GET: Goal-directed Exploration and Targeting for Large-Scale Unknown Environments
作者: Lanxiang Zheng, Ruidong Mei, Mingxin Wei, Hao Ren, Hui Cheng
分类: cs.RO
发布日期: 2025-05-27 (更新: 2025-05-28)
💡 一句话要点
GET:面向大规模未知环境的目标导向探索与定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 目标导向探索 大型语言模型 具身智能 概率任务图 机器人导航 物体搜索 自主探索
📋 核心要点
- 现有方法在复杂环境中进行物体搜索时,缺乏有效的空间推理和经验利用机制,导致效率低下。
- GET框架结合LLM推理和经验引导探索,通过DoUT模块实现实时决策,并利用概率任务图更新物体位置先验。
- 实验表明,GET显著提高了搜索效率和鲁棒性,优于传统方法和仅使用LLM的方案,证明了其有效性。
📝 摘要(中文)
在大规模、非结构化环境中进行物体搜索是机器人领域的一项基本挑战,尤其是在动态或广阔的环境(如户外自主探索)中。这项任务需要强大的空间推理能力和利用先验经验的能力。大型语言模型(LLM)虽然具有强大的语义能力,但由于在空间推理方面的基础不足以及缺乏记忆整合和决策一致性的机制,其在具身环境中的应用受到限制。为了解决这些挑战,我们提出了GET(目标导向探索与定位)框架,该框架通过结合基于LLM的推理和经验引导的探索来增强物体搜索能力。其核心是DoUT(统一思想图),这是一个推理模块,通过基于角色的反馈循环,整合特定任务的标准和外部记忆,从而促进实时决策。对于重复性任务,GET维护一个基于高斯混合模型的概率任务图,允许随着环境的演变不断更新物体位置的先验知识。在真实、大规模环境中进行的实验表明,GET提高了跨多个LLM和任务设置的搜索效率和鲁棒性,显著优于启发式和仅使用LLM的基线。这些结果表明,结构化的LLM集成提供了一种可扩展且通用的方法,用于在复杂环境中进行具身决策。
🔬 方法详解
问题定义:论文旨在解决大规模未知环境中机器人进行目标物体搜索的问题。现有方法,特别是仅依赖LLM的方法,在空间推理、记忆整合和决策一致性方面存在不足,导致搜索效率低下,难以适应动态环境。传统启发式方法缺乏语义理解能力,难以处理复杂任务。
核心思路:论文的核心思路是将LLM的语义理解能力与经验引导的探索相结合,利用LLM进行高级推理和决策,同时通过概率任务图来整合历史经验,指导未来的搜索过程。这种结合使得机器人能够更好地理解任务目标,并根据环境变化调整搜索策略。
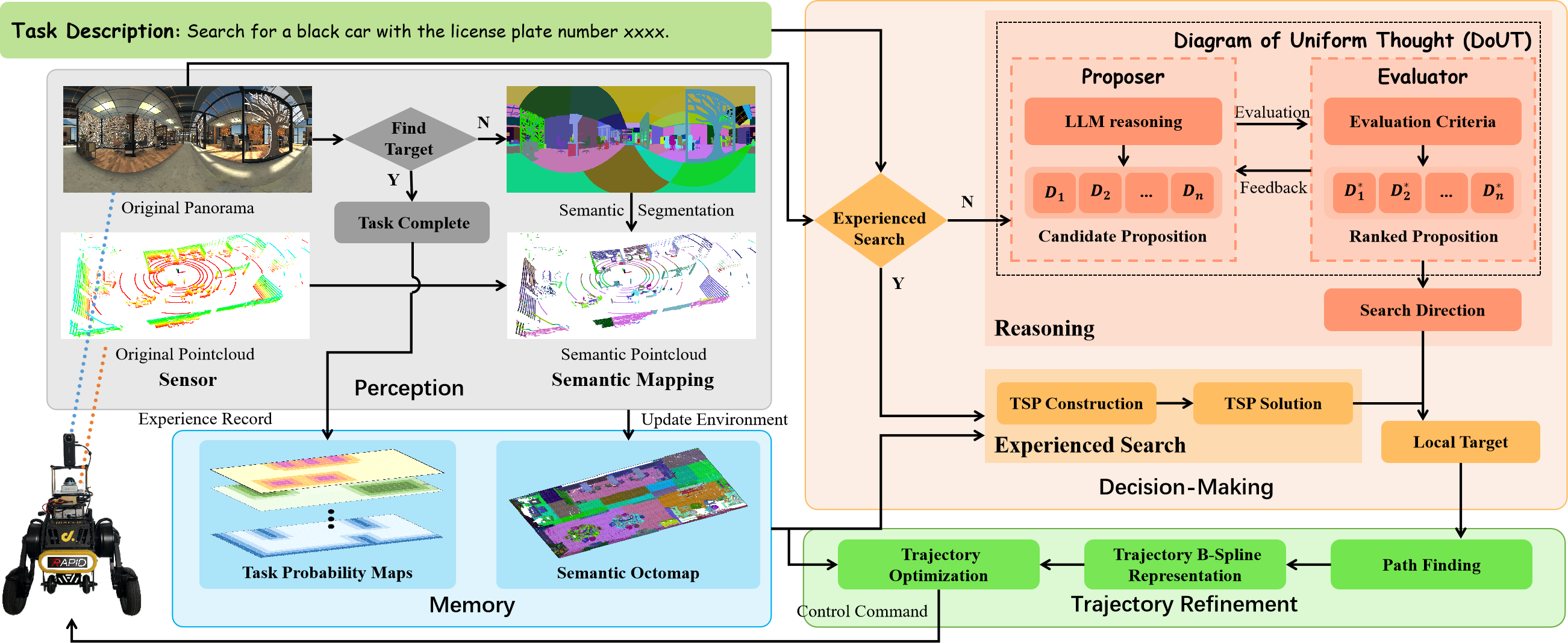
技术框架:GET框架包含以下主要模块:1) DoUT (Diagram of Unified Thought):一个基于角色的反馈循环推理模块,整合任务特定标准和外部记忆,用于实时决策。2) 概率任务图:基于高斯混合模型,用于维护和更新物体位置的先验知识。3) 探索策略:结合LLM推理和概率任务图,指导机器人在环境中进行高效探索。整体流程是,首先利用LLM理解任务目标,然后DoUT模块根据当前环境信息和历史经验进行决策,指导机器人进行探索,同时更新概率任务图。
关键创新:该论文的关键创新在于DoUT模块的设计,它通过角色扮演和反馈循环,实现了LLM在具身环境中的有效应用。此外,概率任务图的引入使得机器人能够持续学习和适应环境变化,提高了搜索的鲁棒性和效率。将LLM与概率模型相结合,弥补了LLM在空间推理方面的不足。
关键设计:DoUT模块的关键设计包括角色定义(例如,探索者、目标定位者)、角色间的通信机制以及反馈循环的实现方式。概率任务图的关键设计包括高斯混合模型的参数选择、更新策略以及如何将概率信息融入到探索策略中。论文中可能还涉及LLM的选择和prompt工程,以确保LLM能够有效地理解任务目标并生成合理的行动指令。具体的损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GET框架在真实大规模环境中显著优于启发式和仅使用LLM的基线方法。具体性能数据未知,但摘要强调了GET在搜索效率和鲁棒性方面的提升,以及在多个LLM和任务设置下的通用性。该框架成功地将LLM的语义理解能力与经验引导的探索相结合,实现了更高效的物体搜索。
🎯 应用场景
该研究成果可应用于各种需要自主物体搜索的场景,例如:搜救行动、仓库管理、家庭服务机器人、以及户外自主探索等。通过提高搜索效率和鲁棒性,可以显著降低人力成本,提高工作效率,并扩展机器人的应用范围。未来,该技术有望应用于更复杂的环境和任务,例如:灾后救援和行星探索。
📄 摘要(原文)
Object search in large-scale, unstructured environments remains a fundamental challenge in robotics, particularly in dynamic or expansive settings such as outdoor autonomous exploration. This task requires robust spatial reasoning and the ability to leverage prior experiences. While Large Language Models (LLMs) offer strong semantic capabilities, their application in embodied contexts is limited by a grounding gap in spatial reasoning and insufficient mechanisms for memory integration and decision consistency.To address these challenges, we propose GET (Goal-directed Exploration and Targeting), a framework that enhances object search by combining LLM-based reasoning with experience-guided exploration. At its core is DoUT (Diagram of Unified Thought), a reasoning module that facilitates real-time decision-making through a role-based feedback loop, integrating task-specific criteria and external memory. For repeated tasks, GET maintains a probabilistic task map based on a Gaussian Mixture Model, allowing for continual updates to object-location priors as environments evolve.Experiments conducted in real-world, large-scale environments demonstrate that GET improves search efficiency and robustness across multiple LLMs and task settings, significantly outperforming heuristic and LLM-only baselines. These results suggest that structured LLM integration provides a scalable and generalizable approach to embodied decision-making in complex environments.