HACL: History-Aware Curriculum Learning for Fast Locomotion
作者: Prakhar Mishra, Amir Hossain Raj, Xuesu Xiao, Dinesh Manocha
分类: cs.RO
发布日期: 2025-05-23 (更新: 2025-11-18)
💡 一句话要点
提出历史感知课程学习(HACL)算法,提升四足机器人高速运动性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 运动控制 强化学习 课程学习 循环神经网络 历史感知 高速运动
📋 核心要点
- 现有运动算法难以充分利用历史信息,导致机器人难以实现敏捷快速的运动控制。
- 提出历史感知课程学习(HACL)算法,利用RNN对历史关节速度指令与奖励之间的关系进行建模,从而学习更优的运动策略。
- 在多种机器人平台和真实环境中验证了HACL算法的有效性,实现了更高的运动速度和性能提升。
📝 摘要(中文)
本文旨在解决四足和双足机器人敏捷快速运动的问题。提出了一种新的算法,通过考虑运动的时间维度来维持稳定并生成高速轨迹。该方法基于一种新颖的历史感知课程学习(HACL)算法,利用过去的信息。使用循环神经网络(RNN)对关节速度指令的历史与观察到的线性和角速度奖励之间的关系进行建模。隐藏状态帮助课程学习在给定时间步长内前向线速度和角速度指令与奖励之间的关系。在模拟环境中的MIT Mini Cheetah、Unitree Go1和Go2机器人以及真实环境中的Unitree Go1机器人上验证了该方法的有效性。 实验结果表明,HACL在7m/s的指令速度下实现了6.7m/s的峰值前进速度,并且性能优于先前的运动算法近20%。
🔬 方法详解
问题定义:论文旨在解决四足和双足机器人敏捷快速运动的问题。现有的运动控制算法通常难以充分利用历史信息,导致机器人难以在高速运动中保持稳定性和灵活性。这限制了机器人在复杂环境中的应用能力。
核心思路:论文的核心思路是利用历史信息来指导运动策略的学习。通过引入历史感知机制,算法能够更好地理解运动指令与机器人状态之间的关系,从而生成更优的运动轨迹。具体而言,使用循环神经网络(RNN)来建模历史信息,并将其融入到课程学习框架中。
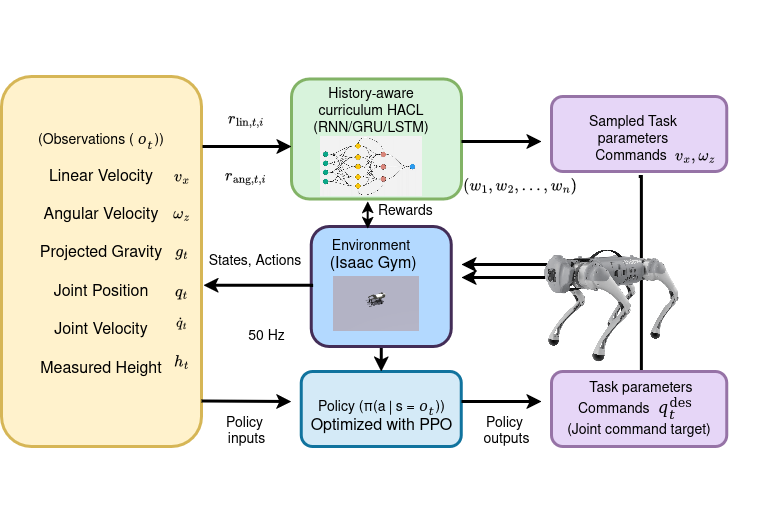
技术框架:HACL算法的整体框架包括以下几个主要模块:1)环境交互模块:机器人与模拟或真实环境进行交互,获取状态信息和奖励信号。2)历史建模模块:使用RNN对历史关节速度指令进行建模,提取历史特征。3)策略学习模块:利用历史特征和当前状态信息,学习运动控制策略。4)课程学习模块:通过课程学习策略,逐步提升机器人的运动能力。
关键创新:HACL算法的关键创新在于引入了历史感知机制,并将其与课程学习相结合。传统的课程学习方法通常只关注当前状态,而忽略了历史信息的重要性。HACL算法通过RNN建模历史信息,使得算法能够更好地理解运动指令与机器人状态之间的关系,从而学习更优的运动策略。
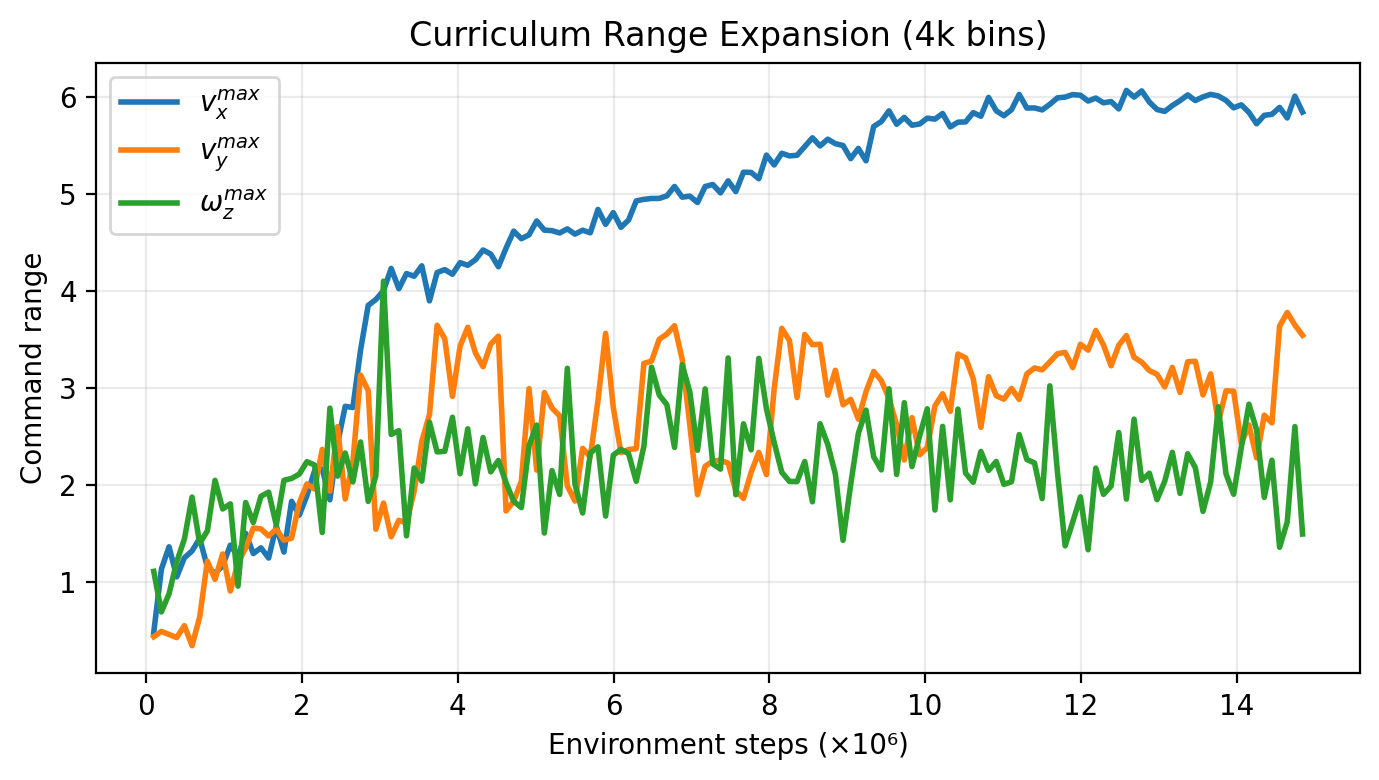
关键设计:HACL算法的关键设计包括:1)RNN结构:使用LSTM或GRU等循环神经网络结构来建模历史信息。2)奖励函数:设计合适的奖励函数来引导机器人学习期望的运动行为。3)课程设计:设计合理的课程,逐步提升机器人的运动能力。例如,可以从简单的运动任务开始,逐步增加难度。4)训练参数:需要仔细调整RNN的训练参数,以获得最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HACL算法在模拟和真实环境中均取得了显著的性能提升。在Unitree Go1机器人上,HACL算法实现了6.7m/s的峰值前进速度,接近7m/s的指令速度,并且性能优于先前的运动算法近20%。这些结果表明,HACL算法能够有效地提升机器人的运动速度和性能。
🎯 应用场景
该研究成果可广泛应用于四足和双足机器人的运动控制领域,例如搜救机器人、物流机器人、巡检机器人等。通过提升机器人的运动速度和灵活性,可以使其在复杂环境中执行更加高效的任务。此外,该方法还可以应用于虚拟现实和游戏等领域,提升虚拟角色的运动逼真度。
📄 摘要(原文)
We address the problem of agile and rapid locomotion, a key characteristic of quadrupedal and bipedal robots. We present a new algorithm that maintains stability and generates high-speed trajectories by considering the temporal aspect of locomotion. Our formulation takes into account past information based on a novel history-aware curriculum Learning (HACL) algorithm. We model the history of joint velocity commands with respect to the observed linear and angular rewards using a recurrent neural net (RNN). The hidden state helps the curriculum learn the relationship between the forward linear velocity and angular velocity commands and the rewards over a given time-step. We validate our approach on the MIT Mini Cheetah,Unitree Go1, and Go2 robots in a simulated environment and on a Unitree Go1 robot in real-world scenarios. In practice, HACL achieves peak forward velocity of 6.7 m/s for a given command velocity of 7m/s and outperforms prior locomotion algorithms by nearly 20%.