Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
作者: Shuo Wang, Yongcai Wang, Wanting Li, Xudong Cai, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Deying Li, Zhaoxin Fan
分类: cs.RO
发布日期: 2025-05-17 (更新: 2025-10-14)
期刊: NeurIPS 2025
💡 一句话要点
提出Aux-Think框架,解决视觉-语言导航中推理策略的数据效率问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 具身智能 链式思考 推理策略 数据效率
📋 核心要点
- 现有VLN方法在整合推理策略方面存在不足,尤其是在长程任务中,推理过程容易导致性能下降。
- Aux-Think框架通过在训练阶段引入CoT监督,使模型学习结构化推理模式,但在推理阶段避免使用推理,从而提高效率。
- 通过R2R-CoT-320k数据集的实验,Aux-Think在数据效率方面表现出色,并在相同数据规模下取得了最佳性能。
📝 摘要(中文)
视觉-语言导航(VLN)是开发具身智能体的一项关键任务,它要求智能体能够根据自然语言指令在复杂的真实环境中导航。大型预训练模型在VLN方面的最新进展显著提高了泛化能力和指令理解能力,但导航中推理策略的作用仍未得到充分探索。为了填补这一空白,我们对VLN的推理策略进行了首次系统评估,包括No-Think(直接动作预测)、Pre-Think(行动前推理)和Post-Think(行动后推理)。令人惊讶的是,我们的研究结果揭示了推理时推理崩溃问题,即推理时推理会降低导航准确性。基于此,我们提出了Aux-Think框架,该框架训练模型通过CoT监督来内化结构化推理模式,同时在在线预测中直接推断动作,无需推理。为了支持该框架,我们发布了R2R-CoT-320k,这是第一个用于VLN的Chain-of-Thought标注数据集。大量实验表明,Aux-Think大大减少了训练工作量,并在相同数据规模下实现了最佳性能。
🔬 方法详解
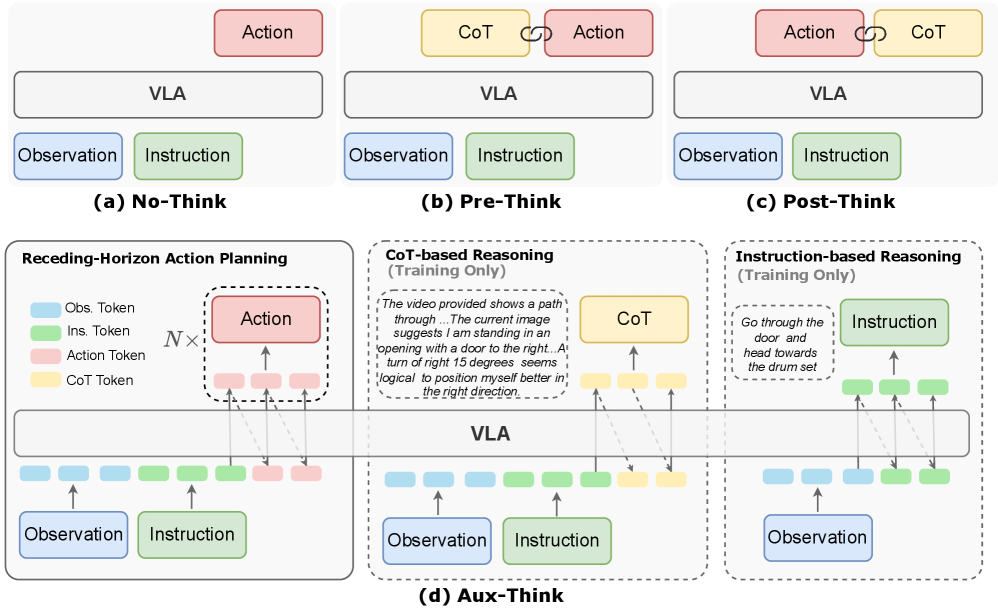
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据自然语言指令在真实环境中导航。现有方法,特别是基于大型预训练模型的方法,虽然在泛化性和指令理解方面有所提升,但在如何有效利用推理策略方面仍存在挑战。一个关键问题是“推理时推理崩溃”,即在导航过程中进行推理反而会降低导航的准确性,这表明直接将推理过程应用于VLN任务可能并不有效。
核心思路:Aux-Think的核心思路是将推理过程内化到模型中,而不是在推理时显式地进行推理。具体来说,通过在训练阶段使用Chain-of-Thought (CoT) 监督,模型学习到结构化的推理模式。在实际导航(推理)阶段,模型直接预测动作,避免了推理过程带来的性能下降。这种设计旨在利用推理的优势,同时避免其在在线导航中的负面影响。
技术框架:Aux-Think框架主要包含两个阶段:训练阶段和推理阶段。在训练阶段,模型接收视觉输入、语言指令以及CoT推理过程的监督信号。CoT监督通过R2R-CoT-320k数据集提供,该数据集包含了VLN任务的推理链。模型学习将视觉和语言信息与推理链对齐,从而内化推理模式。在推理阶段,模型仅接收视觉输入和语言指令,直接预测动作,无需进行显式的推理。
关键创新:Aux-Think的关键创新在于将推理过程从在线推理转移到离线训练,从而避免了推理时推理崩溃的问题。通过CoT监督,模型学习到结构化的推理模式,并在推理阶段直接应用这些模式,提高了数据效率和导航准确性。此外,R2R-CoT-320k数据集的发布为VLN任务的推理研究提供了宝贵资源。
关键设计:Aux-Think框架的关键设计包括:1) 使用CoT监督进行训练,鼓励模型学习结构化推理模式;2) 在推理阶段避免使用推理,直接预测动作;3) R2R-CoT-320k数据集的设计,该数据集包含了VLN任务的推理链,为CoT监督提供了数据支持。具体的网络结构和损失函数可能依赖于所使用的基础模型,但核心思想是保持一致的:通过CoT监督学习推理模式,并在推理时直接应用。
🖼️ 关键图片


📊 实验亮点
Aux-Think框架在R2R数据集上进行了实验,结果表明,在相同数据规模下,Aux-Think的性能优于其他基线方法。该框架有效地解决了推理时推理崩溃的问题,并显著提高了数据效率。R2R-CoT-320k数据集的发布也为VLN领域的推理研究提供了重要资源。
🎯 应用场景
Aux-Think框架在机器人导航、自动驾驶、虚拟助手等领域具有广泛的应用前景。通过提高视觉-语言导航的数据效率和准确性,可以使智能体更好地理解人类指令,并在复杂环境中自主导航。该研究有助于开发更智能、更可靠的具身智能体,从而改善人机交互体验。
📄 摘要(原文)
Vision-Language Navigation (VLN) is a critical task for developing embodied agents that can follow natural language instructions to navigate in complex real-world environments. Recent advances in VLN by large pretrained models have significantly improved generalization and instruction grounding compared to traditional approaches. However, the role of reasoning strategies in navigation-an action-centric, long-horizon task-remains underexplored, despite Chain-of-Thought (CoT) reasoning's demonstrated success in static tasks like visual question answering. To address this gap, we conduct the first systematic evaluation of reasoning strategies for VLN, including No-Think (direct action prediction), Pre-Think (reason before action), and Post-Think (reason after action). Surprisingly, our findings reveal the Inference-time Reasoning Collapse issue, where inference-time reasoning degrades navigation accuracy, highlighting the challenges of integrating reasoning into VLN. Based on this insight, we propose Aux-Think, a framework that trains models to internalize structured reasoning patterns through CoT supervision, while inferring action directly without reasoning in online prediction. To support this framework, we release R2R-CoT-320k, the first Chain-of-Thought annotated dataset for VLN. Extensive experiments show that Aux-Think reduces training effort greatly and achieves the best performance under the same data scale.