H2R: A Human-to-Robot Data Augmentation for Robot Pre-training from Videos
作者: Guangrun Li, Yaoxu Lyu, Zhuoyang Liu, Chengkai Hou, Jieyu Zhang, Shanghang Zhang
分类: cs.RO
发布日期: 2025-05-17 (更新: 2026-01-04)
💡 一句话要点
提出H2R数据增强方法,弥合人与机器人视觉差异,提升机器人预训练效果
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人学习 数据增强 视频预训练 人机视觉差异 机器人操作
📋 核心要点
- 现有视频预训练方法在机器人学习中表现次优,主要原因是人类手部与机器人手部存在显著的视觉差异。
- H2R通过检测人类手部关键点,合成机器人运动,并将渲染后的机器人图像合成到第一人称视角视频中,弥合视觉差异。
- 实验表明,H2R在模拟和真实世界任务中均能显著提高机器人策略的成功率,提升幅度达到5.0%-23.3%。
📝 摘要(中文)
本文提出了一种名为H2R的数据增强技术,旨在解决视频预训练中由于人类手部与机器人手部之间显著视觉差异而导致的机器人学习次优问题。H2R通过检测人类手部关键点,在模拟环境中合成机器人运动,并将渲染后的机器人图像合成到第一人称视角视频中,从而显式地弥合了预训练期间人类和机器人之间的视觉差异。我们利用H2R增强了Ego4D和SSv2等大规模第一人称人类视频数据集,用模拟的机器人手臂替换了人类手部,生成了以机器人为中心的训练数据。基于此,我们构建并发布了一系列百万级规模的数据集,涵盖了多种机器人形态(带有夹爪/Leaphand的UR5,Franka)和数据来源(SSv2,Ego4D)。为了验证增强管道的有效性,我们引入了一种基于CLIP的图像-文本相似性度量,以定量评估机器人渲染帧与原始人类动作的语义保真度。我们在Robomimic、RLBench和PushT三个模拟基准以及使用配备夹爪和Leaphand末端执行器的UR5机器人的真实世界操作任务中验证了H2R。H2R持续提高了下游任务的成功率,在模拟中获得了5.0%-10.2%的提升,在真实世界任务中获得了6.7%-23.3%的提升,适用于各种视觉编码器和策略学习方法。这些结果表明,H2R通过减轻人类和机器人领域之间的视觉差异,提高了机器人策略的泛化能力。
🔬 方法详解
问题定义:论文旨在解决机器人学习中,由于人类视频数据与机器人视觉数据存在差异,导致直接使用人类视频进行预训练效果不佳的问题。现有方法无法有效弥合人类手部动作与机器人操作之间的视觉鸿沟,限制了预训练模型的泛化能力。
核心思路:论文的核心思路是通过数据增强,将人类视频数据转换为机器人视角的数据。具体来说,就是将人类手部的动作替换为模拟的机器人手臂的动作,从而使预训练数据更接近机器人实际操作的视觉输入。这种方法显式地解决了人类和机器人之间的视觉差异问题。
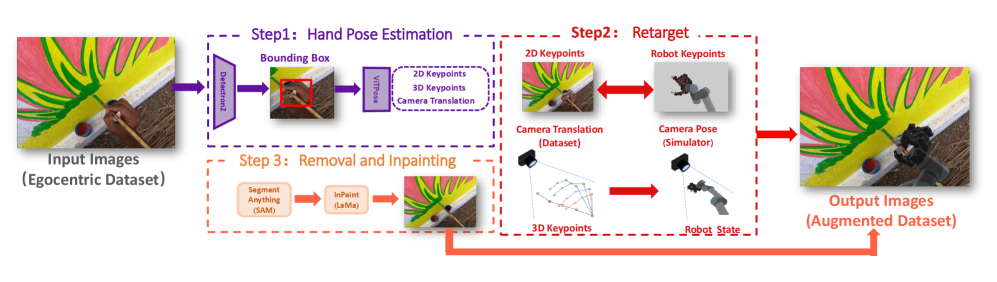
技术框架:H2R的整体框架包括以下几个主要步骤:1) 人类视频数据输入;2) 人类手部关键点检测;3) 基于关键点信息,在模拟环境中生成对应的机器人运动轨迹;4) 渲染机器人手臂的图像;5) 将渲染的机器人手臂图像合成到原始人类视频中,替换掉人类手部;6) 生成机器人视角的训练数据。
关键创新:H2R的关键创新在于其数据增强方式,它不是简单地对图像进行变换,而是根据人类的动作,在模拟环境中生成对应的机器人动作,并将渲染结果合成到原始视频中。这种方法能够更真实地模拟机器人操作的视觉效果,从而更好地弥合人类和机器人之间的视觉差异。此外,论文还提出了基于CLIP的图像-文本相似性度量,用于评估增强数据的语义保真度。
关键设计:在手部关键点检测方面,可以使用现有的姿态估计模型。在机器人运动生成方面,需要根据不同的机器人类型和末端执行器进行设计。在图像合成方面,需要考虑光照、阴影等因素,以保证合成图像的真实感。论文构建了包含多种机器人形态(UR5, Franka)和数据来源(SSv2, Ego4D)的百万级数据集。
🖼️ 关键图片


📊 实验亮点
实验结果表明,H2R在Robomimic、RLBench和PushT等模拟环境中,以及真实世界的UR5机器人操作任务中,均取得了显著的性能提升。具体而言,在模拟环境中,H2R使成功率提高了5.0%-10.2%,而在真实世界任务中,成功率提高了6.7%-23.3%。这些结果验证了H2R能够有效弥合人类和机器人之间的视觉差异,提高机器人策略的泛化能力。
🎯 应用场景
H2R技术可广泛应用于机器人操作技能学习、自动化任务执行等领域。通过利用大量现有的第一人称人类活动视频,可以低成本地生成机器人训练数据,提升机器人在复杂环境中的适应性和泛化能力。该技术有助于加速机器人智能化进程,推动机器人在工业、医疗、服务等行业的应用。
📄 摘要(原文)
Large-scale pre-training using videos has proven effective for robot learning. However, the models pre-trained on such data can be suboptimal for robot learning due to the significant visual gap between human hands and those of different robots. To remedy this, we propose H2R, a simple data augmentation technique that detects human hand keypoints, synthesizes robot motions in simulation, and composites rendered robots into egocentric videos. This process explicitly bridges the visual gap between human and robot embodiments during pre-training. We apply H2R to augment large-scale egocentric human video datasets such as Ego4D and SSv2, replacing human hands with simulated robotic arms to generate robot-centric training data. Based on this, we construct and release a family of 1M-scale datasets covering multiple robot embodiments (UR5 with gripper/Leaphand, Franka) and data sources (SSv2, Ego4D). To verify the effectiveness of the augmentation pipeline, we introduce a CLIP-based image-text similarity metric that quantitatively evaluates the semantic fidelity of robot-rendered frames to the original human actions. We validate H2R across three simulation benchmarks: Robomimic, RLBench and PushT and real-world manipulation tasks with a UR5 robot equipped with Gripper and Leaphand end-effectors. H2R consistently improves downstream success rates, yielding gains of 5.0%-10.2% in simulation and 6.7%-23.3% in real-world tasks across various visual encoders and policy learning methods. These results indicate that H2R improves the generalization ability of robotic policies by mitigating the visual discrepancies between human and robot domains.