HCRMP: A LLM-Hinted Contextual Reinforcement Learning Framework for Autonomous Driving
作者: Zhiwen Chen, Bo Leng, Zhuoren Li, Hanming Deng, Guizhe Jin, Ran Yu, Huanxi Wen
分类: cs.RO, cs.LG
发布日期: 2025-05-21 (更新: 2025-05-22)
💡 一句话要点
HCRMP:利用LLM提示的上下文强化学习框架,提升自动驾驶在复杂场景下的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 大语言模型 运动规划 上下文学习
📋 核心要点
- 现有LLM主导的强化学习方法过度依赖LLM输出,而LLM容易产生幻觉,严重影响自动驾驶策略的性能。
- HCRMP通过LLM提供语义提示,增强状态表示并优化策略,同时RL智能体学习纠正LLM的潜在错误,保持相对独立性。
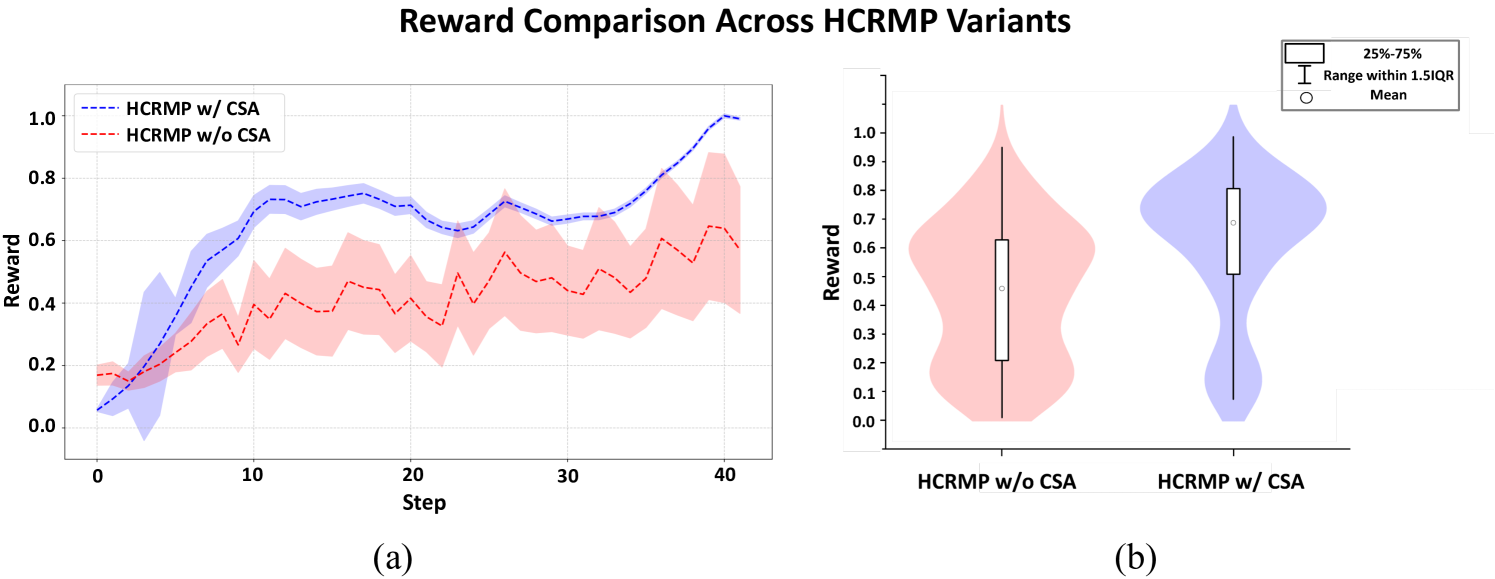
- 实验表明,HCRMP在CARLA中实现了高达80.3%的任务成功率,并显著降低了11.4%的碰撞率,提升了复杂场景下的驾驶性能。
📝 摘要(中文)
本文提出了一种新颖的LLM提示强化学习范式,旨在解决现有方法过度依赖LLM输出而导致幻觉的问题。该范式利用LLM生成语义提示,用于状态增强和策略优化,辅助强化学习智能体进行运动规划。同时,强化学习智能体通过策略学习来抵消潜在的错误语义指示,从而实现卓越的驾驶性能。基于此,本文提出了HCRMP(LLM-Hinted Contextual Reinforcement Learning Motion Planner)架构,该架构包含增强语义表示模块以扩展状态空间,上下文稳定性锚定模块以利用知识库信息增强多评论家权重提示的可靠性,以及语义缓存模块以无缝集成LLM低频指导与RL高频控制。在CARLA上的大量实验验证了HCRMP强大的整体驾驶性能。在不同交通密度下的各种驾驶条件下,HCRMP的任务成功率高达80.3%。在安全关键的驾驶条件下,HCRMP显著降低了11.4%的碰撞率,有效提高了复杂场景下的驾驶性能。
🔬 方法详解
问题定义:现有基于LLM的自动驾驶方法过度依赖LLM的输出,但LLM本身存在幻觉问题,即生成不真实或不准确的信息。这些幻觉会直接影响自动驾驶策略的安全性和可靠性,尤其是在复杂和动态的交通环境中。因此,如何有效利用LLM的知识,同时避免其幻觉带来的负面影响,是本文要解决的核心问题。
核心思路:本文的核心思路是保持LLM和RL之间的相对独立性。LLM作为提示提供者,为RL智能体提供语义信息,但RL智能体通过自身的学习能力来验证和纠正LLM的提示。这种设计避免了RL策略完全依赖于LLM的输出,从而降低了幻觉带来的风险。同时,通过上下文信息和知识库的辅助,进一步增强了LLM提示的可靠性。
技术框架:HCRMP的整体架构包含三个主要模块:增强语义表示模块、上下文稳定性锚定模块和语义缓存模块。增强语义表示模块扩展了状态空间,将LLM提供的语义信息融入到RL智能体的状态表示中。上下文稳定性锚定模块利用知识库信息,增强多评论家权重提示的可靠性,减少幻觉的影响。语义缓存模块则负责将LLM的低频指导与RL的高频控制进行无缝集成,实现更平滑和稳定的驾驶行为。
关键创新:HCRMP的关键创新在于其LLM提示的强化学习范式,以及三个模块的协同工作。与现有方法不同,HCRMP并非直接将LLM的输出作为控制信号,而是将其作为提示信息,辅助RL智能体进行决策。这种设计降低了对LLM的依赖,提高了策略的鲁棒性。此外,上下文稳定性锚定模块和语义缓存模块的设计,进一步增强了LLM提示的可靠性和利用效率。
关键设计:增强语义表示模块通过将LLM提供的语义信息(例如,交通规则、驾驶意图等)编码到状态空间中,扩展了RL智能体的感知能力。上下文稳定性锚定模块使用知识库中的先验知识,对LLM提供的权重提示进行验证和校正,从而减少幻觉的影响。语义缓存模块则采用一种滑动平均的方法,将LLM的低频指导与RL的高频控制进行平滑过渡,避免了控制信号的突变。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HCRMP在CARLA模拟器中取得了显著的性能提升。在各种驾驶条件下,HCRMP的任务成功率高达80.3%,显著优于其他基线方法。在安全关键的驾驶条件下,HCRMP的碰撞率降低了11.4%,表明其在复杂场景下具有更高的安全性。这些结果验证了HCRMP框架的有效性和优越性。
🎯 应用场景
HCRMP框架具有广泛的应用前景,可应用于各种自动驾驶场景,尤其是在复杂和动态的交通环境中。该研究的成果可以提高自动驾驶系统的安全性、可靠性和智能化水平,加速自动驾驶技术的商业化落地。此外,该框架的设计思想也可以推广到其他需要结合LLM和RL的机器人控制任务中。
📄 摘要(原文)
Integrating Large Language Models (LLMs) with Reinforcement Learning (RL) can enhance autonomous driving (AD) performance in complex scenarios. However, current LLM-Dominated RL methods over-rely on LLM outputs, which are prone to hallucinations. Evaluations show that state-of-the-art LLM indicates a non-hallucination rate of only approximately 57.95% when assessed on essential driving-related tasks. Thus, in these methods, hallucinations from the LLM can directly jeopardize the performance of driving policies. This paper argues that maintaining relative independence between the LLM and the RL is vital for solving the hallucinations problem. Consequently, this paper is devoted to propose a novel LLM-Hinted RL paradigm. The LLM is used to generate semantic hints for state augmentation and policy optimization to assist RL agent in motion planning, while the RL agent counteracts potential erroneous semantic indications through policy learning to achieve excellent driving performance. Based on this paradigm, we propose the HCRMP (LLM-Hinted Contextual Reinforcement Learning Motion Planner) architecture, which is designed that includes Augmented Semantic Representation Module to extend state space. Contextual Stability Anchor Module enhances the reliability of multi-critic weight hints by utilizing information from the knowledge base. Semantic Cache Module is employed to seamlessly integrate LLM low-frequency guidance with RL high-frequency control. Extensive experiments in CARLA validate HCRMP's strong overall driving performance. HCRMP achieves a task success rate of up to 80.3% under diverse driving conditions with different traffic densities. Under safety-critical driving conditions, HCRMP significantly reduces the collision rate by 11.4%, which effectively improves the driving performance in complex scenarios.