Reinforcement Learning for Ballbot Navigation in Uneven Terrain
作者: Achkan Salehi
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-23
备注: 6 pages, 8 figures, 2 tables
💡 一句话要点
提出基于强化学习的球形机器人崎岖地形导航方法与开源仿真器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 球形机器人 强化学习 崎岖地形导航 MuJoCo仿真 无模型学习
📋 核心要点
- 传统球形机器人导航依赖控制理论,对环境动力学有简化假设,限制了其在复杂环境中的应用。
- 该论文提出基于强化学习的导航方法,无需简化假设,可直接利用深度图等外部信息,增强适应性。
- 论文贡献包括开源的MuJoCo球形机器人仿真器,以及验证了经典无模型RL算法在崎岖地形导航中的有效性。
📝 摘要(中文)
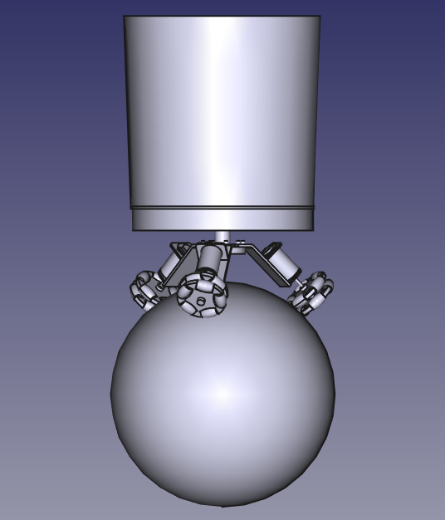
球形机器人(Ballbot)导航通常依赖于控制理论(CT)方法,而将强化学习(RL)应用于该问题的研究仍然很少,并且通常仅限于特定的子任务(例如,平衡恢复)。与基于CT的方法不同,RL不需要对环境动力学进行(简化)假设(例如,球和地板之间没有滑动)。除了这种建模精度的提高之外,RL智能体可以很容易地以额外的观察结果(如深度图)为条件,而不需要从第一性原理进行显式公式化,从而提高了适应性。尽管有这些优点,但对于基于RL的球形机器人控制和导航方法的能力、数据效率和局限性,几乎没有研究。此外,对于这项任务,明显缺乏一个开源的、对RL友好的模拟器。在本文中,我们提出了一个基于MuJoCo的开源球形机器人仿真,并表明,通过对外部感受观察进行适当的调节以及奖励塑造,经典无模型RL方法学习到的策略能够有效地在随机生成的崎岖地形中导航,并且使用合理的数据量(在以500hz运行的系统上运行四到五个小时)。
🔬 方法详解
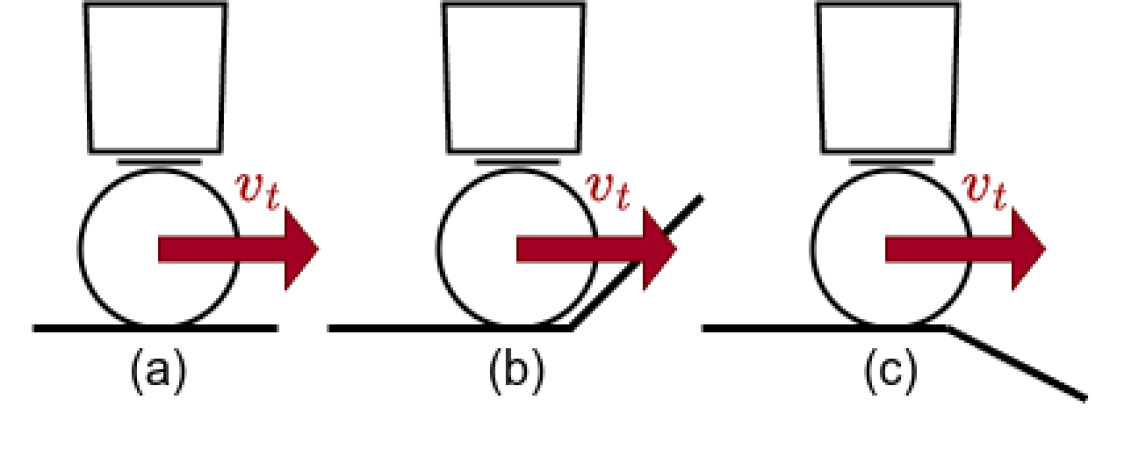
问题定义:球形机器人在崎岖地形中的导航是一个复杂的问题。传统的控制理论方法通常需要对环境动力学进行简化假设,例如忽略球与地面之间的滑动,这限制了其在真实复杂环境中的应用。此外,控制理论方法难以直接融合深度图等外部感知信息,从而限制了机器人的环境适应能力。
核心思路:该论文的核心思路是利用强化学习(RL)来解决球形机器人在崎岖地形中的导航问题。与控制理论方法不同,RL不需要对环境动力学进行简化假设,可以直接从环境中学习最优策略。此外,RL智能体可以很容易地以额外的观察结果(如深度图)为条件,从而提高环境适应性。
技术框架:该论文的技术框架主要包括以下几个部分:1)基于MuJoCo的球形机器人仿真环境;2)强化学习算法(例如,PPO,SAC等);3)奖励函数的设计;4)外部感受观察的融合(例如,深度图)。整体流程是:首先在仿真环境中训练RL智能体,然后将训练好的策略部署到真实的球形机器人上。
关键创新:该论文的关键创新点在于:1)提出了一个开源的、对RL友好的球形机器人仿真环境,这为后续的研究提供了便利;2)验证了经典无模型RL算法在崎岖地形导航中的有效性;3)展示了如何通过对外部感受观察进行适当的调节以及奖励塑造,来提高RL智能体的性能。
关键设计:论文中奖励函数的设计至关重要,需要平衡导航速度、平衡性和能量消耗。外部感受观察(例如,深度图)的处理也需要仔细设计,以提取有用的特征信息。此外,RL算法的选择和参数调整也会影响最终的性能。论文提到使用了四到五个小时的数据在500Hz的系统上进行训练,但没有详细说明具体的参数设置。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了基于强化学习的球形机器人导航方法在崎岖地形中的有效性。虽然论文中没有给出具体的性能数据和对比基线,但强调了该方法能够使用合理的数据量(四到五个小时)在随机生成的崎岖地形中实现有效的导航。开源仿真器的发布也为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于物流、安防、勘探等领域,使球形机器人能够在复杂地形中自主导航。开源仿真器的发布将促进球形机器人控制和导航领域的研究,加速相关技术的落地应用。未来,该技术有望扩展到其他类型的移动机器人,提升其在复杂环境中的适应性和自主性。
📄 摘要(原文)
Ballbot (i.e. Ball balancing robot) navigation usually relies on methods rooted in control theory (CT), and works that apply Reinforcement learning (RL) to the problem remain rare while generally being limited to specific subtasks (e.g. balance recovery). Unlike CT based methods, RL does not require (simplifying) assumptions about environment dynamics (e.g. the absence of slippage between the ball and the floor). In addition to this increased accuracy in modeling, RL agents can easily be conditioned on additional observations such as depth-maps without the need for explicit formulations from first principles, leading to increased adaptivity. Despite those advantages, there has been little to no investigation into the capabilities, data-efficiency and limitations of RL based methods for ballbot control and navigation. Furthermore, there is a notable absence of an open-source, RL-friendly simulator for this task. In this paper, we present an open-source ballbot simulation based on MuJoCo, and show that with appropriate conditioning on exteroceptive observations as well as reward shaping, policies learned by classical model-free RL methods are capable of effectively navigating through randomly generated uneven terrain, using a reasonable amount of data (four to five hours on a system operating at 500hz).