Learning Generalizable Robot Policy with Human Demonstration Video as a Prompt
作者: Xiang Zhu, Yichen Liu, Hezhong Li, Jianyu Chen
分类: cs.RO
发布日期: 2025-05-27
💡 一句话要点
提出一种基于人类演示视频提示的通用机器人策略学习框架,无需额外数据和模型微调。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 模仿学习 人类演示 视频提示 通用策略 原型对比学习 跨模态学习
📋 核心要点
- 现有机器人学习方法依赖于大量遥操作数据,新任务通常需要重新收集数据和微调策略,成本高昂。
- 该论文提出一种两阶段框架,利用人类演示视频作为提示,学习通用机器人策略,无需额外数据和微调。
- 实验结果表明,该方法在真实灵巧操作任务中表现出良好的有效性和泛化能力。
📝 摘要(中文)
本文提出了一种新颖的两阶段框架,利用人类演示视频学习通用的机器人策略。该策略可以直接将人类演示视频作为提示,执行新任务,而无需任何新的遥操作数据和模型微调。第一阶段,我们训练一个视频生成模型,通过交叉预测捕获人类和机器人演示视频数据的联合表示。第二阶段,我们使用一种新颖的原型对比损失,将学习到的表示与人类和机器人之间的共享动作空间融合。在真实灵巧操作任务上的实验评估表明了我们提出的方法的有效性和泛化能力。
🔬 方法详解
问题定义:现有机器人学习方法依赖于大量机器人遥操作数据,针对新任务需要重新收集数据并进行模型微调,数据收集过程繁琐且成本高昂。因此,如何利用人类演示视频,使机器人能够像人类一样快速学习新任务,是一个亟待解决的问题。
核心思路:该论文的核心思路是利用人类演示视频作为机器人学习的“提示”,通过学习人类和机器人视频之间的共享表示,将人类的动作知识迁移到机器人上。这样,机器人就可以直接根据人类的演示视频执行新任务,而无需额外的机器人数据和模型微调。
技术框架:该框架包含两个主要阶段:1) 视频生成模型训练阶段:使用交叉预测方法,训练一个视频生成模型,该模型能够学习人类和机器人演示视频数据的联合表示。具体来说,该模型可以根据人类视频预测对应的机器人视频,反之亦然。2) 策略学习阶段:利用学习到的联合表示,结合人类和机器人之间的共享动作空间,使用原型对比损失函数训练机器人策略。该损失函数旨在拉近同一动作的原型表示,推远不同动作的原型表示。
关键创新:该论文的关键创新在于:1) 提出了一种利用人类演示视频作为机器人学习提示的新思路,避免了对大量机器人数据的依赖。2) 设计了一种基于交叉预测的视频生成模型,能够有效学习人类和机器人视频数据的联合表示。3) 提出了一种新颖的原型对比损失函数,能够有效融合学习到的表示和共享动作空间。
关键设计:在视频生成模型中,使用了Transformer架构来建模视频序列的时序关系。原型对比损失函数的设计中,首先为每个动作类别计算一个原型向量,然后使用对比学习的目标,拉近同一动作的原型向量和样本表示,推远不同动作的原型向量和样本表示。具体损失函数形式未知,需要查阅论文。
🖼️ 关键图片
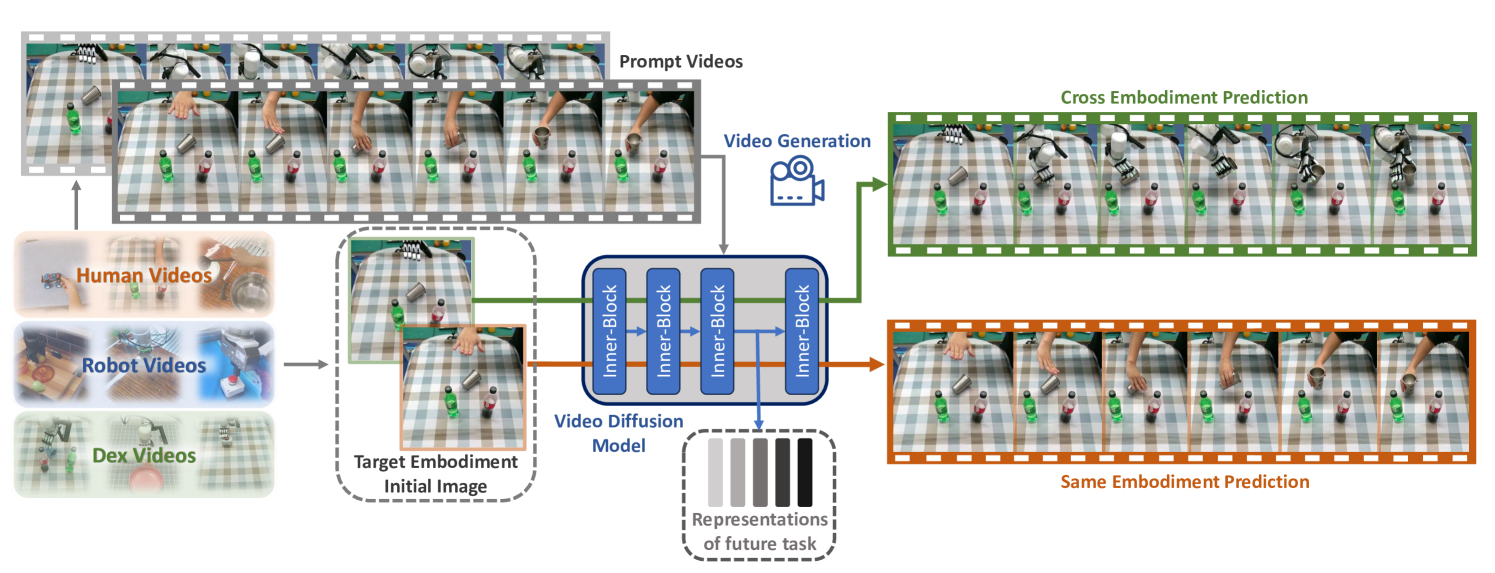


📊 实验亮点
论文在真实灵巧操作任务上进行了实验,结果表明,该方法能够有效地利用人类演示视频学习机器人策略,并在新任务上表现出良好的泛化能力。具体的性能数据和对比基线未知,需要查阅论文。
🎯 应用场景
该研究具有广泛的应用前景,例如:1) 快速部署新机器人任务,无需人工遥操作数据收集;2) 降低机器人学习成本,利用互联网上丰富的视频资源;3) 实现更智能的人机协作,机器人可以根据人类的演示进行学习和模仿。未来,该技术可以应用于工业自动化、家庭服务、医疗康复等领域。
📄 摘要(原文)
Recent robot learning methods commonly rely on imitation learning from massive robotic dataset collected with teleoperation. When facing a new task, such methods generally require collecting a set of new teleoperation data and finetuning the policy. Furthermore, the teleoperation data collection pipeline is also tedious and expensive. Instead, human is able to efficiently learn new tasks by just watching others do. In this paper, we introduce a novel two-stage framework that utilizes human demonstrations to learn a generalizable robot policy. Such policy can directly take human demonstration video as a prompt and perform new tasks without any new teleoperation data and model finetuning at all. In the first stage, we train video generation model that captures a joint representation for both the human and robot demonstration video data using cross-prediction. In the second stage, we fuse the learned representation with a shared action space between human and robot using a novel prototypical contrastive loss. Empirical evaluations on real-world dexterous manipulation tasks show the effectiveness and generalization capabilities of our proposed method.