Time Reversal Symmetry for Efficient Robotic Manipulations in Deep Reinforcement Learning
作者: Yunpeng Jiang, Jianshu Hu, Paul Weng, Yutong Ban
分类: cs.RO, cs.LG
发布日期: 2025-05-20 (更新: 2025-10-21)
备注: Accepted in NeurIPS 2025
💡 一句话要点
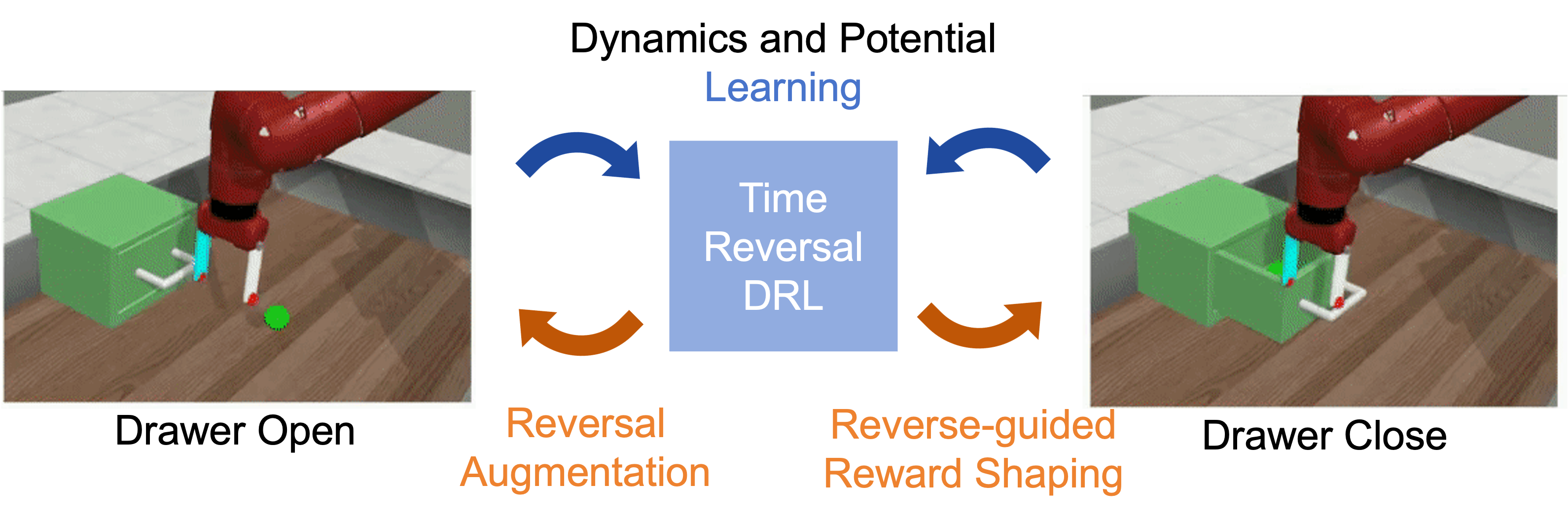
提出TR-DRL框架,利用时间反演对称性提升机器人操作深度强化学习的样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 机器人操作 时间反演对称性 样本效率 奖励塑造
📋 核心要点
- 现有深度强化学习方法主要关注空间对称性,忽略了机器人任务中常见的时间对称性。
- TR-DRL框架利用轨迹反演增强和时间反演引导的奖励塑造,提升时间对称任务的学习效率。
- 实验表明,TR-DRL在Robosuite和MetaWorld基准测试中,样本效率和最终性能均优于基线方法。
📝 摘要(中文)
本文提出了一种时间反演对称性增强的深度强化学习框架(TR-DRL),旨在提高机器人操作任务中的样本效率。该方法结合了轨迹反演增强和时间反演引导的奖励塑造,以有效解决时间对称任务。TR-DRL通过提出的动态一致性滤波器识别完全可逆的转移,并生成反向转移来扩充训练数据。对于部分可逆的转移,根据反向任务的成功轨迹应用奖励塑造来指导学习。在Robosuite和MetaWorld基准测试中的大量实验表明,TR-DRL在单任务和多任务设置中均有效,与基线方法相比,实现了更高的样本效率和更强的最终性能。
🔬 方法详解
问题定义:现有深度强化学习方法在机器人操作任务中,主要利用空间对称性来提高样本效率,而忽略了时间对称性。许多机器人任务,如开门和关门,具有时间上的可逆性,即正向执行和反向执行在动力学上存在关联。如何有效利用这种时间对称性来提升强化学习的效率是一个关键问题。
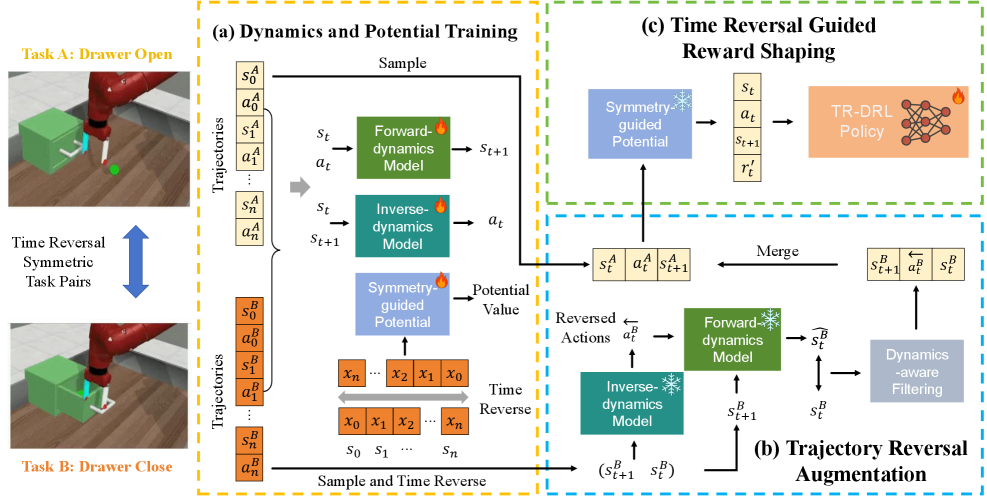
核心思路:本文的核心思路是利用时间反演对称性来增强深度强化学习的训练过程。具体来说,通过识别可逆的轨迹片段,并将其反转后作为新的训练数据,从而增加训练样本的多样性。此外,对于部分可逆的轨迹,通过奖励塑造来引导智能体学习,使其能够更好地利用时间对称性。
技术框架:TR-DRL框架主要包含两个核心模块:轨迹反演增强和时间反演引导的奖励塑造。首先,通过动态一致性滤波器识别完全可逆的转移。然后,将这些转移进行反转,生成新的训练数据,从而进行轨迹反演增强。对于部分可逆的转移,则利用时间反演引导的奖励塑造,根据反向任务的成功轨迹来调整奖励函数,引导智能体学习。
关键创新:本文最重要的技术创新点在于提出了利用时间反演对称性来增强深度强化学习的方法。与现有方法主要关注空间对称性不同,本文关注时间对称性,并设计了相应的算法来利用这种对称性。动态一致性滤波器和时间反演引导的奖励塑造是实现这一目标的关键技术。
关键设计:动态一致性滤波器用于判断一个转移是否是完全可逆的,其具体实现方式未知(论文未详细说明)。时间反演引导的奖励塑造的具体形式未知(论文未详细说明),但其目标是根据反向任务的成功轨迹来调整奖励函数,引导智能体学习。具体的网络结构和损失函数等细节未知(论文未详细说明)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TR-DRL在Robosuite和MetaWorld基准测试中均取得了显著的性能提升。与基线方法相比,TR-DRL在样本效率和最终性能方面均有提高。具体提升幅度未知(论文未提供具体数值),但实验结果表明TR-DRL是一种有效的利用时间对称性的方法。
🎯 应用场景
该研究成果可应用于各种具有时间对称性的机器人操作任务,例如装配、拆卸、开关等。通过提高样本效率,可以降低机器人学习的成本,加速机器人在复杂环境中的应用。此外,该方法还可以推广到其他领域,例如控制和优化等。
📄 摘要(原文)
Symmetry is pervasive in robotics and has been widely exploited to improve sample efficiency in deep reinforcement learning (DRL). However, existing approaches primarily focus on spatial symmetries, such as reflection, rotation, and translation, while largely neglecting temporal symmetries. To address this gap, we explore time reversal symmetry, a form of temporal symmetry commonly found in robotics tasks such as door opening and closing. We propose Time Reversal symmetry enhanced Deep Reinforcement Learning (TR-DRL), a framework that combines trajectory reversal augmentation and time reversal guided reward shaping to efficiently solve temporally symmetric tasks. Our method generates reversed transitions from fully reversible transitions, identified by a proposed dynamics-consistent filter, to augment the training data. For partially reversible transitions, we apply reward shaping to guide learning, according to successful trajectories from the reversed task. Extensive experiments on the Robosuite and MetaWorld benchmarks demonstrate that TR-DRL is effective in both single-task and multi-task settings, achieving higher sample efficiency and stronger final performance compared to baseline methods.