InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning
作者: Ji Zhang, Shihan Wu, Xu Luo, Hao Wu, Lianli Gao, Heng Tao Shen, Jingkuan Song
分类: cs.RO
发布日期: 2025-05-20 (更新: 2025-09-29)
💡 一句话要点
InSpire:通过内禀空间推理增强视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 空间推理 机器人 泛化能力 虚假相关性
📋 核心要点
- 现有视觉-语言-动作模型容易将任务无关的视觉特征与动作关联,导致泛化能力不足。
- InSpire通过引入内禀空间推理,促使模型关注物体相对于机器人的空间关系,从而减轻虚假相关性的影响。
- 实验表明,InSpire能够有效提升VLA在模拟和真实环境中的性能,且无需额外训练数据。
📝 摘要(中文)
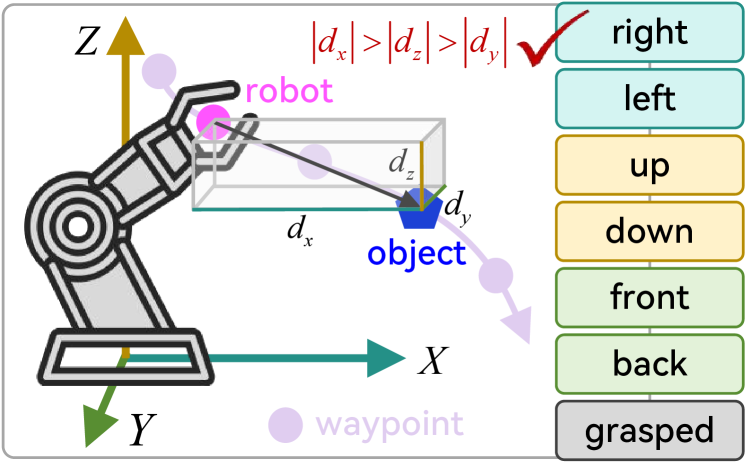
视觉-语言-动作模型(VLA)利用预训练的视觉-语言模型(VLM)将语言指令和视觉观察映射到原始的低级动作,在实现通用机器人系统方面具有巨大的潜力。然而,现有的VLA容易将任务无关的视觉特征与动作错误地关联起来,限制了其在训练数据之外的泛化能力。为了解决这个挑战,我们提出了一种内禀空间推理(InSpire)方法,它通过增强VLA的空间推理能力来减轻虚假相关性的不利影响。具体来说,InSpire通过在语言指令前添加问题“相对于机器人,[物体]在哪个方向?”来将VLA的注意力重定向到任务相关的因素,并将答案“右/左/上/下/前/后/抓取”和预测的动作与ground-truth对齐。值得注意的是,InSpire可以作为一个插件来增强现有的自回归VLA,无需额外的训练数据或与其他大型模型交互。在模拟和真实环境中的大量实验结果证明了我们方法的有效性和灵活性。
🔬 方法详解
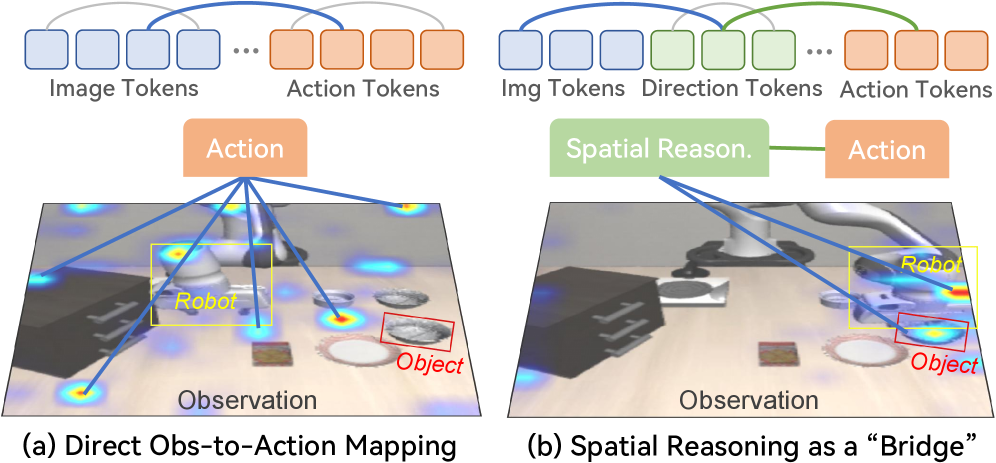
问题定义:现有的视觉-语言-动作模型(VLA)在将语言指令和视觉信息映射到机器人动作时,容易受到虚假相关性的影响。这意味着模型可能会学习到一些与任务无关的视觉特征与动作之间的关联,导致在新的环境中泛化能力下降。例如,模型可能错误地将背景中的某个物体与特定的动作联系起来,而不是真正理解指令中目标物体与机器人之间的空间关系。
核心思路:InSpire的核心思路是通过显式地引入空间推理,迫使模型关注任务相关的空间信息。具体来说,它通过在语言指令中添加一个关于目标物体相对于机器人位置的问题,来引导模型学习物体与机器人之间的空间关系。这种方式可以有效地减少模型对虚假相关性的依赖,从而提高其泛化能力。
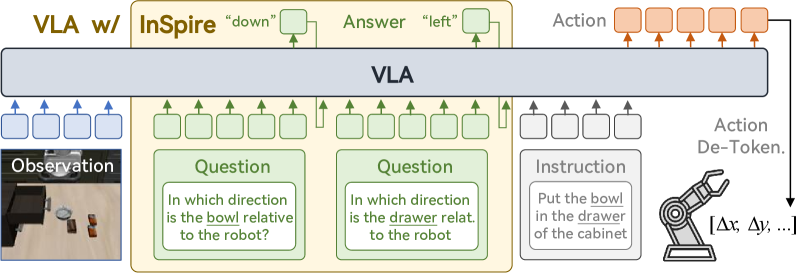
技术框架:InSpire可以作为一个插件集成到现有的自回归VLA模型中。其主要流程如下:1) 在原始的语言指令前添加一个空间推理问题,例如“相对于机器人,[物体]在哪个方向?”。2) 模型根据修改后的指令和视觉输入预测动作序列。3) 在训练过程中,将模型预测的动作与ground-truth动作对齐,同时也将模型对空间推理问题的答案(例如“右/左/上/下/前/后/抓取”)与ground-truth对齐。
关键创新:InSpire的关键创新在于其简单而有效的设计,它无需额外的训练数据或与其他大型模型交互,即可显著提升VLA的空间推理能力和泛化能力。通过显式地引入空间推理问题,InSpire能够有效地引导模型关注任务相关的空间信息,从而减少对虚假相关性的依赖。
关键设计:InSpire的关键设计在于空间推理问题的构建和答案的对齐方式。空间推理问题被设计成一个简单而明确的问题,例如“相对于机器人,[物体]在哪个方向?”,这可以有效地引导模型关注物体与机器人之间的空间关系。答案的对齐方式也很重要,通过将模型预测的答案与ground-truth对齐,可以确保模型学习到正确的空间关系。
🖼️ 关键图片
📊 实验亮点
InSpire在模拟和真实环境中的实验结果均表现出色。在模拟环境中,InSpire显著提高了VLA的成功率,尤其是在需要复杂空间推理的任务中。在真实环境中,InSpire也展现出了良好的泛化能力,能够成功地完成各种机器人操作任务。实验结果表明,InSpire能够有效地提升VLA的空间推理能力和泛化能力,且无需额外的训练数据或与其他大型模型交互。
🎯 应用场景
InSpire具有广泛的应用前景,可以应用于各种需要机器人与环境交互的场景,例如家庭服务机器人、工业自动化机器人、医疗辅助机器人等。通过提高机器人的空间推理能力和泛化能力,InSpire可以使机器人更好地理解人类指令,并在复杂的环境中执行各种任务,从而提高机器人的实用性和智能化水平。未来,InSpire还可以与其他技术相结合,例如强化学习、模仿学习等,进一步提升机器人的性能。
📄 摘要(原文)
Leveraging pretrained Vision-Language Models (VLMs) to map language instruction and visual observations to raw low-level actions, Vision-Language-Action models (VLAs) hold great promise for achieving general-purpose robotic systems. Despite their advancements, existing VLAs tend to spuriously correlate task-irrelevant visual features with actions, limiting their generalization capacity beyond the training data. To tackle this challenge, we propose Intrinsic Spatial Reasoning (InSpire), a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs. Specifically, InSpire redirects the VLA's attention to task-relevant factors by prepending the question "In which direction is the [object] relative to the robot?" to the language instruction and aligning the answer "right/left/up/down/front/back/grasped" and predicted actions with ground-truth. Notably, InSpire can be used as a plugin to enhance existing autoregressive VLAs, requiring no extra training data or interaction with other large models. Extensive experimental results in both simulation and real-world environments demonstrate the effectiveness and flexibility of our approach.