RFTF: Reinforcement Fine-tuning for Embodied Agents with Temporal Feedback
作者: Junyang Shu, Zhiwei Lin, Yongtao Wang
分类: cs.RO
发布日期: 2025-05-26
💡 一句话要点
提出RFTF:一种基于时序反馈的强化微调方法,提升具身智能体性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 强化学习 强化微调 密集奖励 价值模型
📋 核心要点
- 现有具身智能体训练依赖行为克隆,存在数据需求高、计算资源消耗大和泛化能力受限等问题。
- RFTF利用价值模型生成密集奖励,价值模型通过时序信息训练,无需人工标注,提供细粒度反馈。
- 实验表明,RFTF在CALVIN ABC-D数据集上取得SOTA性能,平均成功长度达到4.296,并能快速适应新环境。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在具身智能领域展现出巨大潜力,使智能体能够遵循人类指令在物理环境中完成复杂任务。现有的具身智能体通常通过行为克隆进行训练,这需要昂贵的数据和计算资源,并受到人类演示的限制。为了解决这个问题,许多研究人员探索将强化微调应用于具身智能体。然而,典型的强化微调方法通常依赖于稀疏的、基于结果的奖励,这难以提供对episode中特定动作的细粒度反馈,从而限制了模型的操纵能力和泛化性能。本文提出RFTF,一种新颖的强化微调方法,利用价值模型在具身场景中生成密集奖励。具体来说,我们的价值模型使用时序信息进行训练,无需昂贵的机器人动作标签。此外,RFTF还结合了一系列技术,如GAE和样本平衡,以提高微调过程的有效性。通过解决强化微调中的稀疏奖励问题,我们的方法显著提高了具身智能体的性能,在各种具身任务中提供了卓越的泛化和适应能力。实验结果表明,使用RFTF进行微调的具身智能体在具有挑战性的CALVIN ABC-D上实现了新的state-of-the-art性能,平均成功长度为4.296。此外,RFTF能够快速适应新环境。在CALVIN的D环境中进行少量episode的微调后,RFTF在这个新环境中实现了4.301的平均成功长度。
🔬 方法详解
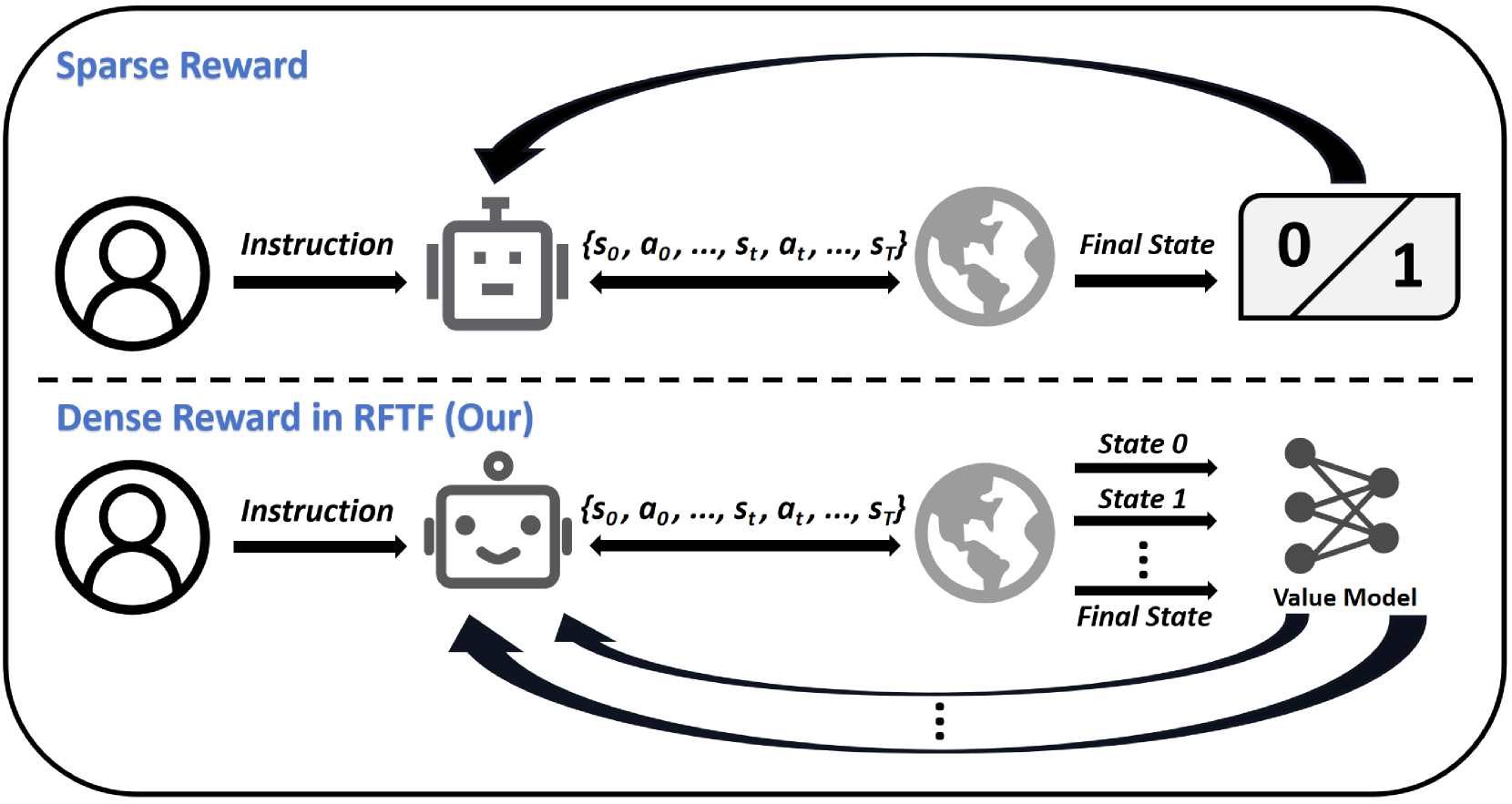
问题定义:现有具身智能体的强化微调方法面临稀疏奖励问题,即奖励信号不足以指导智能体学习精细的动作控制,导致泛化能力受限。现有方法依赖于人工设计的稀疏奖励,难以提供episode中每个动作的有效反馈。
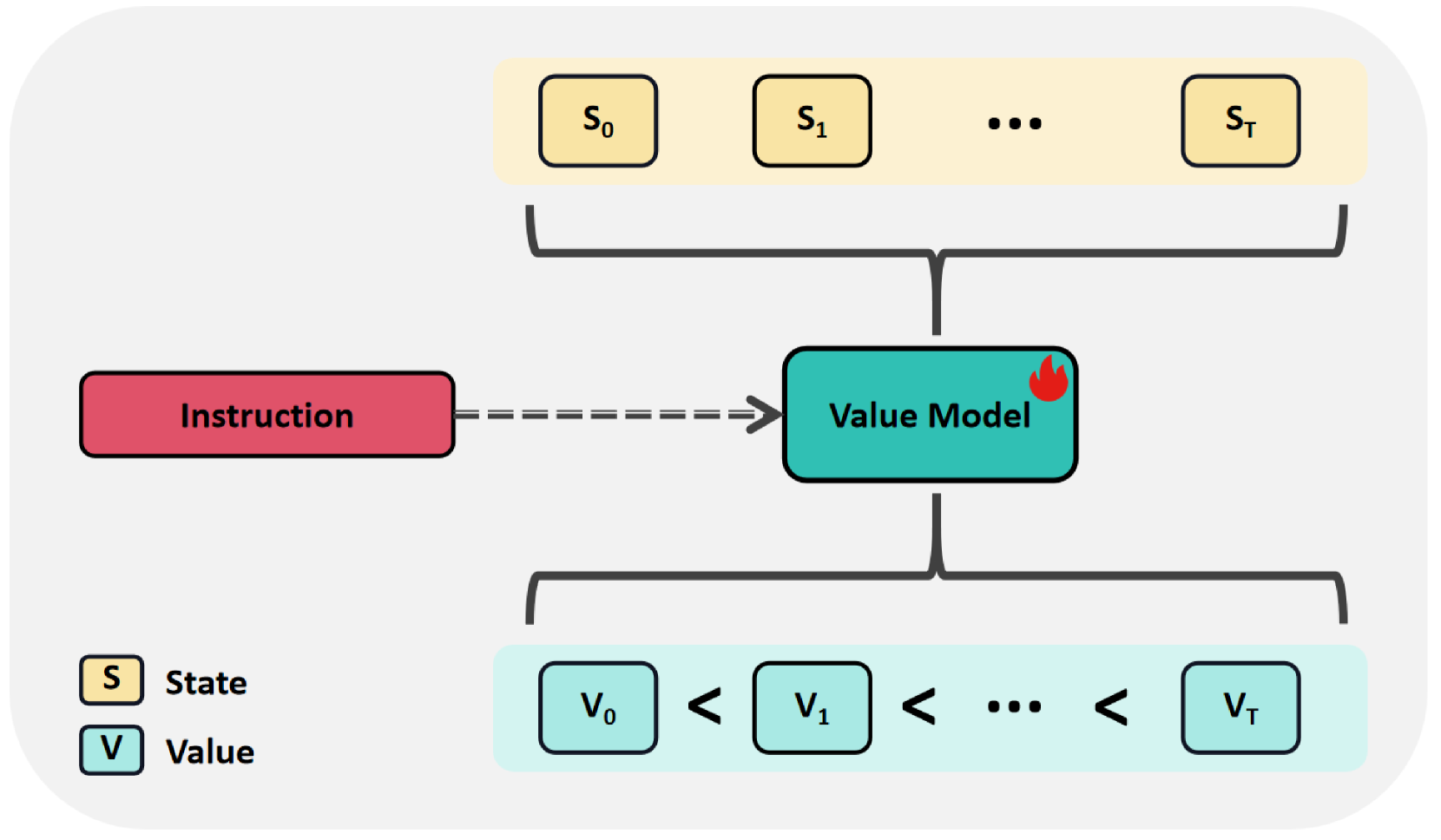
核心思路:RFTF的核心在于利用价值模型生成密集奖励,从而为智能体提供更细粒度的学习信号。价值模型通过时序信息进行训练,避免了对昂贵的人工标注动作标签的依赖。通过密集奖励,智能体可以更好地学习动作与环境之间的关系,从而提高操纵能力和泛化性能。
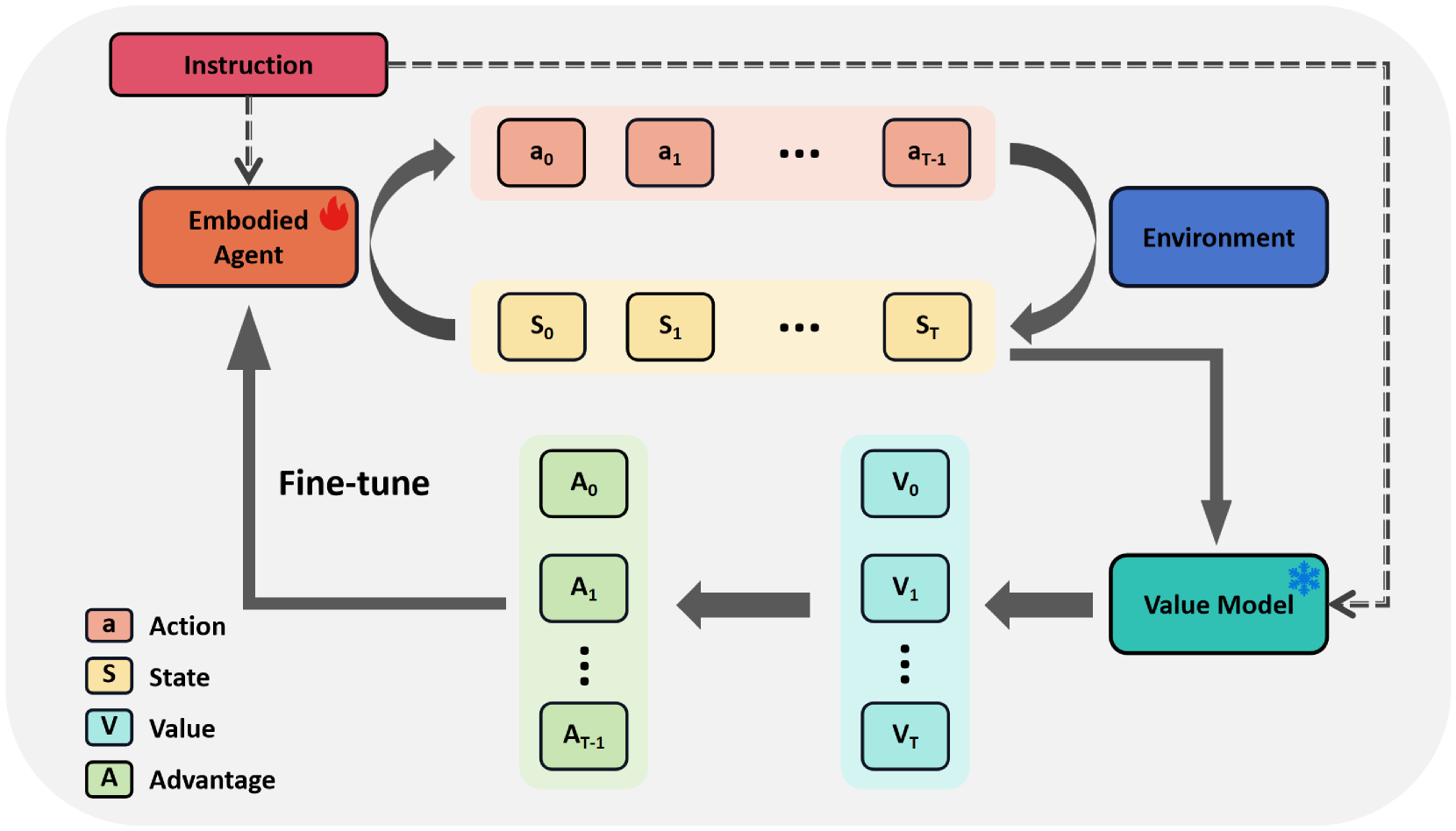
技术框架:RFTF的整体框架包括以下几个主要模块:1) 预训练的视觉-语言-动作(VLA)模型作为初始策略;2) 价值模型,用于预测状态的价值,并生成密集奖励;3) 强化学习算法,用于微调VLA模型。流程上,首先使用VLA模型与环境交互,收集经验数据。然后,价值模型根据经验数据生成密集奖励。最后,使用强化学习算法(如PPO)和密集奖励微调VLA模型。
关键创新:RFTF的关键创新在于使用价值模型生成密集奖励,并利用时序信息训练价值模型。与传统的稀疏奖励方法相比,RFTF能够提供更细粒度的反馈,从而提高智能体的学习效率和泛化能力。此外,RFTF避免了对人工标注动作标签的依赖,降低了训练成本。
关键设计:价值模型采用时序差分学习进行训练,损失函数为时序差分误差。RFTF采用了GAE(Generalized Advantage Estimation)来估计优势函数,以减少方差。为了平衡样本,RFTF采用了样本平衡策略,对不同类型的样本进行加权。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
RFTF在CALVIN ABC-D数据集上取得了显著的性能提升,平均成功长度达到4.296,超越了现有方法。此外,RFTF展现出快速适应新环境的能力,在CALVIN的D环境中进行少量episode的微调后,平均成功长度达到4.301。这些结果表明,RFTF能够有效解决稀疏奖励问题,提高具身智能体的性能和泛化能力。
🎯 应用场景
RFTF方法可应用于各种具身智能任务,例如机器人操作、自动驾驶、虚拟助手等。通过提供更有效的强化微调方法,RFTF可以降低具身智能体的开发成本,提高其性能和泛化能力,从而加速具身智能技术在实际场景中的应用。未来,该方法有望扩展到更复杂的任务和环境,实现更智能、更自主的具身智能体。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated significant potential in the field of embodied intelligence, enabling agents to follow human instructions to complete complex tasks in physical environments. Existing embodied agents are often trained through behavior cloning, which requires expensive data and computational resources and is constrained by human demonstrations. To address this issue, many researchers explore the application of reinforcement fine-tuning to embodied agents. However, typical reinforcement fine-tuning methods for embodied agents usually rely on sparse, outcome-based rewards, which struggle to provide fine-grained feedback for specific actions within an episode, thus limiting the model's manipulation capabilities and generalization performance. In this paper, we propose RFTF, a novel reinforcement fine-tuning method that leverages a value model to generate dense rewards in embodied scenarios. Specifically, our value model is trained using temporal information, eliminating the need for costly robot action labels. In addition, RFTF incorporates a range of techniques, such as GAE and sample balance to enhance the effectiveness of the fine-tuning process. By addressing the sparse reward problem in reinforcement fine-tuning, our method significantly improves the performance of embodied agents, delivering superior generalization and adaptation capabilities across diverse embodied tasks. Experimental results show that embodied agents fine-tuned with RFTF achieve new state-of-the-art performance on the challenging CALVIN ABC-D with an average success length of 4.296. Moreover, RFTF enables rapid adaptation to new environments. After fine-tuning in the D environment of CALVIN for a few episodes, RFTF achieved an average success length of 4.301 in this new environment.