MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
作者: Yulin Zhou, Yuankai Lin, Fanzhe Peng, Jiahui Chen, Kaiji Huang, Hua Yang, Zhouping Yin
分类: cs.RO
发布日期: 2025-05-18 (更新: 2025-10-15)
备注: Published in IEEE Robotics and Automation Letters (RA-L), 2025. 8 pages, 5 figures
期刊: IEEE Robotics and Automation Letters, vol. 10, no. 11, pp. 11761-11767, Nov. 2025
💡 一句话要点
提出MTIL,利用Mamba编码完整历史信息,解决时序模仿学习中的长程依赖问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 长时程依赖 Mamba 状态空间模型 机器人学习 世界模型 时间序列建模
📋 核心要点
- 传统模仿学习方法依赖马尔可夫假设,无法有效处理需要长时程历史信息才能解决感知模糊的任务。
- MTIL利用Mamba的线性时间循环动力学,学习隐式的、面向动作的世界模型,将完整轨迹历史编码为压缩状态。
- 实验表明,MTIL在模拟和真实机器人任务中,尤其是在解决长期时间模糊性方面,优于现有SOTA方法。
📝 摘要(中文)
标准的模仿学习(IL)方法在机器人领域取得了显著成功,但通常依赖于马尔可夫假设,这在长时程任务中会失效,因为历史信息对于解决感知模糊至关重要。这种局限性不仅源于概念上的差距,还源于计算上的根本障碍:像Transformer这样的主流架构通常受到二次复杂度的限制,使得处理长序列、高维观测变得不可行。为了克服这一双重挑战,我们引入了Mamba时序模仿学习(MTIL)。我们的方法代表了一种新的机器人学习范式,我们将其构建为世界模型和动力系统概念的实际综合。通过利用状态空间模型(SSM)的线性时间循环动力学,MTIL学习一个隐式的、面向动作的世界模型,该模型有效地将整个轨迹历史编码成一个压缩的、演化的状态。这使得策略能够以全面的时间上下文为条件,超越了马尔可夫方法的限制。通过在模拟基准(ACT, Robomimic, LIBERO)和具有挑战性的真实世界任务上的大量实验,MTIL展示了优于ACT和Diffusion Policy等SOTA方法的性能,特别是在解决长期时间模糊性方面。我们的发现不仅证实了完整时间上下文的必要性,而且验证了MTIL作为一种强大且计算上可行的方法,用于从高维观测中学习长时程、非马尔可夫行为。
🔬 方法详解
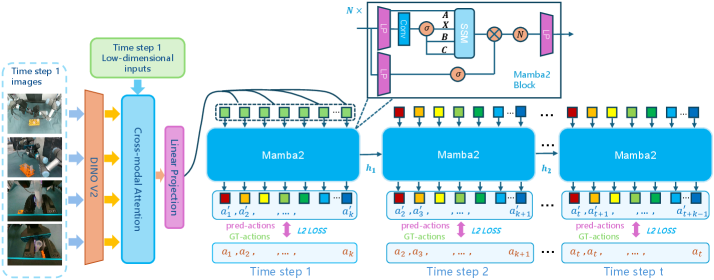
问题定义:论文旨在解决模仿学习中,传统方法因马尔可夫假设而无法有效利用长时程历史信息的问题。现有方法,如基于Transformer的模型,在处理长序列时面临计算复杂度过高的问题,限制了其在长时程机器人任务中的应用。
核心思路:论文的核心思路是利用Mamba架构,通过其线性时间复杂度的循环动力学,学习一个隐式的、面向动作的世界模型。该模型能够将整个轨迹历史压缩成一个演化的状态,从而使策略能够基于全面的时间上下文进行决策,克服了马尔可夫假设的限制。
技术框架:MTIL的整体框架包含以下几个主要部分:首先,使用Mamba作为核心模块,对历史观测序列进行编码,生成一个压缩的状态表示。然后,基于该状态表示,策略网络预测动作。整个训练过程通过模仿学习的方式进行,即最小化预测动作与专家动作之间的差异。
关键创新:最重要的技术创新点在于使用Mamba架构来编码完整的历史信息。与传统的RNN或Transformer相比,Mamba具有线性时间复杂度,能够高效地处理长序列。此外,MTIL将世界模型和动力系统概念相结合,学习一个隐式的、面向动作的模型,使得策略能够更好地理解环境的动态特性。
关键设计:论文中可能涉及的关键设计包括:Mamba模型的具体配置(层数、隐藏单元数等),损失函数的设计(例如,动作预测的均方误差损失),以及训练过程中的优化策略(例如,学习率调度)。具体参数设置和网络结构细节需要在论文原文中查找。
🖼️ 关键图片


📊 实验亮点
MTIL在模拟环境(ACT, Robomimic, LIBERO)和真实机器人任务中均表现出优越性能。尤其是在解决长期时间模糊性问题上,MTIL显著优于ACT和Diffusion Policy等现有SOTA方法。具体的性能提升幅度需要在论文原文中查找,但整体结果表明MTIL能够更有效地利用历史信息,从而提高模仿学习的性能。
🎯 应用场景
该研究成果可应用于各种需要长时程依赖的机器人任务,例如复杂操作、导航和人机协作。通过有效利用历史信息,机器人可以更好地理解环境,做出更明智的决策,从而提高任务完成的成功率和效率。未来,该方法有望推动机器人技术在工业自动化、医疗保健和智能家居等领域的广泛应用。
📄 摘要(原文)
Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, which falters in long-horizon tasks where history is crucial for resolving perceptual ambiguity. This limitation stems not only from a conceptual gap but also from a fundamental computational barrier: prevailing architectures like Transformers are often constrained by quadratic complexity, rendering the processing of long, high-dimensional observation sequences infeasible. To overcome this dual challenge, we introduce Mamba Temporal Imitation Learning (MTIL). Our approach represents a new paradigm for robotic learning, which we frame as a practical synthesis of World Model and Dynamical System concepts. By leveraging the linear-time recurrent dynamics of State Space Models (SSMs), MTIL learns an implicit, action-oriented world model that efficiently encodes the entire trajectory history into a compressed, evolving state. This allows the policy to be conditioned on a comprehensive temporal context, transcending the confines of Markovian approaches. Through extensive experiments on simulated benchmarks (ACT, Robomimic, LIBERO) and on challenging real-world tasks, MTIL demonstrates superior performance against SOTA methods like ACT and Diffusion Policy, particularly in resolving long-term temporal ambiguities. Our findings not only affirm the necessity of full temporal context but also validate MTIL as a powerful and a computationally feasible approach for learning long-horizon, non-Markovian behaviors from high-dimensional observations.