Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
作者: Zhengyi Luo, Chen Tessler, Toru Lin, Ye Yuan, Tairan He, Wenli Xiao, Yunrong Guo, Gal Chechik, Kris Kitani, Linxi Fan, Yuke Zhu
分类: cs.RO, cs.CV
发布日期: 2025-05-18
备注: Project page: https://zhengyiluo.github.io/PDC
💡 一句话要点
提出基于视觉强化学习的感知灵巧控制框架,使模拟人形机器人涌现主动感知和操作能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉强化学习 人形机器人 灵巧控制 主动感知 具身智能
📋 核心要点
- 现有机器人控制方法依赖于精确的状态信息,限制了其在复杂、非结构化环境中的应用。
- PDC框架通过以自我为中心的视觉输入驱动机器人控制,实现感知与动作的紧密结合,无需依赖特权信息。
- 实验表明,PDC能够使模拟人形机器人学习执行多种家庭任务,并涌现出主动搜索等类人行为。
📝 摘要(中文)
本文提出了一种名为感知灵巧控制(PDC)的框架,用于模拟人形机器人的视觉驱动灵巧全身控制。PDC仅依赖于以自我为中心的视觉信息进行任务规范,通过视觉线索实现物体搜索、目标放置和技能选择,无需特权状态信息(例如,3D物体位置和几何形状)。这种“感知即接口”的范例使得学习单个策略来执行多个家庭任务成为可能,包括抓取、放置和铰接物体操作。研究表明,从零开始使用强化学习进行训练可以产生诸如主动搜索等涌现行为。这些结果表明,视觉驱动的控制和复杂任务如何诱导类人行为,并可以作为动画、机器人和具身人工智能中闭环感知-行动的关键要素。
🔬 方法详解
问题定义:现有机器人控制方法通常依赖于精确的物体位置、几何形状等特权状态信息,这在实际应用中难以获取。此外,如何使机器人能够像人类一样,通过视觉感知主动探索环境并完成复杂任务,是一个重要的挑战。现有方法难以在复杂环境中实现视觉驱动的灵巧操作和主动感知。
核心思路:本文的核心思路是将视觉感知作为机器人控制的接口,通过强化学习训练机器人直接从以自我为中心的视觉输入中学习控制策略。这种方法模仿了人类通过视觉感知与环境交互的方式,使机器人能够自主地探索环境、发现目标并执行任务。通过端到端的学习,避免了手动设计复杂的感知和控制模块。
技术框架:PDC框架主要包含一个模拟人形机器人环境和一个强化学习算法。机器人配备了以自我为中心的摄像头,接收视觉输入。强化学习算法使用视觉输入作为状态,机器人的关节力矩作为动作,通过奖励函数引导机器人学习完成各种任务。整体流程是:机器人通过摄像头观察环境,根据当前视觉信息选择动作,执行动作后获得奖励,并更新策略。
关键创新:最重要的技术创新点在于将视觉感知作为机器人控制的直接接口,实现了视觉驱动的端到端学习。与传统方法相比,PDC无需手动设计复杂的感知模块,而是通过强化学习自动地从视觉输入中提取有用的信息,并学习相应的控制策略。这种方法使得机器人能够更好地适应复杂、非结构化的环境。
关键设计:PDC使用深度强化学习算法,例如PPO或SAC,来训练控制策略。奖励函数的设计至关重要,需要根据不同的任务进行调整,例如,对于物体搜索任务,奖励机器人探索未知的区域;对于抓取任务,奖励机器人成功抓取物体。网络结构通常采用卷积神经网络来处理视觉输入,并使用循环神经网络来处理时间序列数据。关键参数包括学习率、折扣因子、探索噪声等。
🖼️ 关键图片

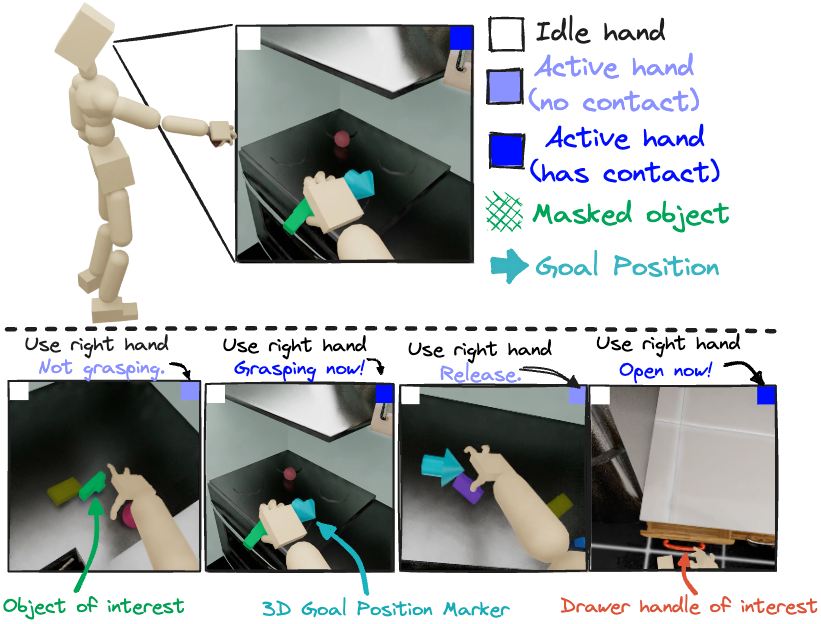
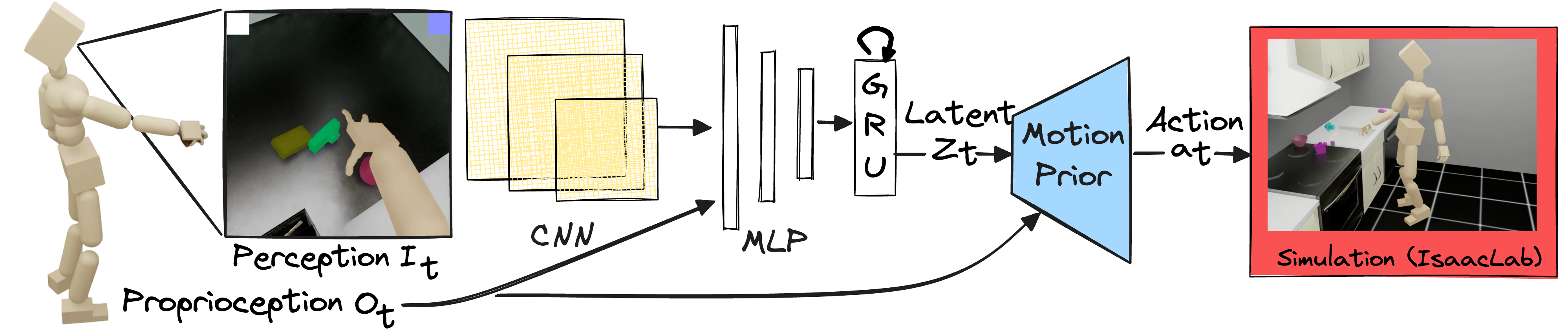
📊 实验亮点
实验结果表明,PDC框架能够使模拟人形机器人学习执行多种家庭任务,包括抓取、放置和铰接物体操作。通过从零开始的强化学习训练,机器人能够涌现出主动搜索等类人行为。例如,在物体搜索任务中,机器人能够自主地探索环境,发现目标物体,并将其抓取。这些结果表明,PDC框架具有很强的泛化能力和学习能力。
🎯 应用场景
该研究成果可应用于家庭服务机器人、工业自动化、医疗辅助机器人等领域。通过视觉驱动的控制,机器人能够更好地适应复杂、动态的环境,完成各种任务,例如物品整理、清洁、辅助手术等。未来,该技术有望实现更智能、更灵活的机器人,提高生产效率和服务质量。
📄 摘要(原文)
Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.