Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion
作者: Tianhu Peng, Lingfan Bao, Chengxu Zhou
分类: cs.RO
发布日期: 2025-05-27 (更新: 2025-09-15)
💡 一句话要点
提出步态条件强化学习框架,实现人型机器人站立、行走、跑步及平滑过渡。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人型机器人 强化学习 步态控制 多步态学习 奖励路由 课程学习 运动控制
📋 核心要点
- 现有方法难以在单一策略下实现人型机器人多种步态的平滑切换,存在奖励干扰和学习不稳定的问题。
- 论文提出步态条件强化学习框架,通过奖励路由机制和人类启发式奖励,实现多步态控制和自然运动。
- 实验表明,该方法在仿真和真实机器人上均能实现站立、行走、跑步和步态过渡,验证了其有效性。
📝 摘要(中文)
本文提出了一种统一的步态条件强化学习框架,使人型机器人能够在单个循环策略中执行站立、行走、跑步以及平滑过渡。紧凑的奖励路由机制基于one-hot步态ID动态激活特定于步态的目标,从而减轻奖励干扰并支持稳定的多步态学习。受人类启发设计的奖励项促进了生物力学上自然的运动,例如直膝站立和协调的手臂-腿部摆动,而无需运动捕捉数据。结构化的课程逐步引入步态复杂性,并在多个阶段扩展命令空间。在仿真中,该策略成功实现了稳健的站立、行走、跑步和步态过渡。在真实的Unitree G1人型机器人上,验证了站立、行走和行走-站立过渡,证明了稳定和协调的运动。这项工作为跨不同模式和环境的通用和自然的人型控制提供了一个可扩展的、无需参考数据的解决方案。
🔬 方法详解
问题定义:现有的人型机器人控制方法通常针对单一运动模式进行优化,难以实现多种步态之间的平滑过渡。此外,不同步态的奖励函数之间存在干扰,导致多步态学习不稳定。缺乏对人类运动特征的有效建模,使得机器人运动不够自然。
核心思路:论文的核心思路是利用步态条件强化学习,通过一个统一的策略来控制多种步态。通过奖励路由机制,根据当前步态动态调整奖励函数,避免奖励干扰。同时,引入人类启发式奖励,鼓励机器人学习更自然的运动方式。
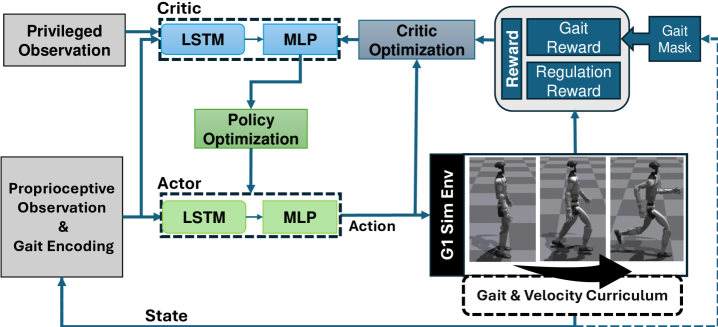
技术框架:该框架包含以下主要模块:1) 步态条件策略网络,输入包括机器人状态和步态ID,输出为关节力矩;2) 奖励路由机制,根据步态ID选择相应的奖励函数;3) 人类启发式奖励,包括直膝站立和协调的手臂-腿部摆动等;4) 多阶段课程学习,逐步增加步态复杂度和命令空间。
关键创新:该方法的主要创新点在于:1) 提出了步态条件强化学习框架,实现了多步态的统一控制;2) 设计了奖励路由机制,有效避免了奖励干扰;3) 引入了人类启发式奖励,无需运动捕捉数据即可实现自然的运动。
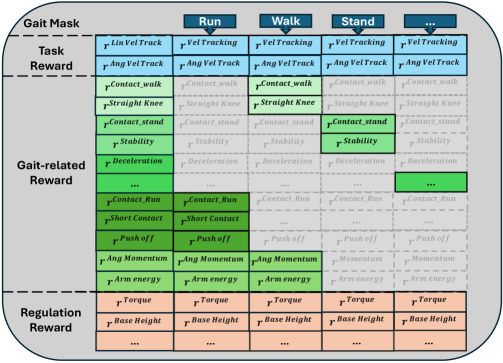
关键设计:奖励路由机制使用one-hot步态ID作为输入,动态激活特定步态的奖励函数。人类启发式奖励包括直膝站立奖励(鼓励站立时膝盖伸直)和协调的手臂-腿部摆动奖励(鼓励手臂和腿部协调运动)。课程学习分为多个阶段,逐步增加步态的复杂度和命令空间,例如从站立到行走,再到跑步和步态过渡。
🖼️ 关键图片
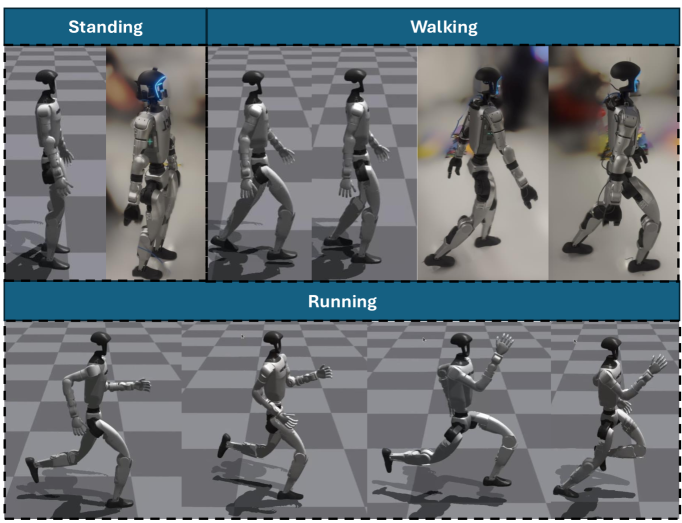
📊 实验亮点
在仿真环境中,该策略成功实现了稳健的站立、行走、跑步和步态过渡。在真实的Unitree G1人型机器人上,验证了站立、行走和行走-站立过渡,证明了稳定和协调的运动。实验结果表明,该方法能够有效地控制人型机器人执行多种步态,并实现自然的运动。
🎯 应用场景
该研究成果可应用于各种人型机器人应用场景,例如搜救、物流、康复等。通过实现多种步态的平滑切换和自然运动,可以提高机器人在复杂环境中的适应性和工作效率。未来,该方法可以进一步扩展到更多类型的运动和环境,实现更通用的人型机器人控制。
📄 摘要(原文)
We present a unified gait-conditioned reinforcement learning framework that enables humanoid robots to perform standing, walking, running, and smooth transitions within a single recurrent policy. A compact reward routing mechanism dynamically activates gait-specific objectives based on a one-hot gait ID, mitigating reward interference and supporting stable multi-gait learning. Human-inspired reward terms promote biomechanically natural motions, such as straight-knee stance and coordinated arm-leg swing, without requiring motion capture data. A structured curriculum progressively introduces gait complexity and expands command space over multiple phases. In simulation, the policy successfully achieves robust standing, walking, running, and gait transitions. On the real Unitree G1 humanoid, we validate standing, walking, and walk-to-stand transitions, demonstrating stable and coordinated locomotion. This work provides a scalable, reference-free solution toward versatile and naturalistic humanoid control across diverse modes and environments.