SEM: Enhancing Spatial Understanding for Robust Robot Manipulation
作者: Xuewu Lin, Tianwei Lin, Lichao Huang, Hongyu Xie, Yiwei Jin, Keyu Li, Zhizhong Su
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-05-22 (更新: 2025-09-24)
💡 一句话要点
提出SEM模型,增强机器人操作的空间理解能力,提升操作鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 空间理解 扩散模型 3D几何 图神经网络
📋 核心要点
- 现有机器人操作方法在空间理解方面存在不足,3D点云缺乏语义信息,2D图像编码器空间推理能力弱。
- SEM模型通过空间增强器和机器人状态编码器,分别从视觉和机器人自身结构两个角度增强空间理解。
- 实验结果表明,SEM模型在各种操作任务中表现出色,显著优于现有基线方法,具有更好的鲁棒性和泛化性。
📝 摘要(中文)
机器人操作的关键挑战在于开发具有强大空间理解能力的策略模型,即推理3D几何、对象关系和机器人自身结构的能力。现有方法存在不足:3D点云模型缺乏语义抽象,而2D图像编码器在空间推理方面表现不佳。为了解决这个问题,我们提出了SEM(Spatial Enhanced Manipulation model),一种新颖的基于扩散的策略框架,从两个互补的角度显式地增强空间理解。空间增强器利用3D几何上下文来增强视觉表示,而机器人状态编码器通过基于图的关节依赖性建模来捕获机器人自身的结构信息。通过整合这些模块,SEM显著提高了空间理解能力,从而在各种任务中实现了鲁棒且可泛化的操作,优于现有基线。
🔬 方法详解
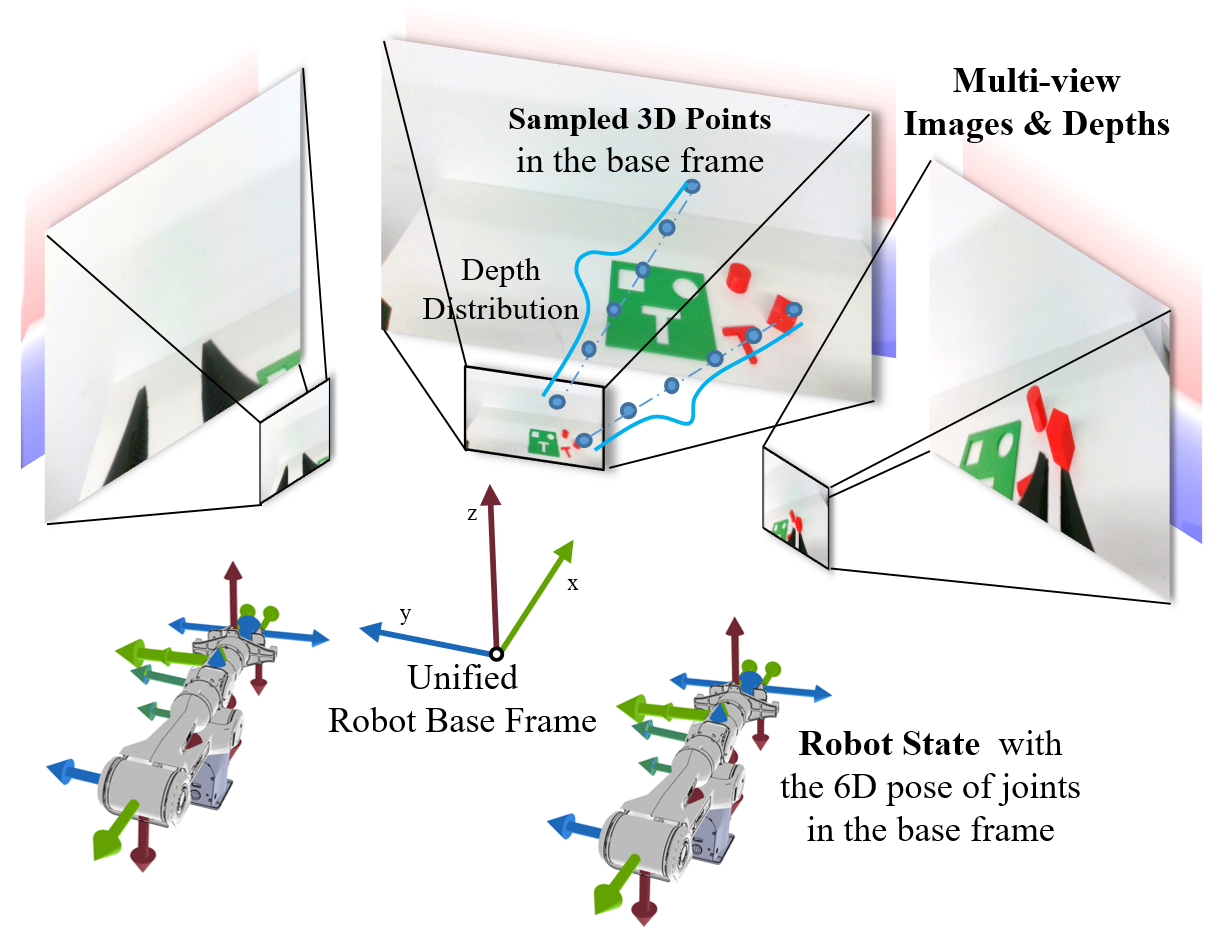
问题定义:机器人操作任务需要策略模型具备强大的空间理解能力,包括对3D几何、物体关系以及机器人自身结构的理解。现有的方法,例如直接使用3D点云,缺乏高层次的语义信息;而基于2D图像的方法,则难以进行准确的空间推理,导致操作的鲁棒性和泛化性不足。
核心思路:SEM的核心思路是从两个互补的角度增强策略模型的空间理解能力。一方面,利用3D几何信息增强视觉表示,弥补2D图像的不足;另一方面,通过对机器人自身结构的建模,使模型能够更好地理解机器人的运动学和动力学约束。
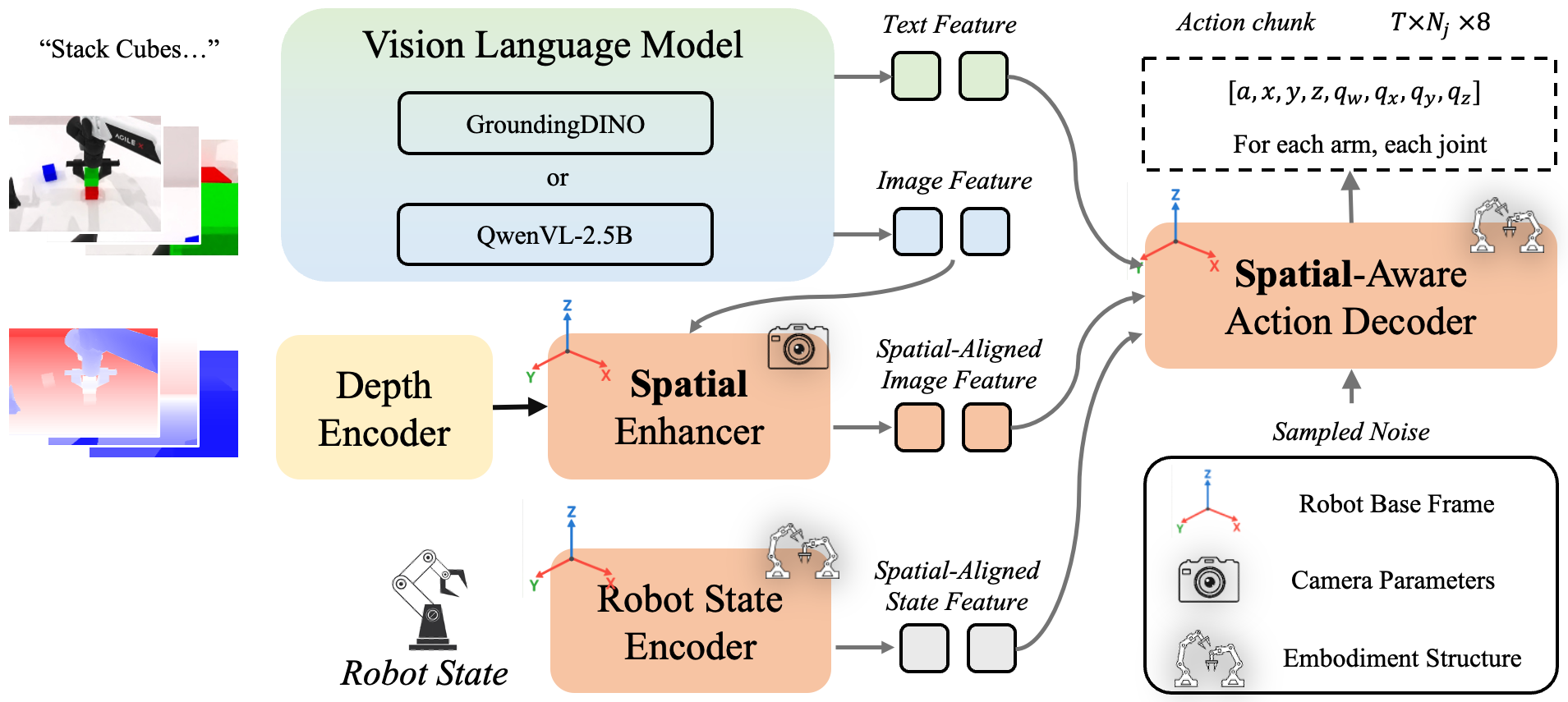
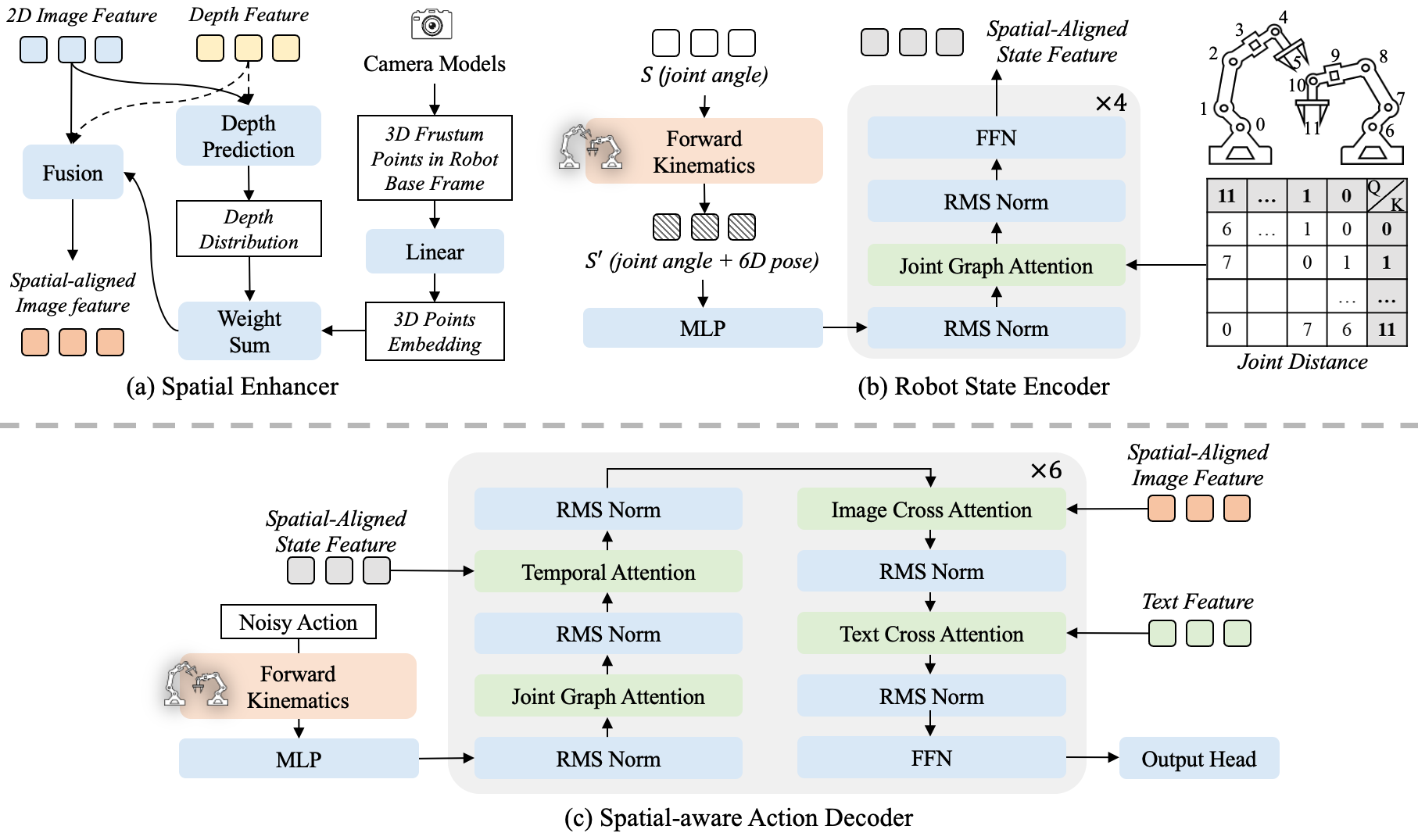
技术框架:SEM模型主要包含两个核心模块:空间增强器(Spatial Enhancer)和机器人状态编码器(Robot State Encoder)。空间增强器负责将视觉信息与3D几何上下文融合,生成更丰富的视觉表示。机器人状态编码器则通过图神经网络对机器人的关节依赖关系进行建模,提取机器人自身的状态特征。这两个模块的输出被整合到基于扩散的策略模型中,用于生成操作指令。
关键创新:SEM的关键创新在于显式地增强了策略模型的空间理解能力,通过结合视觉和机器人自身结构的信息,使模型能够更好地理解操作场景和机器人的运动约束。这种显式增强的方式,相比于隐式地学习空间信息,能够更有效地提高模型的鲁棒性和泛化性。
关键设计:空间增强器可能采用PointNet++等网络结构,将视觉特征与3D点云特征进行融合。机器人状态编码器则使用图神经网络,例如Graph Convolutional Network (GCN),对机器人的关节依赖关系进行建模。策略模型采用扩散模型,通过逐步去噪的方式生成操作指令。损失函数可能包括重构损失和策略梯度损失等。
🖼️ 关键图片
📊 实验亮点
论文提出的SEM模型在多个机器人操作任务上取得了显著的性能提升。实验结果表明,SEM模型在操作成功率、鲁棒性和泛化性方面均优于现有基线方法。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了SEM模型在增强空间理解方面的有效性。
🎯 应用场景
SEM模型具有广泛的应用前景,可以应用于各种机器人操作任务,例如物体抓取、装配、导航等。该研究成果有助于提升机器人在复杂环境中的操作能力,使其能够更好地适应不同的任务需求,具有重要的实际应用价值和潜在的商业价值。未来,可以将该模型应用于工业自动化、家庭服务机器人等领域。
📄 摘要(原文)
A key challenge in robot manipulation lies in developing policy models with strong spatial understanding, the ability to reason about 3D geometry, object relations, and robot embodiment. Existing methods often fall short: 3D point cloud models lack semantic abstraction, while 2D image encoders struggle with spatial reasoning. To address this, we propose SEM (Spatial Enhanced Manipulation model), a novel diffusion-based policy framework that explicitly enhances spatial understanding from two complementary perspectives. A spatial enhancer augments visual representations with 3D geometric context, while a robot state encoder captures embodiment-aware structure through graphbased modeling of joint dependencies. By integrating these modules, SEM significantly improves spatial understanding, leading to robust and generalizable manipulation across diverse tasks that outperform existing baselines.