Federated Deep Reinforcement Learning for Privacy-Preserving Robotic-Assisted Surgery
作者: Sana Hafeez, Sundas Rafat Mulkana, Muhammad Ali Imran, Michele Sevegnani
分类: cs.RO
发布日期: 2025-05-17 (更新: 2025-10-28)
备注: 11 pages, 7 figures, conference
期刊: IEEE ICDCS 2025 45th IEEE International Conference on Distributed Computing Systems. Workshop on Federated and Privacy Preserving AI in Biomedical Applications (FPPAI), Glasgow, United Kingdom
💡 一句话要点
提出联邦深度强化学习框架,解决机器人辅助手术中数据隐私和个性化策略问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 联邦学习 深度强化学习 机器人辅助手术 隐私保护 动态策略自适应
📋 核心要点
- 现有RAS中RL应用受限于数据隐私、数据量不足和手术差异性大等问题。
- 提出FDRL框架,通过联邦学习在保护隐私的前提下进行分布式模型训练。
- 实验表明,该框架在隐私保护方面优于传统方法,并保持了手术精度。
📝 摘要(中文)
本文提出了一种联邦深度强化学习(FDRL)框架,旨在解决机器人辅助手术(RAS)中强化学习模型训练面临的挑战,包括严格的患者数据隐私法规、有限的手术数据集访问以及高度的手术程序可变性。该框架支持在多个医疗机构间进行去中心化的RL模型训练,无需暴露敏感的患者信息。其核心创新在于动态策略自适应机制,使手术机器人能够实时选择和调整患者特定的策略,从而确保个性化和优化的干预。为了维护严格的隐私标准,FDRL框架集成了安全聚合、差分隐私和同态加密技术。实验结果表明,与传统方法相比,隐私泄露减少了60%,而手术精度保持在集中式基线的1.5%范围内。这项工作为自适应、安全和以患者为中心的AI驱动的手术机器人技术奠定了基础,为在各种医疗环境中进行临床转化和可扩展部署提供了途径。
🔬 方法详解
问题定义:机器人辅助手术(RAS)中应用强化学习(RL)面临的主要问题是患者数据的隐私保护。传统的集中式训练方法需要将所有数据集中到一个地方,这违反了严格的隐私法规。此外,不同医疗机构的数据集存在差异,直接使用可能导致模型泛化能力不足。现有方法难以在保证模型性能的同时,有效保护患者隐私。
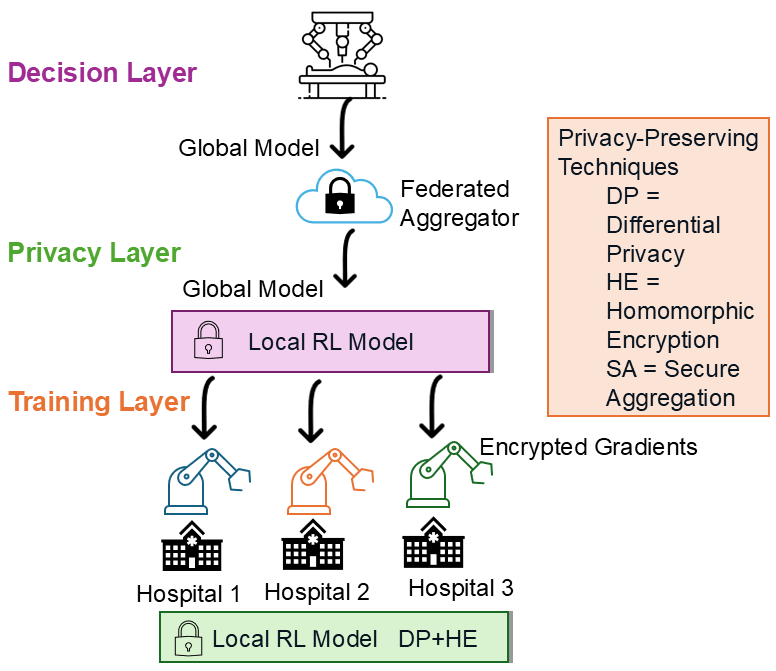
核心思路:本文的核心思路是利用联邦学习(Federated Learning)进行分布式模型训练,从而避免直接共享患者数据。每个医疗机构在本地数据上训练模型,然后将模型参数的更新上传到中央服务器进行聚合,最终得到一个全局模型。此外,引入动态策略自适应机制,使机器人能够根据患者的特定情况选择和调整策略,实现个性化手术。
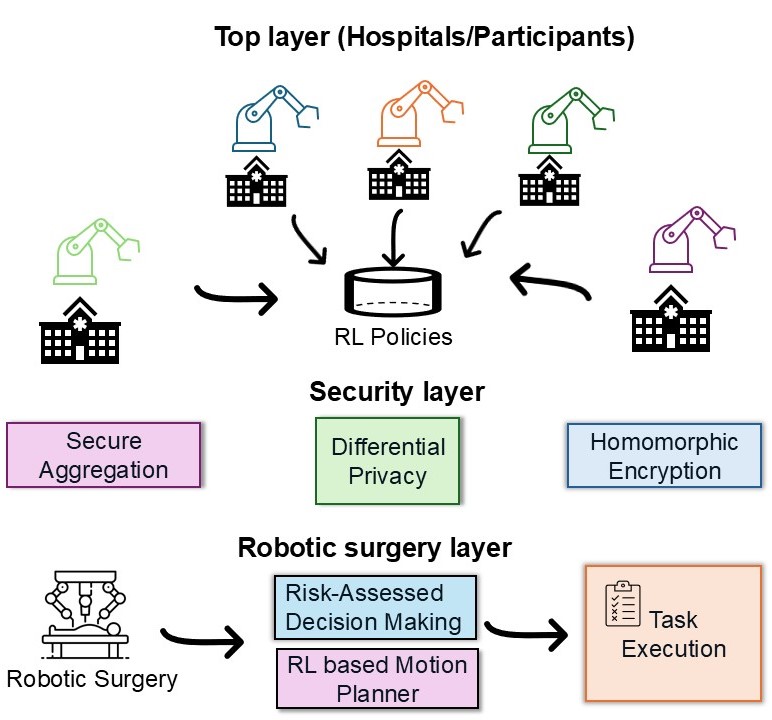
技术框架:FDRL框架包含以下几个主要模块:1) 本地训练:每个医疗机构使用本地手术数据训练RL模型。2) 安全聚合:中央服务器接收来自各个机构的模型更新,并使用安全聚合算法(如FedAvg)进行聚合,生成新的全局模型。3) 动态策略自适应:手术机器人根据患者的特征,从全局模型中选择或调整合适的策略。4) 隐私保护:在模型训练和聚合过程中,采用差分隐私和同态加密等技术,防止敏感信息泄露。
关键创新:该框架的关键创新在于将联邦学习与动态策略自适应相结合,实现了隐私保护下的个性化手术。传统的联邦学习方法通常只关注模型训练的隐私保护,而忽略了模型在实际应用中的个性化需求。本文提出的动态策略自适应机制,能够根据患者的特定情况调整策略,从而提高手术的精度和效率。
关键设计:为了保护隐私,采用了差分隐私技术,在模型更新中添加噪声,防止攻击者通过分析模型参数推断出患者的敏感信息。同时,使用同态加密技术对模型更新进行加密,确保在聚合过程中无法获取原始数据。动态策略自适应模块使用一个策略选择器,根据患者的特征选择合适的策略。策略选择器可以是一个简单的分类器,也可以是一个更复杂的神经网络。
🖼️ 关键图片
📊 实验亮点
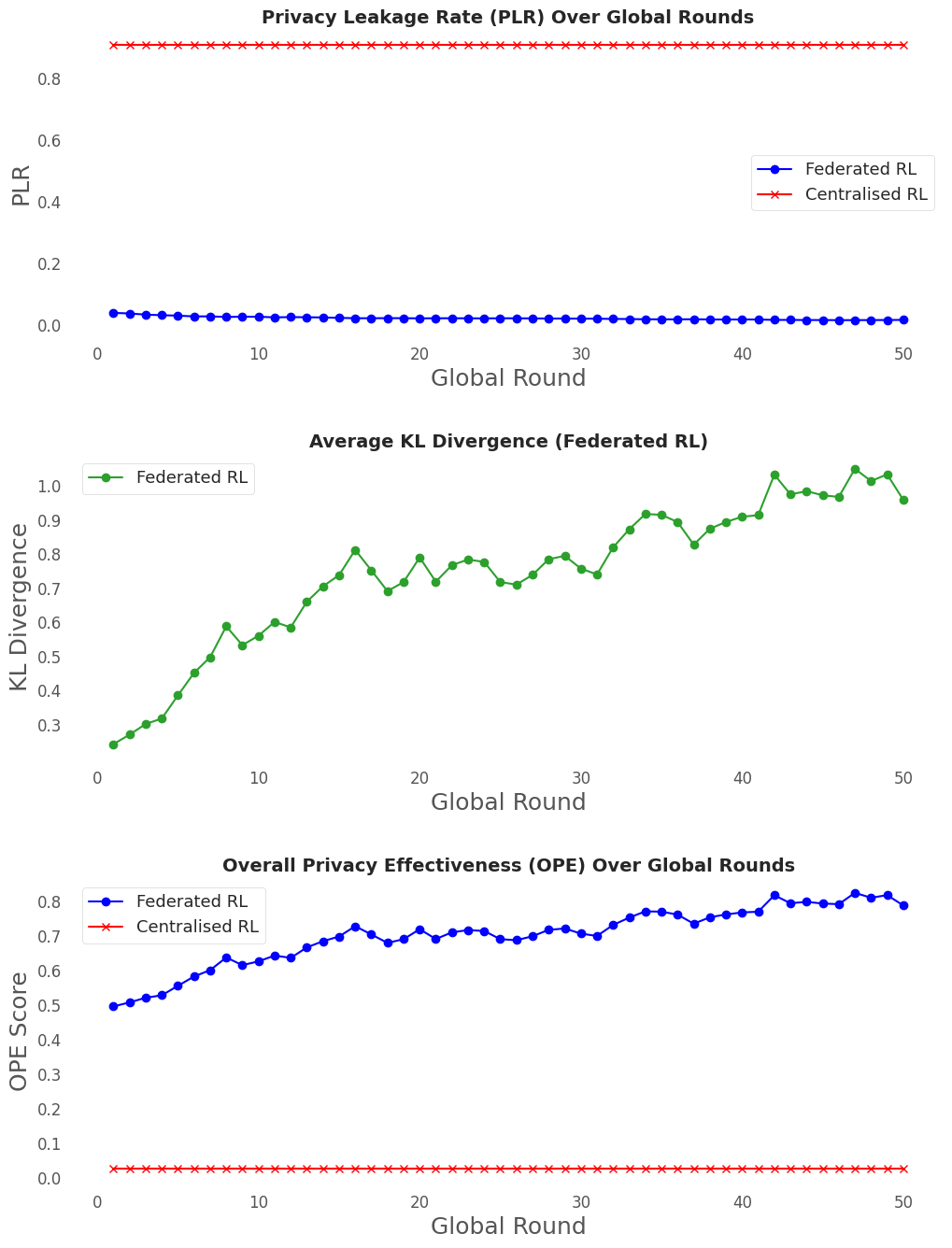
实验结果表明,与传统的集中式训练方法相比,该FDRL框架在隐私保护方面有显著提升,隐私泄露减少了60%。同时,手术精度保持在集中式基线的1.5%范围内,表明在保护隐私的同时,模型性能没有明显下降。这些结果验证了该框架在实际应用中的可行性和有效性。
🎯 应用场景
该研究成果可应用于各种需要保护患者隐私的医疗场景,例如远程手术、个性化治疗方案制定等。通过联邦学习,可以利用分布在不同医疗机构的数据,训练出更强大、更通用的AI模型,从而提高医疗服务的质量和效率。未来,该技术有望推广到其他领域,如金融、教育等,实现安全可靠的分布式智能。
📄 摘要(原文)
The integration of Reinforcement Learning (RL) into robotic-assisted surgery (RAS) holds significant promise for advancing surgical precision, adaptability, and autonomous decision-making. However, the development of robust RL models in clinical settings is hindered by key challenges, including stringent patient data privacy regulations, limited access to diverse surgical datasets, and high procedural variability. To address these limitations, this paper presents a Federated Deep Reinforcement Learning (FDRL) framework that enables decentralized training of RL models across multiple healthcare institutions without exposing sensitive patient information. A central innovation of the proposed framework is its dynamic policy adaptation mechanism, which allows surgical robots to select and tailor patient-specific policies in real-time, thereby ensuring personalized and Optimised interventions. To uphold rigorous privacy standards while facilitating collaborative learning, the FDRL framework incorporates secure aggregation, differential privacy, and homomorphic encryption techniques. Experimental results demonstrate a 60\% reduction in privacy leakage compared to conventional methods, with surgical precision maintained within a 1.5\% margin of a centralized baseline. This work establishes a foundational approach for adaptive, secure, and patient-centric AI-driven surgical robotics, offering a pathway toward clinical translation and scalable deployment across diverse healthcare environments.