Exploring the Limits of Vision-Language-Action Manipulations in Cross-task Generalization
作者: Jiaming Zhou, Ke Ye, Jiayi Liu, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, Junwei Liang
分类: cs.RO, cs.CV
发布日期: 2025-05-21 (更新: 2025-10-19)
备注: Project Page: https://jiaming-zhou.github.io/AGNOSTOS
💡 一句话要点
提出AGNOSTOS基准和X-ICM方法,提升VLA模型在机器人操作任务中的跨任务泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 机器人操作 跨任务泛化 上下文学习 大型语言模型 零样本学习 AGNOSTOS基准
📋 核心要点
- 现有VLA模型在跨任务泛化方面存在不足,难以适应开放世界中未见过的机器人操作任务。
- 提出X-ICM方法,利用大型语言模型和上下文学习,从已见任务中学习经验并迁移到未见任务。
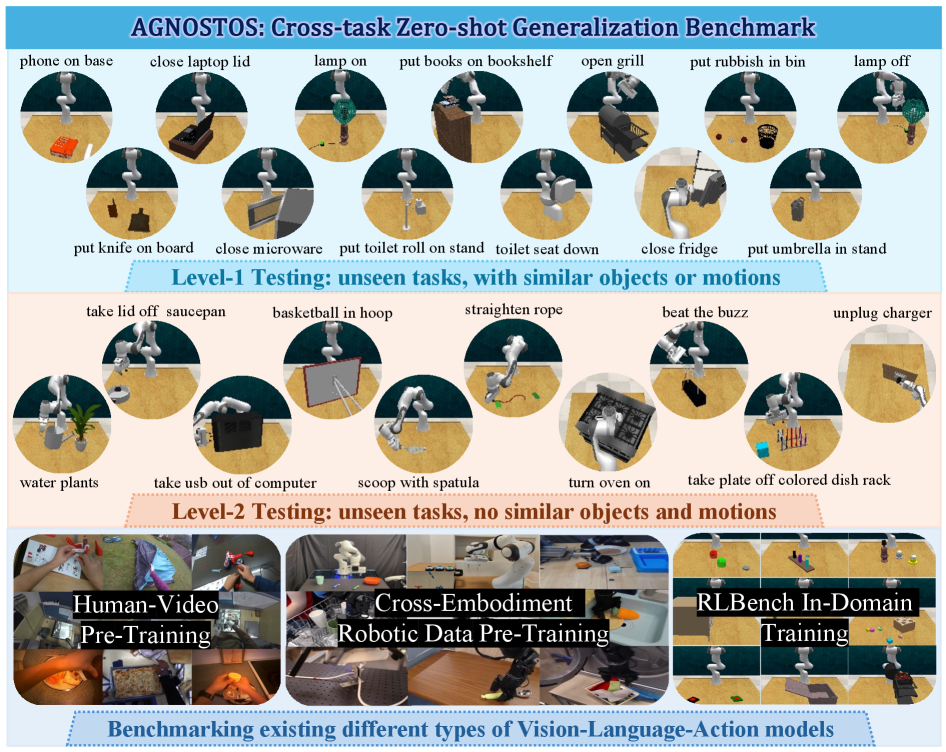
- 构建AGNOSTOS基准,包含23个未见操作任务,实验表明X-ICM显著提升了跨任务零样本泛化性能。
📝 摘要(中文)
本文旨在探索视觉-语言-动作(VLA)模型在未见任务中的泛化能力,这对于在开放世界环境中实现通用机器人操作至关重要。为此,我们提出了一个名为AGNOSTOS的新型模拟基准,用于严格评估操作任务中的跨任务零样本泛化能力。AGNOSTOS包含23个用于测试的未见操作任务,这些任务与常见的训练任务分布不同,并包含两个级别的泛化难度以评估鲁棒性。系统评估表明,当前的VLA模型虽然在多样化的数据集上进行训练,但难以有效地泛化到这些未见任务。为了克服这一限制,我们提出了一种跨任务上下文操作(X-ICM)方法,该方法利用大型语言模型(LLM),以来自已见任务的上下文演示为条件,来预测未见任务的动作序列。此外,我们还引入了一种动态引导的样本选择策略,通过捕获跨任务动态来识别相关的演示。在AGNOSTOS上,X-ICM显著提高了跨任务零样本泛化性能。我们相信AGNOSTOS和X-ICM将成为推进通用机器人操作的宝贵工具。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,虽然在特定数据集上表现良好,但在面对未见过的任务时,泛化能力显著下降。主要痛点在于模型难以将已学习的知识迁移到新的任务环境中,缺乏足够的适应性和鲁棒性。
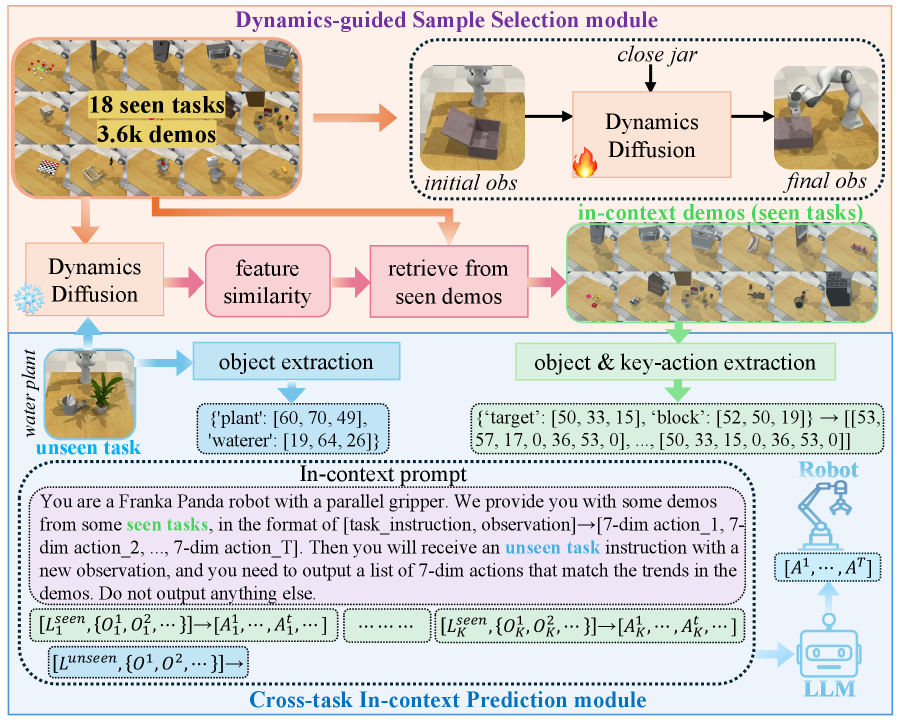
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大推理能力,结合上下文学习(In-Context Learning)的思想,将已见任务的经验迁移到未见任务中。通过提供少量已见任务的演示作为上下文,引导LLM预测未见任务的动作序列。这种方法的核心在于利用LLM的知识和推理能力,实现跨任务的知识迁移。
技术框架:X-ICM方法主要包含以下几个阶段:1) 上下文构建:从已见任务中选择合适的演示作为上下文。2) LLM推理:将上下文输入LLM,LLM根据上下文预测未见任务的动作序列。3) 动作执行:将LLM预测的动作序列发送给机器人执行。其中,动态引导的样本选择策略用于选择与未见任务动态特性相似的已见任务演示。
关键创新:本文的关键创新在于:1) 提出了Cross-Task In-Context Manipulation (X-ICM)方法,将上下文学习引入到机器人操作任务中,利用LLM实现跨任务的知识迁移。2) 提出了动态引导的样本选择策略,通过捕获跨任务动态,选择更相关的演示,提高泛化性能。3) 构建了AGNOSTOS基准,用于评估VLA模型在跨任务零样本泛化方面的性能。
关键设计:动态引导的样本选择策略是关键设计之一。该策略通过计算已见任务和未见任务之间的动态相似度,选择相似度最高的演示作为上下文。动态相似度的计算可能涉及到状态转移概率、奖励函数等因素。此外,LLM的选择和prompt的设计也会影响最终的性能。具体LLM的选择和prompt设计细节在论文中可能有所描述,这里无法给出具体参数。
🖼️ 关键图片
📊 实验亮点
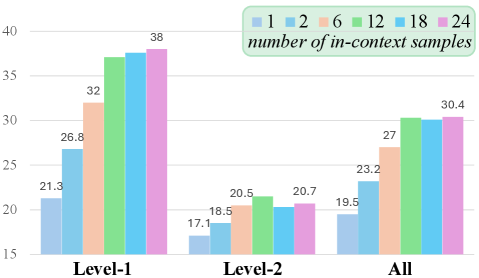
X-ICM方法在AGNOSTOS基准上显著提高了跨任务零样本泛化性能。具体而言,X-ICM在多个未见任务上取得了优于现有VLA模型的性能,证明了其有效性。动态引导的样本选择策略也起到了关键作用,进一步提升了泛化能力。具体的性能提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要机器人操作的场景,例如智能制造、家庭服务、医疗辅助等。通过提高机器人的跨任务泛化能力,可以使其更好地适应复杂多变的环境,完成各种不同的任务。未来,该技术有望实现通用机器人操作,使机器人能够像人类一样灵活地适应新的任务和环境。
📄 摘要(原文)
The generalization capabilities of vision-language-action (VLA) models to unseen tasks are crucial to achieving general-purpose robotic manipulation in open-world settings. However, the cross-task generalization capabilities of existing VLA models remain significantly underexplored. To address this gap, we introduce AGNOSTOS, a novel simulation benchmark designed to rigorously evaluate cross-task zero-shot generalization in manipulation. AGNOSTOS comprises 23 unseen manipulation tasks for testing, distinct from common training task distributions, and incorporates two levels of generalization difficulty to assess robustness. Our systematic evaluation reveals that current VLA models, despite being trained on diverse datasets, struggle to generalize effectively to these unseen tasks. To overcome this limitation, we propose Cross-Task In-Context Manipulation (X-ICM), a method that conditions large language models (LLMs) on in-context demonstrations from seen tasks to predict action sequences for unseen tasks. Additionally, we introduce a dynamics-guided sample selection strategy that identifies relevant demonstrations by capturing cross-task dynamics. On AGNOSTOS, X-ICM significantly improves cross-task zero-shot generalization performance over leading VLAs. We believe AGNOSTOS and X-ICM will serve as valuable tools for advancing general-purpose robotic manipulation.