YOPO-Rally: A Sim-to-Real Single-Stage Planner for Off-Road Terrain
作者: Hongyu Cao, Junjie Lu, Xuewei Zhang, Yulin Hui, Zhiyu Li, Bailing Tian
分类: cs.RO
发布日期: 2025-05-24
备注: 8 pages, 8 figures
💡 一句话要点
提出YOPO-Rally,用于在复杂地形中实现零样本迁移的单阶段端到端导航。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 越野导航 端到端学习 零样本迁移 地形可通行性分析 行为克隆
📋 核心要点
- 越野导航面临复杂地形和障碍物挑战,传统方法难以兼顾效率与泛化性。
- YOPO-Rally将地形分析与路径规划集成到单神经网络中,实现端到端越野导航。
- 通过模拟器训练,YOPO-Rally无需真实数据微调,即可实现零样本迁移。
📝 摘要(中文)
本文针对自主机器人在恶劣地形和密集障碍物中越野导航的挑战,将YOPO(You Only Plan Once)端到端导航框架扩展到越野环境,特别关注森林地形。为此,构建了一个高性能、多传感器支持的越野模拟器YOPO-Sim,一个零样本迁移的sim-to-real规划器YOPO-Rally,以及一个MPC控制器。YOPO-Sim基于Unity引擎,可以生成随机森林环境,并导出深度图像和点云地图用于专家演示,性能与主流模拟器相当。地形可通行性分析(TTA)处理代价地图,生成表示为非均匀三次Hermite曲线的专家轨迹。该规划器将TTA和路径规划集成到一个神经网络中,输入深度图像、当前速度和目标向量,输出多个带有代价的候选轨迹。该规划器通过在模拟器中进行行为克隆训练,并直接部署到真实世界,无需微调。最后,通过一系列模拟和真实世界的实验验证了所提出框架的性能。
🔬 方法详解
问题定义:现有的越野导航方法通常依赖于分层的规划架构,例如先进行环境感知和建模,然后进行路径规划和运动控制。这种方法计算量大,难以实时响应复杂地形的变化。此外,从仿真到真实的迁移通常需要大量的真实数据进行微调,成本高昂。因此,需要一种能够高效、鲁棒地进行越野导航,并且能够实现零样本迁移的端到端方法。
核心思路:YOPO-Rally的核心思路是将地形可通行性分析(TTA)和路径规划集成到一个神经网络中,直接从深度图像、当前速度和目标向量预测多个候选轨迹及其代价。这种端到端的方法避免了中间环节的误差累积,提高了规划效率。通过在模拟环境中进行行为克隆训练,可以学习到专家轨迹的生成策略,从而实现零样本迁移。
技术框架:YOPO-Rally的整体框架包括三个主要组成部分:YOPO-Sim模拟器、YOPO-Rally规划器和MPC控制器。YOPO-Sim用于生成随机森林环境和专家轨迹数据。YOPO-Rally规划器是一个神经网络,输入深度图像、当前速度和目标向量,输出多个候选轨迹及其代价。MPC控制器根据YOPO-Rally输出的轨迹进行运动控制。
关键创新:YOPO-Rally的关键创新在于将地形可通行性分析和路径规划集成到一个神经网络中,实现了端到端的越野导航。这种方法避免了传统分层规划架构的复杂性和误差累积,提高了规划效率和鲁棒性。此外,通过在模拟环境中进行行为克隆训练,实现了零样本迁移,降低了真实数据的需求。
关键设计:YOPO-Sim使用Unity引擎构建,可以生成随机森林环境,并导出深度图像和点云地图。地形可通行性分析(TTA)处理代价地图,生成表示为非均匀三次Hermite曲线的专家轨迹。YOPO-Rally规划器使用卷积神经网络提取深度图像的特征,并使用全连接层预测候选轨迹及其代价。损失函数采用行为克隆损失,用于学习专家轨迹的生成策略。
🖼️ 关键图片
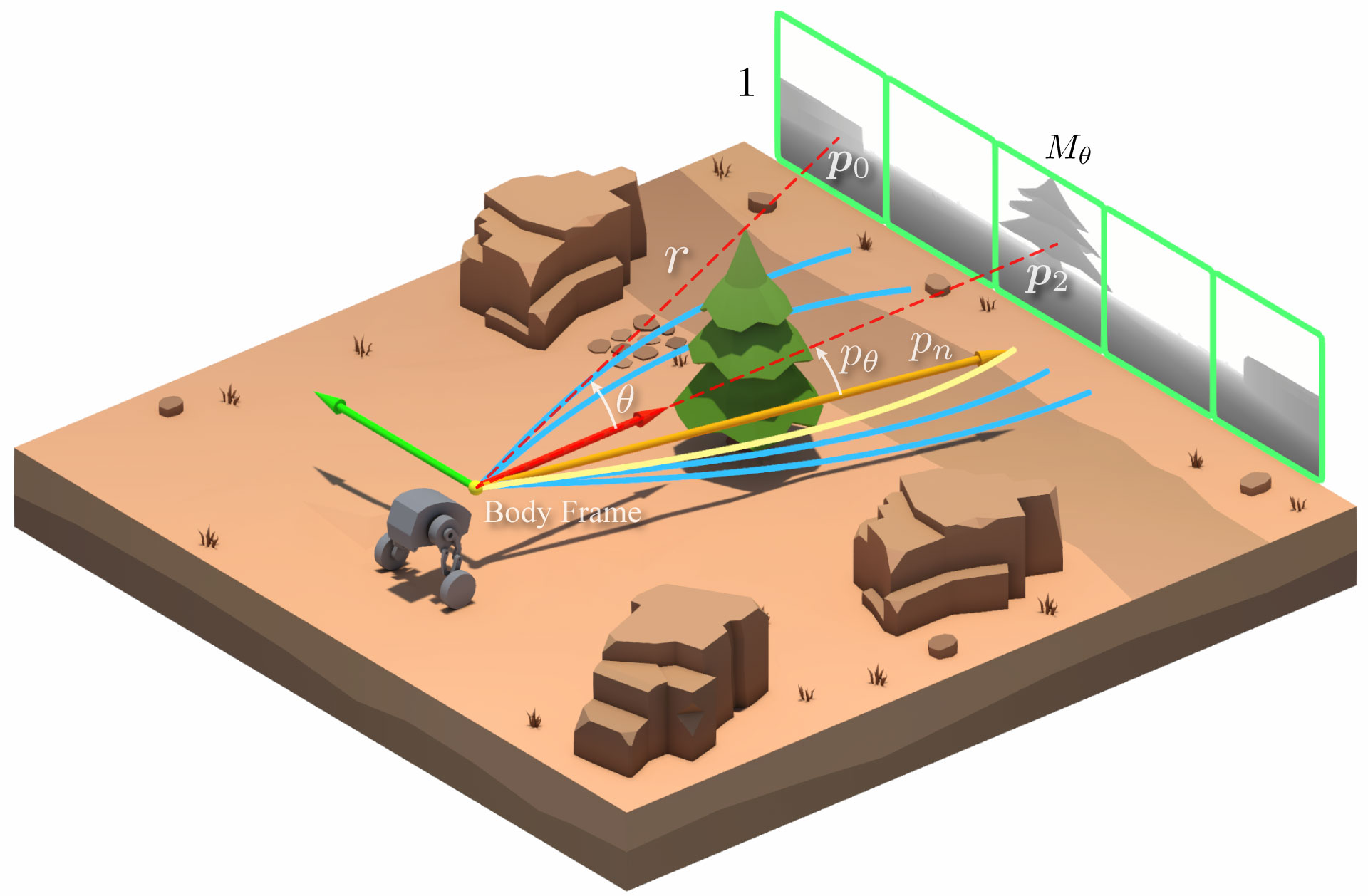

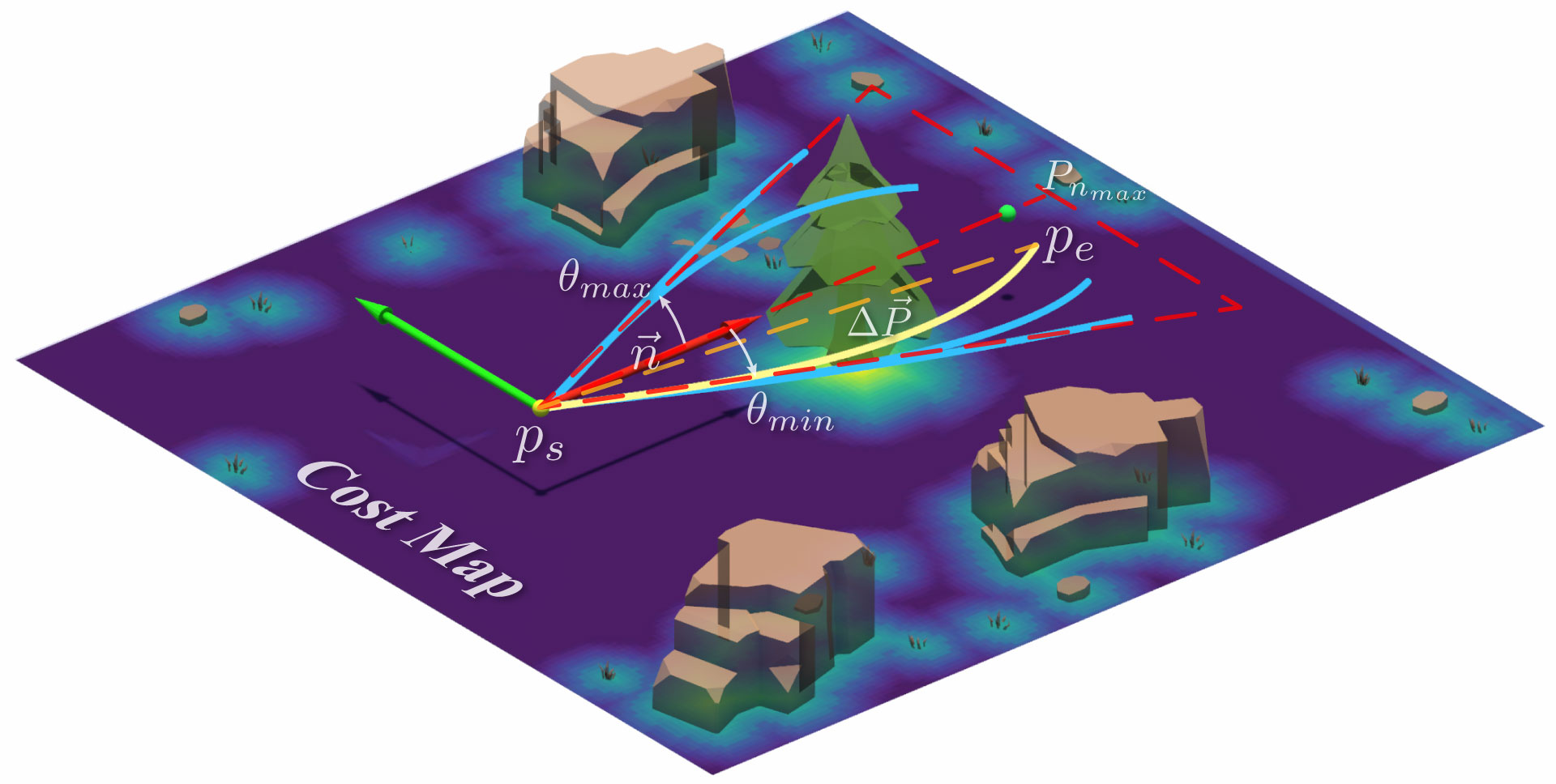
📊 实验亮点
实验结果表明,YOPO-Rally在模拟和真实环境中均表现出良好的导航性能。在模拟环境中,YOPO-Rally能够成功导航通过各种复杂地形,并与主流模拟器性能相当。在真实环境中,YOPO-Rally无需微调即可实现零样本迁移,成功导航通过森林地形,验证了该方法的有效性和泛化能力。
🎯 应用场景
YOPO-Rally可应用于各种越野机器人,例如搜救机器人、农业机器人、巡检机器人等。该方法能够提高机器人在复杂地形中的导航能力,降低开发成本,加速机器人的部署和应用。未来,该技术有望应用于自动驾驶领域,提升车辆在非结构化道路上的行驶能力。
📄 摘要(原文)
Off-road navigation remains challenging for autonomous robots due to the harsh terrain and clustered obstacles. In this letter, we extend the YOPO (You Only Plan Once) end-to-end navigation framework to off-road environments, explicitly focusing on forest terrains, consisting of a high-performance, multi-sensor supported off-road simulator YOPO-Sim, a zero-shot transfer sim-to-real planner YOPO-Rally, and an MPC controller. Built on the Unity engine, the simulator can generate randomized forest environments and export depth images and point cloud maps for expert demonstrations, providing competitive performance with mainstream simulators. Terrain Traversability Analysis (TTA) processes cost maps, generating expert trajectories represented as non-uniform cubic Hermite curves. The planner integrates TTA and the pathfinding into a single neural network that inputs the depth image, current velocity, and the goal vector, and outputs multiple trajectory candidates with costs. The planner is trained by behavior cloning in the simulator and deployed directly into the real-world without fine-tuning. Finally, a series of simulated and real-world experiments is conducted to validate the performance of the proposed framework.