TD-GRPC: Temporal Difference Learning with Group Relative Policy Constraint for Humanoid Locomotion
作者: Khang Nguyen, Khai Nguyen, An T. Le, Jan Peters, Manfred Huber, Ngo Anh Vien, Minh Nhat Vu
分类: cs.RO
发布日期: 2025-05-19
💡 一句话要点
提出TD-GRPC,结合时序差分学习与群组相对策略约束,提升人形机器人运动控制的稳定性和鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 时序差分学习 模型预测控制 策略约束 群组相对策略优化 运动控制
📋 核心要点
- 人形机器人运动控制面临动力学不稳定、接触交互复杂和分布偏移等挑战,传统强化学习方法难以有效应对。
- TD-GRPC结合群组相对策略优化和显式策略约束,在潜在策略空间施加信任域,保证规划先验和学习轨迹的一致性。
- 在Unitree H1-2人形机器人上的仿真实验表明,TD-GRPC在稳定性和策略鲁棒性方面均有提升,并提高了采样效率。
📝 摘要(中文)
在人形机器人运动等高维控制任务中,强化学习算法面临着不稳定的动力学、复杂的接触交互以及训练过程中分布偏移的挑战。时序差分模型预测控制(TD-MPC)等基于模型的方法通过结合短视界规划和基于价值的学习,在基础运动任务上展现了潜力。然而,这些方法在解决由离策略更新引入的策略不匹配和不稳定性方面仍然无效。因此,本文提出了时序差分群组相对策略约束(TD-GRPC),它是TD-MPC框架的扩展,统一了群组相对策略优化(GRPO)和显式策略约束(PC)。TD-GRPC在潜在策略空间中应用信任域约束,以保持规划先验和学习轨迹之间的一致性,同时利用群组相对排序来评估和保持候选轨迹的物理可行性。与现有方法不同,TD-GRPC无需修改底层规划器即可实现鲁棒的运动,从而实现灵活的规划和策略学习。我们在一个运动任务套件(从基本行走到着重动态运动)上,在26自由度Unitree H1-2人形机器人上验证了该方法。仿真结果表明,TD-GRPC在复杂人形机器人控制任务的训练中,提高了稳定性和策略鲁棒性,并具有采样效率。
🔬 方法详解
问题定义:论文旨在解决人形机器人运动控制中,由于强化学习的离策略更新导致的策略不匹配和不稳定性问题。现有的TD-MPC方法虽然结合了规划和学习,但在处理复杂运动和保证策略一致性方面存在不足,容易产生不稳定的控制策略。
核心思路:论文的核心思路是将群组相对策略优化(GRPO)与显式策略约束(PC)相结合,在TD-MPC框架下引入TD-GRPC。通过在潜在策略空间中施加信任域约束,限制策略的更新幅度,从而保持规划先验和学习轨迹之间的一致性,提高策略的稳定性。同时,利用群组相对排序来评估和保留物理上可行的轨迹。
技术框架:TD-GRPC框架基于TD-MPC,主要包含以下几个模块:1) 短视界规划器:生成候选轨迹;2) 价值函数学习器:评估轨迹的价值;3) 群组相对策略优化器:利用GRPO对策略进行优化,并施加策略约束;4) 策略更新模块:根据优化后的策略更新控制策略。整体流程是,首先通过规划器生成多个候选轨迹,然后利用价值函数评估这些轨迹,接着使用GRPO对策略进行优化,并在潜在策略空间中施加信任域约束,最后更新控制策略。
关键创新:TD-GRPC的关键创新在于将GRPO与显式策略约束相结合,并将其应用于TD-MPC框架。与传统方法相比,TD-GRPC无需修改底层规划器,即可实现鲁棒的运动控制。通过在潜在策略空间中施加信任域约束,有效地限制了策略的更新幅度,从而提高了策略的稳定性。此外,利用群组相对排序来评估和保留物理上可行的轨迹,进一步提高了控制策略的鲁棒性。
关键设计:TD-GRPC的关键设计包括:1) 潜在策略空间的定义:将策略映射到低维的潜在空间,并在该空间中施加信任域约束;2) 信任域约束的实现:使用KL散度或其他距离度量来衡量策略之间的差异,并限制其更新幅度;3) 群组相对排序的实现:根据轨迹的物理可行性和价值,对轨迹进行排序,并选择排名靠前的轨迹进行学习;4) 损失函数的设计:损失函数包含价值函数误差项、策略约束项和群组相对排序项,用于优化策略。
🖼️ 关键图片


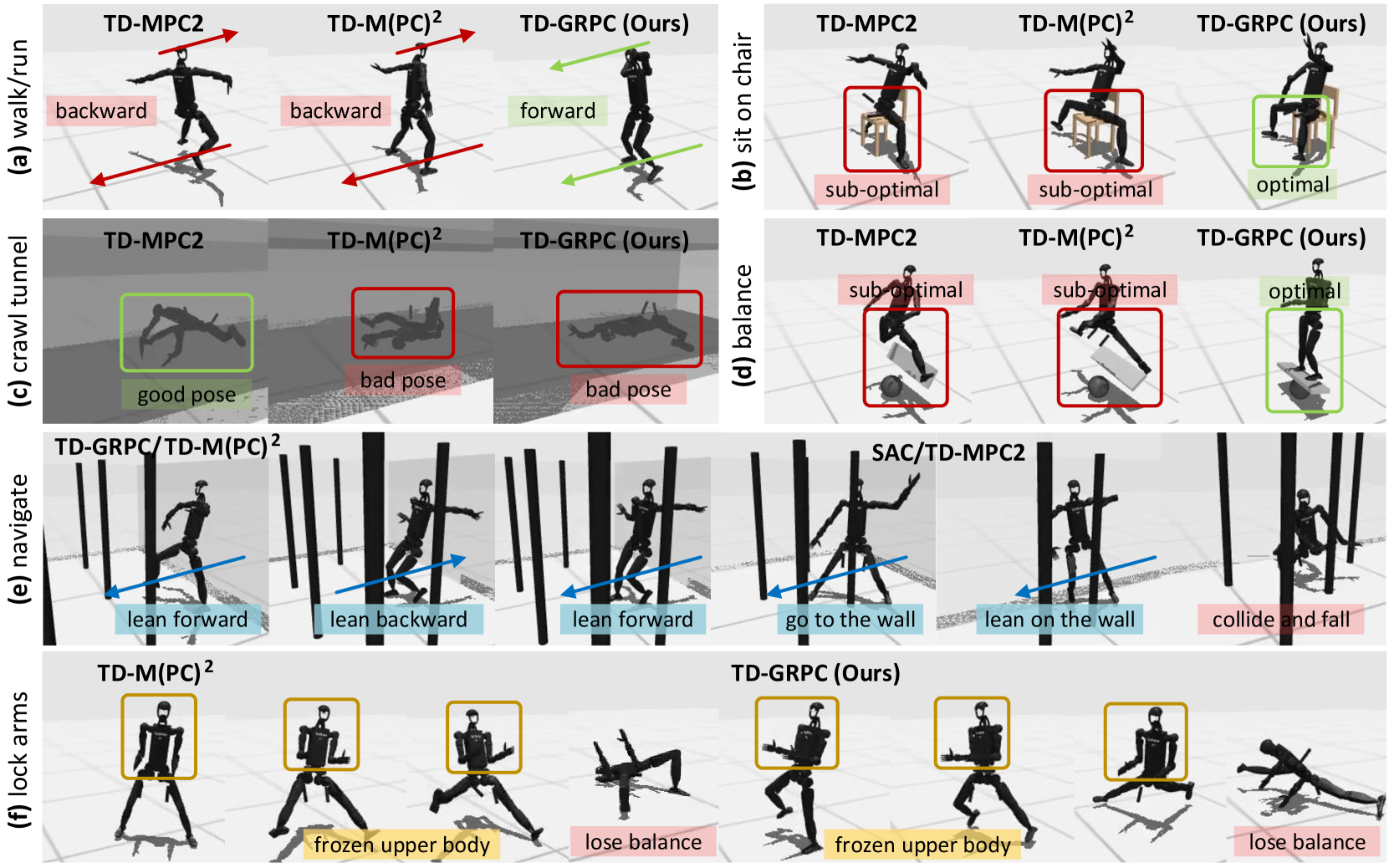
📊 实验亮点
在Unitree H1-2人形机器人上的仿真实验表明,TD-GRPC在复杂运动控制任务中表现出显著的优势。与基线方法相比,TD-GRPC能够生成更稳定、更鲁棒的运动策略,并提高了采样效率。具体而言,TD-GRPC在行走、跑步和跳跃等任务中均取得了更好的性能,并且能够适应不同的地形和环境。
🎯 应用场景
TD-GRPC在人形机器人运动控制领域具有广泛的应用前景,可用于开发更稳定、更鲁棒的机器人控制系统。该方法可以应用于各种复杂地形和任务,例如灾难救援、物流搬运、家庭服务等。此外,TD-GRPC的思想也可以推广到其他高维控制任务中,例如自动驾驶、机械臂控制等,具有重要的实际价值和未来影响。
📄 摘要(原文)
Robot learning in high-dimensional control settings, such as humanoid locomotion, presents persistent challenges for reinforcement learning (RL) algorithms due to unstable dynamics, complex contact interactions, and sensitivity to distributional shifts during training. Model-based methods, \textit{e.g.}, Temporal-Difference Model Predictive Control (TD-MPC), have demonstrated promising results by combining short-horizon planning with value-based learning, enabling efficient solutions for basic locomotion tasks. However, these approaches remain ineffective in addressing policy mismatch and instability introduced by off-policy updates. Thus, in this work, we introduce Temporal-Difference Group Relative Policy Constraint (TD-GRPC), an extension of the TD-MPC framework that unifies Group Relative Policy Optimization (GRPO) with explicit Policy Constraints (PC). TD-GRPC applies a trust-region constraint in the latent policy space to maintain consistency between the planning priors and learned rollouts, while leveraging group-relative ranking to assess and preserve the physical feasibility of candidate trajectories. Unlike prior methods, TD-GRPC achieves robust motions without modifying the underlying planner, enabling flexible planning and policy learning. We validate our method across a locomotion task suite ranging from basic walking to highly dynamic movements on the 26-DoF Unitree H1-2 humanoid robot. Through simulation results, TD-GRPC demonstrates its improvements in stability and policy robustness with sampling efficiency while training for complex humanoid control tasks.