Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
作者: Zhenjie Yang, Xiaosong Jia, Qifeng Li, Xue Yang, Maoqing Yao, Junchi Yan
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-05-22 (更新: 2025-10-25)
备注: Accepted by NeurIPS 2025
💡 一句话要点
Raw2Drive:基于对齐世界模型的强化学习端到端自动驾驶方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 端到端自动驾驶 强化学习 世界模型 模仿学习 知识迁移 CARLA仿真 双流网络
📋 核心要点
- 端到端自动驾驶中,直接使用强化学习训练策略困难,模仿学习易受因果混淆和分布偏移影响。
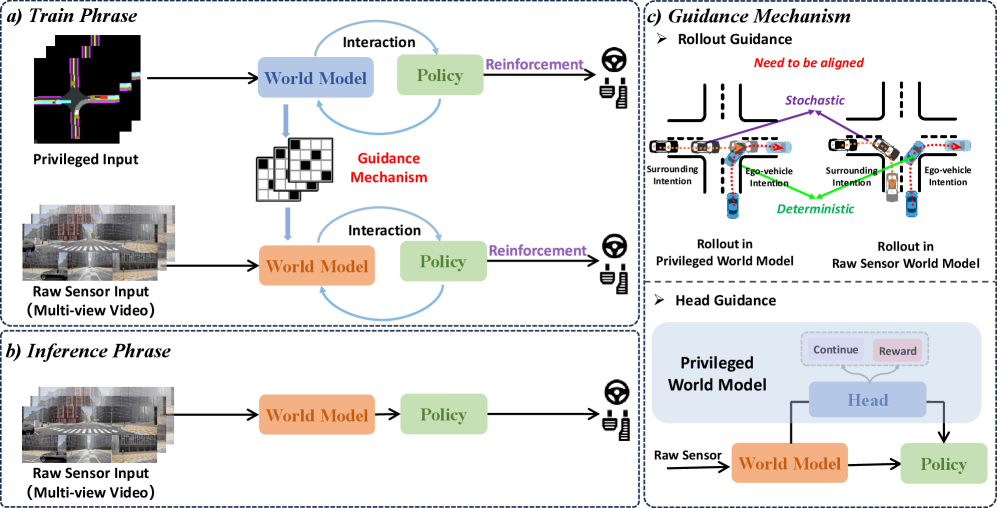
- Raw2Drive提出双流MBRL方法,利用特权世界模型引导原始传感器世界模型的训练,提升策略学习效率。
- Raw2Drive在CARLA Leaderboard 2.0和Bench2Drive上取得领先,是首个基于RL的端到端方法。
📝 摘要(中文)
强化学习(RL)可以缓解模仿学习(IL)中固有的因果混淆和分布偏移问题。然而,将RL应用于端到端自动驾驶(E2E-AD)仍然是一个开放性问题,因为其训练难度较高,而IL仍然是学术界和工业界的主流范式。最近,基于模型的强化学习(MBRL)在神经规划中表现出良好的结果;然而,这些方法通常需要特权信息作为输入,而不是原始传感器数据。我们通过设计Raw2Drive来填补这一空白,Raw2Drive是一种双流MBRL方法。最初,我们有效地训练一个辅助的特权世界模型,并配有一个使用特权信息作为输入的神经规划器。随后,我们引入了一个原始传感器世界模型,该模型通过我们提出的引导机制进行训练,该机制确保了rollout期间原始传感器世界模型和特权世界模型之间的一致性。最后,原始传感器世界模型结合了嵌入在特权世界模型头部中的先验知识,以有效地指导原始传感器策略的训练。Raw2Drive是迄今为止CARLA Leaderboard 2.0和Bench2Drive上唯一的基于RL的端到端方法,并且实现了最先进的性能。
🔬 方法详解
问题定义:端到端自动驾驶任务中,直接从原始传感器数据(如图像)训练强化学习策略非常困难。现有方法,如模仿学习,容易受到因果混淆和分布偏移的影响,导致泛化能力不足。基于模型的强化学习虽然有潜力,但通常依赖于特权信息,无法直接应用于实际场景。
核心思路:Raw2Drive的核心思路是利用一个易于训练的、基于特权信息的世界模型来引导一个基于原始传感器数据的世界模型的训练。通过确保两个世界模型在rollout期间的一致性,将特权世界模型的先验知识迁移到原始传感器世界模型,从而加速和稳定策略学习。
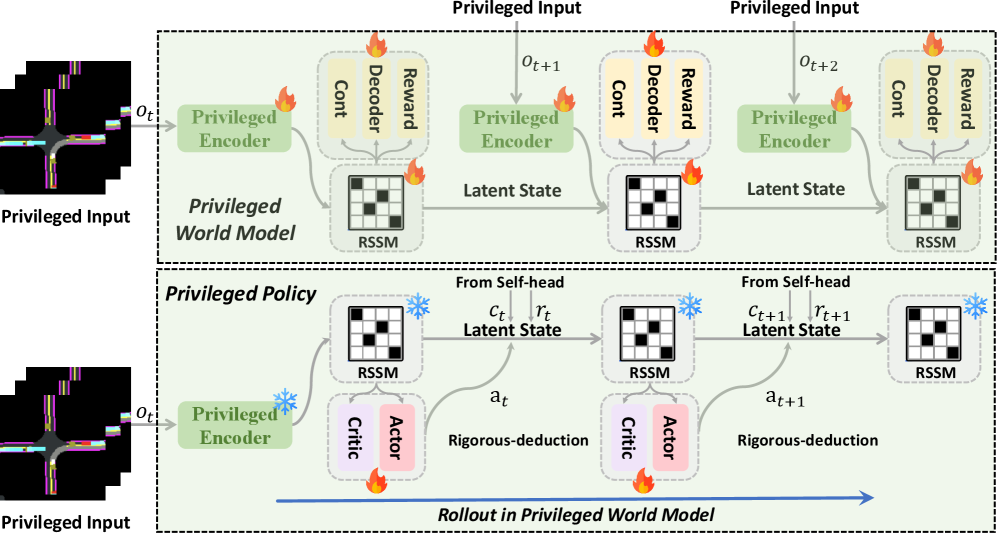
技术框架:Raw2Drive采用双流架构。第一条流是特权世界模型,它接收特权信息(如车辆状态、环境信息)作为输入,并与神经规划器一起训练。第二条流是原始传感器世界模型,它接收原始传感器数据(如图像)作为输入。通过提出的引导机制,原始传感器世界模型在rollout期间与特权世界模型保持一致性。最终,原始传感器世界模型用于训练控制策略。
关键创新:Raw2Drive的关键创新在于其引导机制,该机制通过最小化原始传感器世界模型和特权世界模型之间的差异,实现了知识迁移。这种方法避免了直接从原始传感器数据训练强化学习策略的困难,并利用了特权信息的优势。
关键设计:引导机制通过设计特定的损失函数来实现,该损失函数惩罚原始传感器世界模型和特权世界模型在状态预测上的差异。此外,特权世界模型的头部(head)被用于指导原始传感器策略的训练,进一步提升了策略的性能。具体的网络结构和参数设置在论文中有详细描述,但此处未给出。
🖼️ 关键图片

📊 实验亮点
Raw2Drive在CARLA Leaderboard 2.0和Bench2Drive上取得了最先进的性能,成为首个基于强化学习的端到端自动驾驶方法。具体性能数据和对比基线在论文中有详细展示,表明Raw2Drive在复杂驾驶场景中具有显著的优势,例如在城市导航任务中表现出更高的成功率和更低的碰撞率。
🎯 应用场景
Raw2Drive的研究成果可应用于自动驾驶车辆的感知和决策系统,尤其是在复杂和动态的城市环境中。该方法能够提升自动驾驶系统的鲁棒性和泛化能力,降低对高精度地图和传感器的依赖,从而降低自动驾驶系统的成本和部署难度。未来,该技术还可扩展到其他机器人领域,如无人机和移动机器人。
📄 摘要(原文)
Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.