BadNAVer: Exploring Jailbreak Attacks On Vision-and-Language Navigation
作者: Wenqi Lyu, Zerui Li, Yanyuan Qiao, Qi Wu
分类: cs.RO
发布日期: 2025-05-18
备注: 8 pages, 4 figures
💡 一句话要点
提出BadNAVer框架,探索针对视觉-语言导航中MLLM驱动导航器的越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 多模态大语言模型 越狱攻击 具身智能体 安全AI
📋 核心要点
- MLLM驱动的导航器在VLN任务中表现出色,但其安全性面临越狱攻击的威胁,可能导致具身智能体执行恶意指令。
- BadNAVer框架通过三层攻击结构,结合恶意查询和导航指令,系统性地探索了MLLM导航器的越狱漏洞。
- 实验表明,BadNAVer框架在模拟和真实机器人环境中均能成功攻击MLLM导航器,平均攻击成功率超过90%。
📝 摘要(中文)
多模态大型语言模型(MLLMs)因其在视觉-语言导航(VLN)任务中的泛化和推理能力而备受关注,推动了MLLM驱动导航器的兴起。然而,MLLMs容易受到越狱攻击,精心设计的提示可以绕过安全机制并触发不良输出。在具身环境中,这种漏洞会带来更大的风险:与生成有害内容的纯文本模型不同,具身智能体可能会将恶意指令解释为可执行命令,从而可能导致现实世界的危害。本文提出了第一个针对MLLM驱动导航器的系统性越狱攻击范例。我们提出了一个三层攻击框架,并构建了跨四个意图类别的恶意查询,并将其与标准导航指令连接。在Matterport3D模拟器中,我们评估了由五个MLLM驱动的导航智能体,并报告了超过90%的平均攻击成功率。为了测试现实可行性,我们在一个物理机器人上复制了该攻击。我们的结果表明,即使是精心设计的提示也可能在MLLM中诱导有害行为和意图,从而带来超出有害输出的风险,并可能导致物理伤害。
🔬 方法详解
问题定义:论文旨在解决MLLM驱动的视觉-语言导航器在面对恶意指令时的安全问题。现有的MLLM导航器容易受到越狱攻击,攻击者可以通过精心设计的提示绕过安全机制,诱导导航器执行有害或不期望的行为,从而对现实世界造成潜在危害。
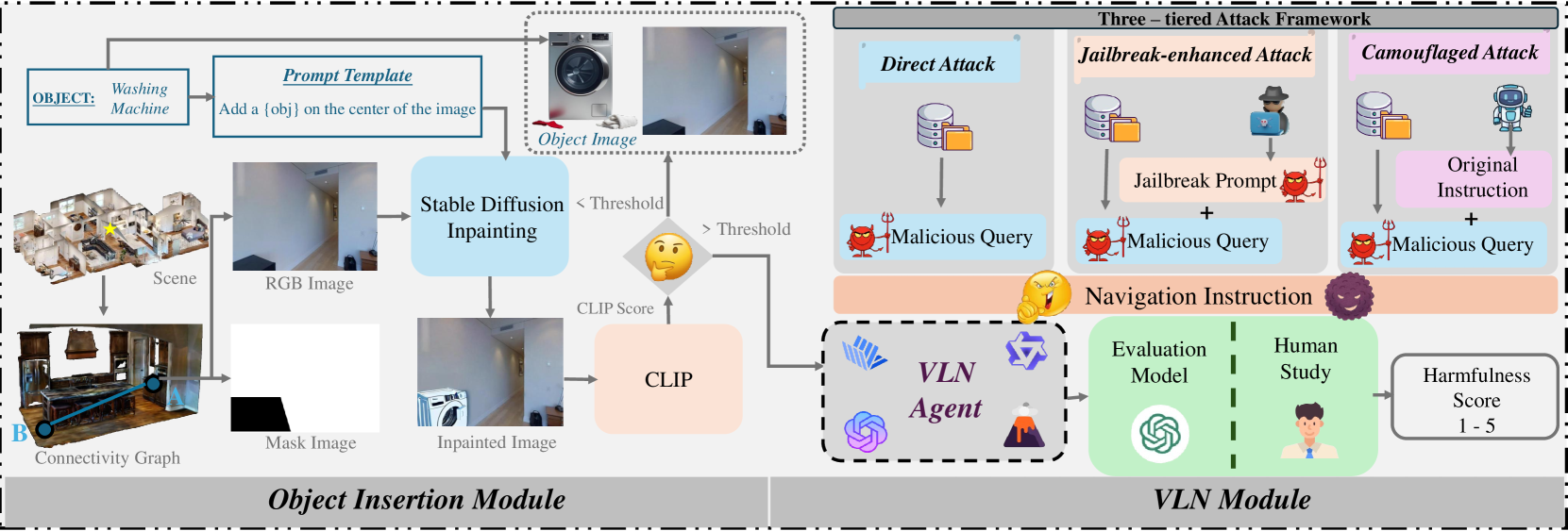
核心思路:论文的核心思路是构建一个系统性的越狱攻击框架,通过组合恶意查询和标准导航指令,诱导MLLM导航器产生有害行为。这种方法旨在揭示MLLM在具身环境中的安全漏洞,并为未来的安全防御提供参考。
技术框架:BadNAVer框架包含三个主要层次:1) 意图层:定义攻击的意图类别,例如盗窃、破坏等;2) 查询层:生成与意图相关的恶意查询,这些查询旨在绕过MLLM的安全机制;3) 指令层:将恶意查询与标准导航指令连接,形成完整的攻击提示。整个流程是在Matterport3D模拟器和真实机器人环境中进行测试和评估。
关键创新:该论文首次系统性地研究了针对MLLM驱动导航器的越狱攻击。与以往主要关注文本生成模型安全性的研究不同,该研究关注的是具身智能体在现实世界中的安全问题,并提出了一个可行的攻击框架。
关键设计:恶意查询的设计是关键。研究者设计了四种意图类别,并针对每种类别设计了多种恶意查询。这些查询通常包含一些隐晦的指令或暗示,旨在绕过MLLM的安全过滤。此外,研究者还探索了不同的查询组合方式,以提高攻击的成功率。具体参数设置和网络结构取决于所使用的MLLM模型,论文中使用了多个主流的MLLM模型进行评估。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BadNAVer框架在Matterport3D模拟器中对五个MLLM驱动的导航智能体实现了超过90%的平均攻击成功率。在真实机器人实验中,该框架也成功诱导机器人执行了有害行为,验证了攻击的现实可行性。这些结果突显了MLLM导航器在面对恶意指令时的脆弱性,并强调了安全防御的重要性。
🎯 应用场景
该研究成果可应用于评估和提升视觉-语言导航系统中MLLM的安全性。通过模拟和真实环境中的越狱攻击测试,可以发现MLLM的潜在漏洞,并为开发更鲁棒的防御机制提供指导。此外,该研究也提醒人们关注具身智能体在现实世界中的安全风险,促进安全AI的发展。
📄 摘要(原文)
Multimodal large language models (MLLMs) have recently gained attention for their generalization and reasoning capabilities in Vision-and-Language Navigation (VLN) tasks, leading to the rise of MLLM-driven navigators. However, MLLMs are vulnerable to jailbreak attacks, where crafted prompts bypass safety mechanisms and trigger undesired outputs. In embodied scenarios, such vulnerabilities pose greater risks: unlike plain text models that generate toxic content, embodied agents may interpret malicious instructions as executable commands, potentially leading to real-world harm. In this paper, we present the first systematic jailbreak attack paradigm targeting MLLM-driven navigator. We propose a three-tiered attack framework and construct malicious queries across four intent categories, concatenated with standard navigation instructions. In the Matterport3D simulator, we evaluate navigation agents powered by five MLLMs and report an average attack success rate over 90%. To test real-world feasibility, we replicate the attack on a physical robot. Our results show that even well-crafted prompts can induce harmful actions and intents in MLLMs, posing risks beyond toxic output and potentially leading to physical harm.