From Grounding to Manipulation: Case Studies of Foundation Model Integration in Embodied Robotic Systems
作者: Xiuchao Sui, Daiying Tian, Qi Sun, Ruirui Chen, Dongkyu Choi, Kenneth Kwok, Soujanya Poria
分类: cs.RO
发布日期: 2025-05-21 (更新: 2025-11-03)
备注: EMNLP 2025 camera ready
💡 一句话要点
研究具身机器人系统中基础模型集成策略,解决复杂指令理解和动作生成问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身机器人 基础模型 视觉-语言模型 大型语言模型 指令跟随 物体操作 技能迁移 机器人控制
📋 核心要点
- 现有具身机器人系统在复杂指令理解和动态环境下的动作生成方面存在不足,缺乏对不同基础模型集成策略的深入研究。
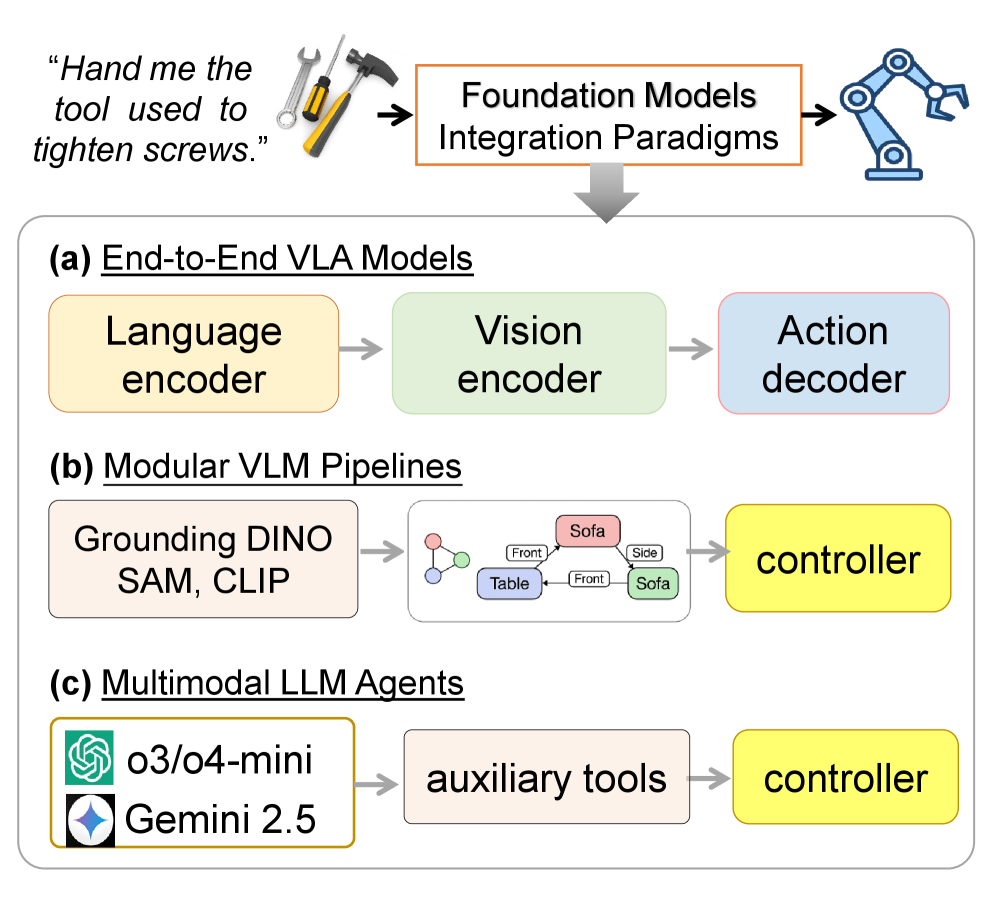
- 论文探索了端到端VLA模型和模块化VLM/LLM管道三种集成范例,旨在提升机器人对复杂指令的理解和动作生成能力。
- 通过指令定位和物体操作两个案例研究,论文评估了不同范例在零样本和少样本设置下的性能,揭示了泛化性和数据效率的权衡。
📝 摘要(中文)
基础模型(FMs)越来越多地被用于桥接具身智能体中的语言和动作,但不同FM集成策略的运行特性仍未得到充分探索,尤其是在复杂指令跟随和多功能动作生成方面,以及在不断变化的环境中。本文研究了三种构建机器人系统的范例:端到端视觉-语言-动作(VLA)模型(隐式地集成感知和规划),以及包含视觉-语言模型(VLMs)或多模态大型语言模型(LLMs)的模块化管道。我们通过两个重点案例研究评估这些范例:一个评估细粒度指令理解和跨模态消歧的复杂指令定位任务,以及一个通过VLA微调实现技能迁移的物体操作任务。我们在零样本和少样本设置下的实验揭示了泛化性和数据效率之间的权衡。通过探索性能极限,我们提炼了开发语言驱动的物理智能体的设计含义,并概述了在真实世界条件下,FM驱动的机器人技术面临的新兴挑战和机遇。
🔬 方法详解
问题定义:现有具身机器人系统在处理复杂指令和在变化的环境中生成动作时面临挑战。特别是,如何有效地将大型语言模型和视觉模型集成到机器人控制系统中,以实现更好的指令理解和动作泛化,是一个关键问题。现有的方法要么是端到端的,缺乏模块化和可解释性,要么是模块化的,但难以实现感知和动作的紧密集成。
核心思路:论文的核心思路是比较和分析三种不同的基础模型集成策略:端到端视觉-语言-动作(VLA)模型,以及两种模块化管道,分别使用视觉-语言模型(VLMs)和多模态大型语言模型(LLMs)。通过对比这些策略在复杂指令定位和物体操作任务中的表现,揭示它们在泛化性、数据效率和可解释性方面的权衡。
技术框架:论文研究了三种不同的机器人系统架构: 1. 端到端VLA模型:直接将视觉输入和语言指令映射到动作输出,隐式地学习感知和规划。 2. 模块化VLM管道:使用视觉-语言模型进行场景理解和目标识别,然后将结果传递给一个单独的动作规划器。 3. 模块化LLM管道:使用多模态大型语言模型来处理视觉输入和语言指令,生成动作序列或参数,然后由低级别的控制器执行。
关键创新:论文的关键创新在于对不同基础模型集成策略的系统性比较和分析。通过两个具体的案例研究,论文揭示了不同策略的优缺点,并为未来具身机器人系统的设计提供了指导。此外,论文还强调了在真实世界条件下,FM驱动的机器人技术面临的挑战和机遇。
关键设计:论文使用了两种不同的任务来评估不同的集成策略: 1. 复杂指令定位任务:评估模型对细粒度指令的理解和跨模态消歧能力。 2. 物体操作任务:评估模型通过VLA微调实现技能迁移的能力。 论文在零样本和少样本设置下进行了实验,并使用了标准的数据集和评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,端到端VLA模型在数据充足的情况下可以实现较好的性能,但在数据效率方面不如模块化方法。模块化LLM管道在零样本设置下表现出一定的泛化能力,但需要更多的微调才能达到与VLA模型相当的性能。这些结果揭示了不同集成策略在泛化性和数据效率之间的权衡。
🎯 应用场景
该研究成果可应用于各种需要复杂指令理解和灵活动作生成的机器人应用场景,例如家庭服务机器人、工业自动化机器人、医疗辅助机器人等。通过选择合适的模型集成策略,可以提升机器人在复杂环境中的适应性和智能化水平,从而更好地服务于人类。
📄 摘要(原文)
Foundation models (FMs) are increasingly used to bridge language and action in embodied agents, yet the operational characteristics of different FM integration strategies remain under-explored -- particularly for complex instruction following and versatile action generation in changing environments. This paper examines three paradigms for building robotic systems: end-to-end vision-language-action (VLA) models that implicitly integrate perception and planning, and modular pipelines incorporating either vision-language models (VLMs) or multimodal large language models (LLMs). We evaluate these paradigms through two focused case studies: a complex instruction grounding task assessing fine-grained instruction understanding and cross-modal disambiguation, and an object manipulation task targeting skill transfer via VLA finetuning. Our experiments in zero-shot and few-shot settings reveal trade-offs in generalization and data efficiency. By exploring performance limits, we distill design implications for developing language-driven physical agents and outline emerging challenges and opportunities for FM-powered robotics in real-world conditions.