Object-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation
作者: Yihang Li, Tianle Zhang, Xuelong Wei, Jiayi Li, Lin Zhao, Dongchi Huang, Zhirui Fang, Minhua Zheng, Wenjun Dai, Xiaodong He
分类: cs.RO, cs.AI
发布日期: 2025-05-21
💡 一句话要点
提出Object-Focus Actor,解决机器人灵巧操作中数据效率和泛化性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人灵巧操作 数据高效学习 泛化能力 物体中心策略 分层控制
📋 核心要点
- 现有机器人操作学习方法依赖大量人工演示,泛化能力不足,难以适应真实场景中复杂多样的物体位置和背景。
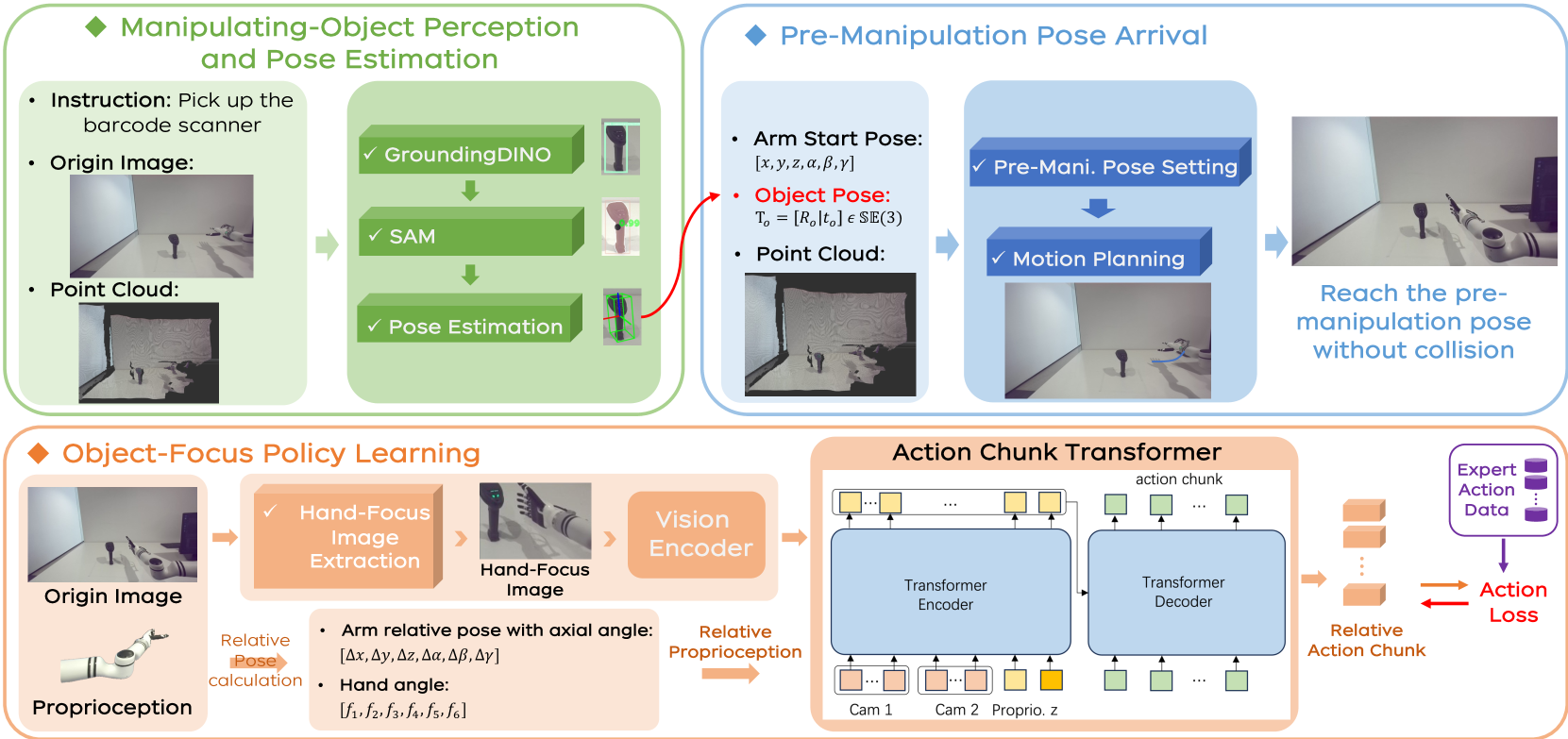
- OFA方法利用灵巧操作中末端轨迹的一致性,设计分层策略,首先进行物体感知和姿态估计,然后执行预操作姿态到达和OFA策略。
- 实验结果表明,OFA仅需少量演示数据(10次)即可在七个真实任务中实现优异的泛化性能,显著优于现有基线方法。
📝 摘要(中文)
本文提出了一种名为Object-Focus Actor (OFA) 的新型数据高效方法,用于实现广义的灵巧操作。OFA 利用灵巧操作任务中观察到的一致末端轨迹,从而实现高效的策略训练。该方法采用分层流程:物体感知和姿态估计、预操作姿态到达和OFA策略执行。即使在不同的背景和位置布局中,此过程也能确保操作的专注性和效率。在七个任务中进行的全面真实世界实验表明,OFA 在位置和背景泛化测试中均显着优于基线方法。值得注意的是,OFA 仅需 10 次演示即可实现稳健的性能,突出了其数据效率。
🔬 方法详解
问题定义:现有机器人灵巧操作学习方法通常需要大量的人工示教数据才能训练出有效的策略,并且在面对新的场景和物体摆放时,泛化能力较差。这限制了它们在真实世界复杂任务中的应用,例如在不同背景和位置布局下操作物体。
核心思路:OFA的核心思路是利用灵巧操作任务中末端执行器轨迹的一致性。尽管物体的初始位置和背景可能不同,但为了完成相同的操作,末端执行器的运动轨迹通常是相似的。通过关注物体本身和操作的末端轨迹,可以减少对环境变化的依赖,从而提高泛化能力。
技术框架:OFA采用分层流水线结构,包含以下三个主要模块:1) 物体感知和姿态估计:使用视觉算法识别目标物体并估计其在空间中的姿态。2) 预操作姿态到达:规划并控制机器人到达一个合适的预操作姿态,为后续的灵巧操作做准备。3) OFA策略执行:根据当前状态和目标物体的姿态,执行学习到的灵巧操作策略,完成任务。
关键创新:OFA的关键创新在于其策略学习方式,它专注于学习物体操作的末端轨迹,而不是直接学习从原始图像到动作的映射。这种方法可以有效地利用少量数据,并提高策略的泛化能力。此外,分层结构的设计也使得整个系统更加模块化和易于维护。
关键设计:OFA策略的具体实现细节未知,论文中没有详细描述其网络结构、损失函数或参数设置。但是,可以推断,该策略可能使用了某种形式的强化学习或模仿学习,并结合了轨迹规划技术。预操作姿态到达模块可能使用了逆运动学或运动规划算法。
🖼️ 关键图片


📊 实验亮点
OFA在七个真实世界的灵巧操作任务中进行了评估,实验结果表明,OFA在位置和背景泛化测试中均显著优于基线方法。特别值得一提的是,OFA仅使用10次演示数据即可实现稳健的性能,这突出了其数据效率。具体性能提升数据未知,论文中没有给出详细的数值对比。
🎯 应用场景
OFA方法在机器人灵巧操作领域具有广泛的应用前景,例如在家庭服务机器人中,可以用于完成各种日常任务,如物品整理、烹饪等。在工业自动化领域,可以用于实现更灵活和高效的生产线,例如在装配、包装等环节。此外,该方法还可以应用于医疗机器人领域,辅助医生进行手术操作。
📄 摘要(原文)
Robot manipulation learning from human demonstrations offers a rapid means to acquire skills but often lacks generalization across diverse scenes and object placements. This limitation hinders real-world applications, particularly in complex tasks requiring dexterous manipulation. Vision-Language-Action (VLA) paradigm leverages large-scale data to enhance generalization. However, due to data scarcity, VLA's performance remains limited. In this work, we introduce Object-Focus Actor (OFA), a novel, data-efficient approach for generalized dexterous manipulation. OFA exploits the consistent end trajectories observed in dexterous manipulation tasks, allowing for efficient policy training. Our method employs a hierarchical pipeline: object perception and pose estimation, pre-manipulation pose arrival and OFA policy execution. This process ensures that the manipulation is focused and efficient, even in varied backgrounds and positional layout. Comprehensive real-world experiments across seven tasks demonstrate that OFA significantly outperforms baseline methods in both positional and background generalization tests. Notably, OFA achieves robust performance with only 10 demonstrations, highlighting its data efficiency.