GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
作者: Abhay Deshpande, Yuquan Deng, Arijit Ray, Jordi Salvador, Winson Han, Jiafei Duan, Kuo-Hao Zeng, Yuke Zhu, Ranjay Krishna, Rose Hendrix
分类: cs.RO
发布日期: 2025-05-19 (更新: 2025-09-12)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
GraspMolmo:基于大规模合成数据的通用任务导向抓取模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 任务导向抓取 视觉语言模型 大规模合成数据 机器人操作 开放词汇
📋 核心要点
- 现有任务导向抓取方法受限于小规模数据集、简单语言描述和缺乏真实场景复杂度的限制。
- GraspMolmo通过在PRISM大规模合成数据集上微调Molmo视觉-语言模型,实现对开放词汇指令和物体的泛化。
- 实验表明,GraspMolmo在真实世界复杂任务中显著优于现有方法,预测成功率达到70%,并具备零样本双手抓取能力。
📝 摘要(中文)
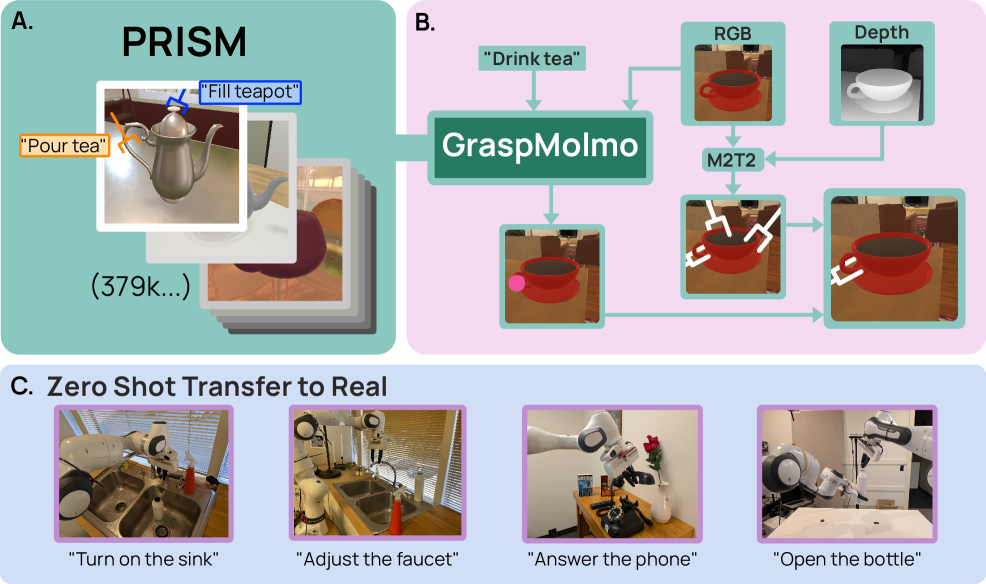
本文提出GraspMolmo,一个通用的开放词汇任务导向抓取(TOG)模型。GraspMolmo能够根据自然语言指令和单个RGB-D图像预测语义上合适的、稳定的抓取姿态。例如,给定指令“给我倒茶”,GraspMolmo会选择茶壶的把手而不是壶身进行抓取。与之前受限于小数据集、简单语言和整洁场景的TOG方法不同,GraspMolmo从PRISM学习,PRISM是一个包含37.9万个样本的大规模合成数据集,具有杂乱的环境和多样、真实的task描述。我们在该数据上微调Molmo视觉-语言模型,使GraspMolmo能够泛化到新的开放词汇指令和物体。在具有挑战性的真实世界评估中,GraspMolmo取得了最先进的结果,在复杂任务上的预测成功率为70%,而次优替代方案的成功率为35%。GraspMolmo还成功地展示了零样本预测语义正确的双手抓取的能力。我们发布了我们的合成数据集、代码、模型和基准,以加速任务语义机器人操作的研究。
🔬 方法详解
问题定义:论文旨在解决机器人任务导向抓取问题,即根据自然语言指令和视觉输入,使机器人能够抓取场景中合适的物体部分以完成特定任务。现有方法的痛点在于依赖小规模、简单的数据集,导致模型泛化能力差,无法处理复杂的真实场景和开放词汇指令。
核心思路:论文的核心思路是利用大规模合成数据来训练视觉-语言模型,从而提升模型在真实场景中的泛化能力。通过构建包含大量多样化场景和任务描述的合成数据集PRISM,并在此基础上微调预训练的Molmo模型,使模型能够学习到更丰富的语义信息和抓取策略。
技术框架:GraspMolmo的技术框架主要包含两个部分:大规模合成数据集PRISM的生成和Molmo视觉-语言模型的微调。PRISM数据集包含各种杂乱的场景和多样化的任务描述,以及对应的抓取标注。Molmo模型是一个预训练的视觉-语言模型,通过在PRISM数据集上进行微调,使其能够根据自然语言指令和RGB-D图像预测合适的抓取姿态。
关键创新:论文的关键创新在于构建了大规模、高质量的合成数据集PRISM,并利用该数据集来训练视觉-语言模型。与以往方法相比,PRISM数据集具有更大的规模、更丰富的场景和任务描述,能够更好地模拟真实世界的复杂性。此外,通过微调预训练的Molmo模型,可以有效地利用已有的知识,加速模型的训练过程并提升模型的泛化能力。
关键设计:PRISM数据集的生成过程采用了程序化生成技术,可以自动生成大量的多样化场景和任务描述。在Molmo模型的微调过程中,采用了对比学习损失函数,鼓励模型学习到语义相关的抓取姿态。此外,论文还设计了一种新的评估指标,用于评估模型在真实场景中的抓取性能。
🖼️ 关键图片


📊 实验亮点
GraspMolmo在真实世界复杂任务上的预测成功率达到70%,显著优于次优替代方案的35%,表明其在泛化能力和抓取性能方面具有显著优势。此外,GraspMolmo还成功展示了零样本预测语义正确的双手抓取的能力,进一步验证了其在复杂操作任务中的潜力。
🎯 应用场景
GraspMolmo在机器人自动化领域具有广泛的应用前景,例如智能家居服务机器人、工业自动化生产线、医疗辅助机器人等。该技术可以使机器人能够理解人类的指令,并自主完成复杂的抓取任务,从而提高生产效率和服务质量。未来,该技术还可以应用于灾难救援、太空探索等领域,帮助人类完成危险或困难的任务。
📄 摘要(原文)
We present GrasMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at https://abhaybd.github.io/GraspMolmo/.