory-based imitation learning pipelines by incorporating essential contact information through its force estimation module, achieving approximately 39.5% higher success rates across four challenging contact-rich manipulation tasks compared to position-control policies. Extensive experiments on both a quadrupedal manipulator and a humanoid robot validate the versatility and robustness of the proposed policy across diverse scenarios.