Find the Fruit: Zero-Shot Sim2Real RL for Occlusion-Aware Plant Manipulation
作者: Nitesh Subedi, Hsin-Jung Yang, Devesh K. Jha, Soumik Sarkar
分类: cs.RO, cs.AI
发布日期: 2025-05-22 (更新: 2025-09-30)
备注: 9 Pages, 3 Figures, 1 Table
💡 一句话要点
提出基于Sim2Real强化学习的遮挡感知植物操作方法,用于自主采摘。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Sim2Real 机器人操作 自主采摘 遮挡感知
📋 核心要点
- 开放环境下的自主采摘面临严重的遮挡和植物结构不确定性,导致传统操作控制器的性能不佳。
- 论文提出解耦高层运动规划和低层柔顺控制的Sim2Real强化学习框架,以应对遮挡和结构不确定性。
- 实验结果表明,该系统在真实植物上暴露目标果实的成功率高达86.7%,验证了其鲁棒性。
📝 摘要(中文)
本文提出了一种基于Sim2Real强化学习的遮挡感知植物操作框架,用于解决开放环境中自主采摘的复杂操作问题。该框架完全在仿真环境中学习策略,通过重新定位茎和叶子来暴露目标果实。该方法将高层运动规划与低层柔顺控制解耦,简化了Sim2Real迁移,并允许学习到的策略推广到具有不同刚度和形态的多种植物。在多个真实植物设置的实验中,该系统在暴露目标果实方面达到了高达86.7%的成功率,证明了其对遮挡变化和结构不确定性的鲁棒性。
🔬 方法详解
问题定义:开放环境下的自主采摘任务面临的主要挑战是果实常常被茎和叶子遮挡,以及不同植物的结构差异很大。传统的基于视觉的采摘方法难以处理复杂的遮挡情况,而精确的植物建模又非常困难。因此,需要一种能够适应遮挡变化和结构不确定性的操作策略。
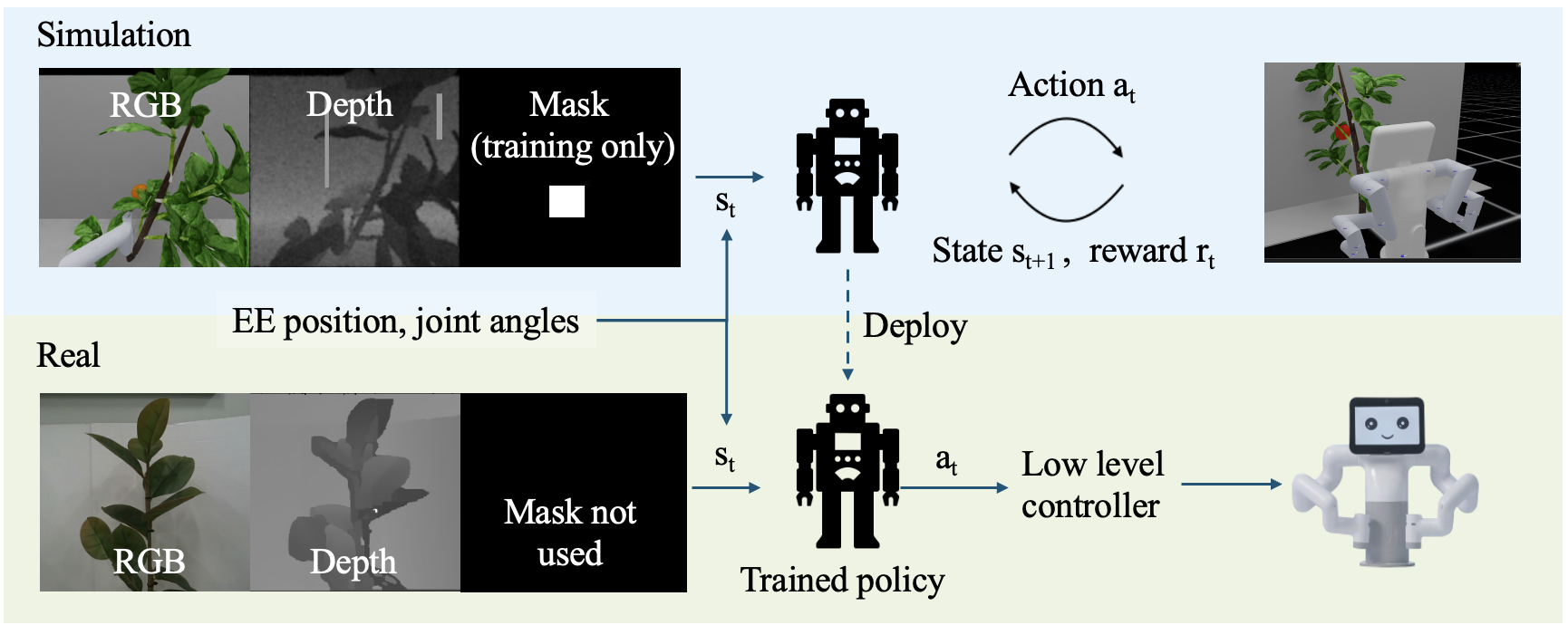
核心思路:论文的核心思路是利用强化学习在仿真环境中学习一种操作策略,该策略能够通过操作茎和叶子来暴露被遮挡的果实。为了简化Sim2Real迁移,将高层运动规划与低层柔顺控制解耦。高层策略负责规划操作动作,而低层控制器负责执行这些动作,从而降低了对精确建模的需求。
技术框架:整体框架包含仿真环境、强化学习训练模块和真实环境部署三个主要部分。首先,在仿真环境中构建植物模型,并定义奖励函数,鼓励策略暴露果实。然后,使用强化学习算法(具体算法未知)训练操作策略。训练完成后,将策略部署到真实机器人上,通过视觉系统感知环境,并执行策略。低层柔顺控制保证了操作的安全性。
关键创新:该方法的主要创新在于将高层运动规划与低层柔顺控制解耦,从而简化了Sim2Real迁移。这种解耦使得学习到的策略能够更好地泛化到不同的植物结构上。此外,利用强化学习自动学习操作策略,避免了手动设计复杂控制器的困难。
关键设计:论文中未明确给出强化学习算法的具体细节,例如状态空间、动作空间、奖励函数以及网络结构等。但是,可以推断状态空间可能包含视觉信息(例如图像或点云),动作空间可能包含机器人末端执行器的运动指令。奖励函数的设计至关重要,需要鼓励策略暴露果实,同时避免对植物造成损害。低层柔顺控制器的参数设置也需要仔细调整,以保证操作的安全性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该系统在多个真实植物设置中,暴露目标果实的成功率高达86.7%。这表明该方法对遮挡变化和结构不确定性具有很强的鲁棒性。与传统的基于视觉的采摘方法相比,该方法能够更好地处理复杂的遮挡情况,从而提高了采摘效率。
🎯 应用场景
该研究成果可应用于农业机器人领域,实现自主采摘。通过操作植物的茎和叶子来暴露果实,可以提高采摘效率和质量,降低人工成本。此外,该方法还可以扩展到其他需要操作柔性物体的场景,例如医疗手术和家庭服务机器人。
📄 摘要(原文)
Autonomous harvesting in the open presents a complex manipulation problem. In most scenarios, an autonomous system has to deal with significant occlusion and require interaction in the presence of large structural uncertainties (every plant is different). Perceptual and modeling uncertainty make design of reliable manipulation controllers for harvesting challenging, resulting in poor performance during deployment. We present a sim2real reinforcement learning (RL) framework for occlusion-aware plant manipulation, where a policy is learned entirely in simulation to reposition stems and leaves to reveal target fruit(s). In our proposed approach, we decouple high-level kinematic planning from low-level compliant control which simplifies the sim2real transfer. This decomposition allows the learned policy to generalize across multiple plants with different stiffness and morphology. In experiments with multiple real-world plant setups, our system achieves up to 86.7% success in exposing target fruits, demonstrating robustness to occlusion variation and structural uncertainty.