OSVI-WM: One-Shot Visual Imitation for Unseen Tasks using World-Model-Guided Trajectory Generation
作者: Raktim Gautam Goswami, Prashanth Krishnamurthy, Yann LeCun, Farshad Khorrami
分类: cs.RO
发布日期: 2025-05-26 (更新: 2025-12-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于世界模型的单样本视觉模仿学习框架,解决未见任务泛化问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉模仿学习 单样本学习 世界模型 轨迹生成 机器人学习
📋 核心要点
- 现有单样本视觉模仿学习方法难以泛化到具有不同语义或结构要求的未见任务,泛化能力受限。
- 该方法利用学习到的世界模型预测潜在状态和动作序列,生成轨迹引导智能体执行,提升泛化性。
- 在模拟和真实机器人实验中,该方法显著优于现有方法,在某些情况下性能提升超过30%。
📝 摘要(中文)
本文提出了一种新颖的基于世界模型引导轨迹生成的单样本视觉模仿学习框架,旨在解决现有方法在未见任务上的泛化能力不足的问题。现有方法通常在同一任务集上训练和评估,仅改变对象配置,难以泛化到具有不同语义或结构要求的未见任务。此外,大多数方法缺乏对环境动态的显式建模,限制了对未来状态的推理能力。该方法利用学习到的世界模型预测潜在状态和动作序列,然后将该潜在轨迹解码为物理路标点,指导智能体的执行。在两个模拟基准和三个真实机器人平台上进行的评估表明,该方法始终优于现有方法,在某些情况下性能提升超过30%。
🔬 方法详解
问题定义:现有单样本视觉模仿学习方法在面对未见过的任务时,泛化能力较差。它们通常在同一组任务上进行训练和测试,仅仅改变物体的配置,而当任务的语义或结构发生变化时,性能会显著下降。此外,许多方法缺乏对环境动态的建模,无法有效地预测和推理未来的状态,从而影响模仿学习的效果。
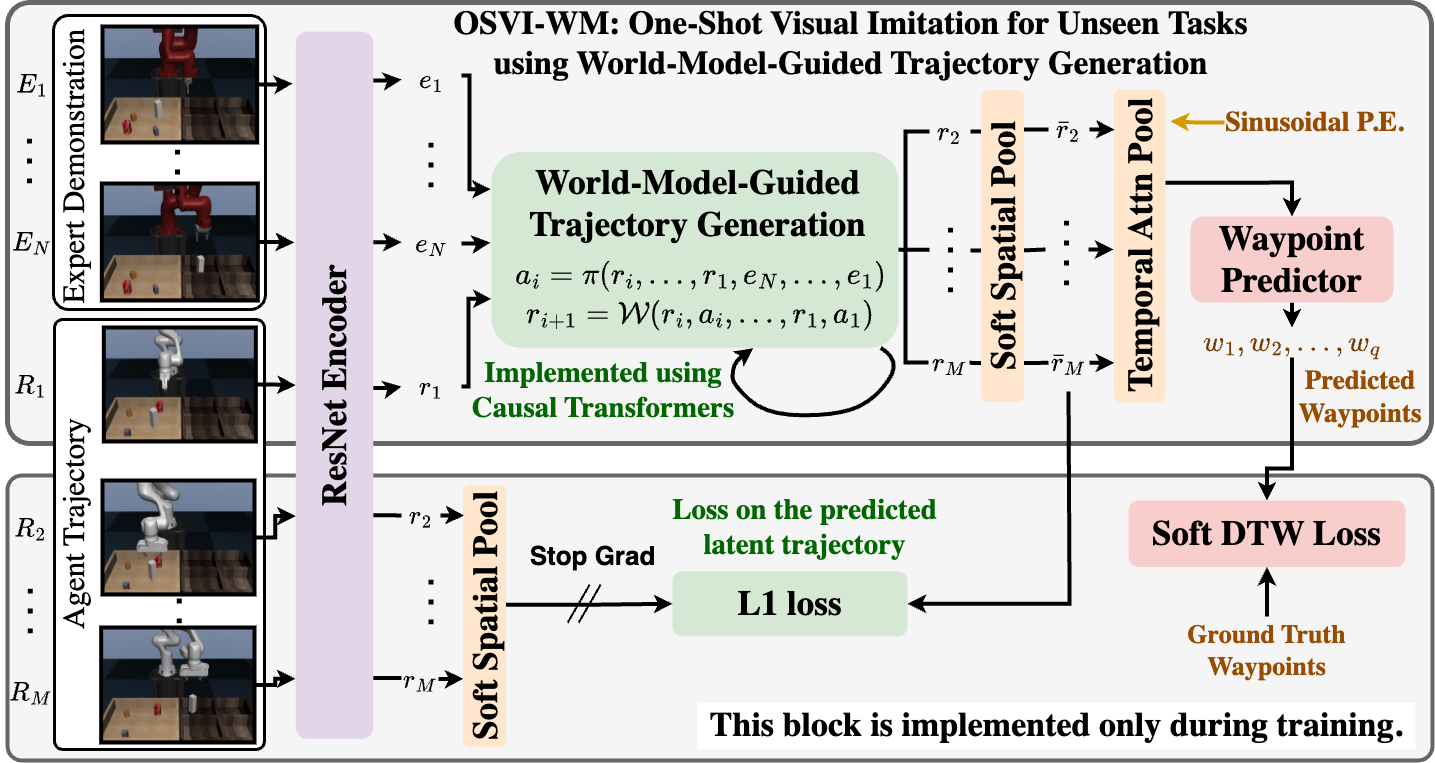
核心思路:该论文的核心思路是利用世界模型来指导轨迹生成,从而提高单样本视觉模仿学习在未见任务上的泛化能力。世界模型能够学习环境的动态特性,从而预测未来状态,并生成更合理的轨迹。通过将专家演示视频和智能体的初始观察作为输入,世界模型可以预测一系列潜在状态和动作,这些潜在状态和动作随后被解码为物理路标点,引导智能体执行任务。
技术框架:该框架包含以下主要模块:1) 世界模型:学习环境的动态特性,能够根据当前状态和动作预测未来状态。2) 轨迹生成器:利用世界模型预测潜在状态和动作序列,生成潜在轨迹。3) 轨迹解码器:将潜在轨迹解码为物理路标点,用于指导智能体的运动。整个流程是,给定专家演示视频和智能体的初始观察,世界模型预测潜在状态和动作序列,轨迹解码器将这些潜在状态和动作解码为物理路标点,智能体根据这些路标点执行任务。
关键创新:该论文的关键创新在于将世界模型引入到单样本视觉模仿学习中,利用世界模型来指导轨迹生成。与现有方法相比,该方法能够更好地建模环境的动态特性,从而提高在未见任务上的泛化能力。此外,该方法通过预测潜在状态和动作序列,实现了对未来状态的推理,从而能够生成更合理的轨迹。
关键设计:世界模型的具体结构未知,论文中未详细描述。轨迹生成器和解码器的具体实现细节也未知。损失函数的设计也未明确说明,但推测可能包含模仿学习损失和世界模型预测损失。具体的参数设置未知。
🖼️ 关键图片


📊 实验亮点
该方法在两个模拟基准和三个真实机器人平台上进行了评估,实验结果表明,该方法始终优于现有方法,在某些情况下性能提升超过30%。这表明该方法在提高单样本视觉模仿学习的泛化能力方面具有显著优势。具体的性能指标和对比基线未知。
🎯 应用场景
该研究成果可应用于各种需要机器人进行视觉模仿学习的场景,例如家庭服务机器人、工业自动化机器人等。通过观察人类专家的演示,机器人可以快速学习新的技能,从而提高其适应性和灵活性。该方法在医疗、仓储、农业等领域具有广泛的应用前景,可以帮助机器人完成各种复杂任务。
📄 摘要(原文)
Visual imitation learning enables robotic agents to acquire skills by observing expert demonstration videos. In the one-shot setting, the agent generates a policy after observing a single expert demonstration without additional fine-tuning. Existing approaches typically train and evaluate on the same set of tasks, varying only object configurations, and struggle to generalize to unseen tasks with different semantic or structural requirements. While some recent methods attempt to address this, they exhibit low success rates on hard test tasks that, despite being visually similar to some training tasks, differ in context and require distinct responses. Additionally, most existing methods lack an explicit model of environment dynamics, limiting their ability to reason about future states. To address these limitations, we propose a novel framework for one-shot visual imitation learning via world-model-guided trajectory generation. Given an expert demonstration video and the agent's initial observation, our method leverages a learned world model to predict a sequence of latent states and actions. This latent trajectory is then decoded into physical waypoints that guide the agent's execution. Our method is evaluated on two simulated benchmarks and three real-world robotic platforms, where it consistently outperforms prior approaches, with over 30% improvement in some cases. The code is available at https://github.com/raktimgg/osvi-wm.