GLOVER++: Unleashing the Potential of Affordance Learning from Human Behaviors for Robotic Manipulation
作者: Teli Ma, Jia Zheng, Zifan Wang, Ziyao Gao, Jiaming Zhou, Junwei Liang
分类: cs.RO, cs.CV
发布日期: 2025-05-17
💡 一句话要点
GLOVER++:利用人类行为中的可供性学习提升机器人操作能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 可供性学习 人类行为 数据集 多模态学习
📋 核心要点
- 现有方法缺乏大规模可供性标注数据集,难以充分探索多样化操作环境中的可供性。
- GLOVER++提出全局到局部的可供性训练框架,从人类演示中迁移可操作知识到机器人操作任务。
- GLOVER++在HOVA-500K基准上取得SOTA结果,并在多种机器人操作任务中展现出强大的泛化能力。
📝 摘要(中文)
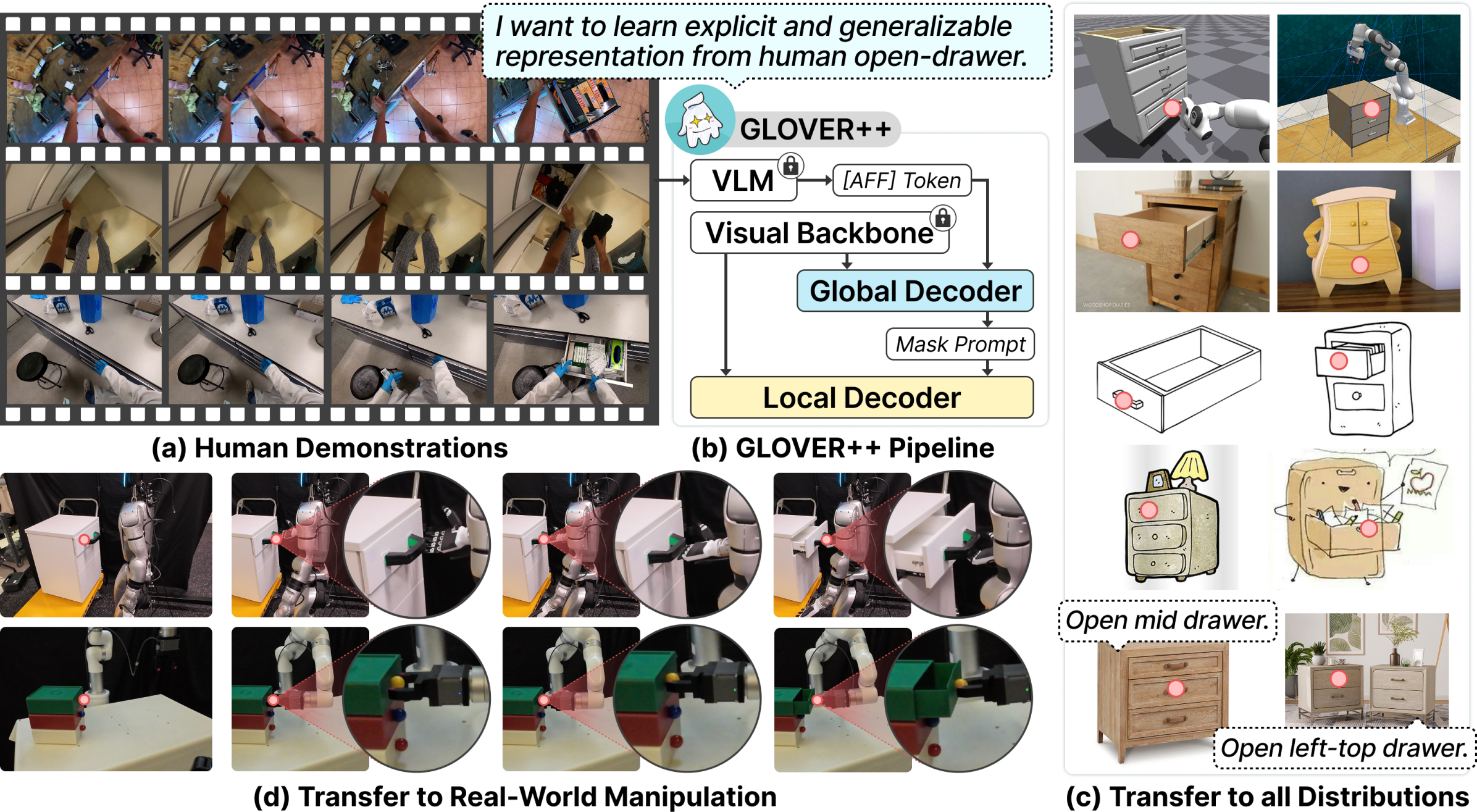
本文提出了一种从人类演示视频中学习操作技能的方法,通过可供性(affordance)学习来实现通用且可解释的机器人智能。为了解决缺乏大规模、精确可供性标注数据集以及可供性在多样化操作环境中探索不足的问题,我们构建了HOVA-500K数据集,它包含1726个物体类别和675个动作的50万张图像,并提供了多模态可供性推理的标准基准测试套件。基于HOVA-500K,我们提出了GLOVER++,一个全局到局部的可供性训练框架,能够有效地将人类演示中的可操作可供性知识迁移到下游的开放词汇推理任务中。GLOVER++在HOVA-500K基准测试中取得了最先进的结果,并在各种下游机器人操作任务中表现出强大的泛化能力。通过显式地建模可操作的可供性,GLOVER++促进了跨场景、模态和任务的鲁棒迁移。我们希望HOVA-500K和GLOVER++框架能够成为弥合人类演示和机器人操作能力之间差距的宝贵资源。
🔬 方法详解
问题定义:现有机器人操作学习方法面临两个主要挑战:一是缺乏大规模、精确标注可供性信息的数据集;二是难以在各种操作环境中充分探索和利用可供性信息。这限制了机器人从人类演示中学习通用操作技能的能力。
核心思路:GLOVER++的核心思路是通过显式地建模和学习可供性,将人类演示中的操作知识迁移到机器人操作任务中。通过构建大规模数据集HOVA-500K,并设计全局到局部的训练框架,使模型能够学习到物体和动作之间的可供性关系,从而实现更好的泛化能力。
技术框架:GLOVER++框架包含以下主要模块:1) 大规模可供性标注数据集HOVA-500K的构建;2) 全局可供性学习模块,用于学习物体和动作之间的全局关系;3) 局部可供性学习模块,用于学习物体局部区域和动作之间的细粒度关系;4) 多模态融合模块,用于融合视觉和语言信息,实现开放词汇推理。整个流程是从全局到局部,逐步提升模型对可供性的理解和利用能力。
关键创新:GLOVER++的关键创新在于其全局到局部的可供性学习框架,以及大规模可供性标注数据集HOVA-500K的构建。与现有方法相比,GLOVER++能够更有效地学习和利用可供性信息,从而实现更好的泛化能力和鲁棒性。
关键设计:HOVA-500K数据集包含50万张图像,覆盖1726个物体类别和675个动作。全局可供性学习模块采用Transformer结构,学习物体和动作之间的全局关系。局部可供性学习模块采用卷积神经网络,学习物体局部区域和动作之间的细粒度关系。损失函数包括交叉熵损失和对比损失,用于优化模型的可供性学习能力。
🖼️ 关键图片


📊 实验亮点
GLOVER++在HOVA-500K基准测试中取得了state-of-the-art的结果,显著优于现有方法。在下游机器人操作任务中,GLOVER++也表现出强大的泛化能力,能够成功地完成各种复杂的任务。实验结果表明,通过显式地建模和学习可供性,可以有效地提升机器人的操作能力。
🎯 应用场景
GLOVER++在机器人操作领域具有广泛的应用前景,例如家庭服务机器人、工业自动化机器人、医疗机器人等。它可以帮助机器人更好地理解人类意图,从而执行更复杂的任务。此外,该研究还可以促进人机协作的发展,使机器人能够更好地与人类协同工作,提高工作效率和安全性。
📄 摘要(原文)
Learning manipulation skills from human demonstration videos offers a promising path toward generalizable and interpretable robotic intelligence-particularly through the lens of actionable affordances. However, transferring such knowledge remains challenging due to: 1) a lack of large-scale datasets with precise affordance annotations, and 2) insufficient exploration of affordances in diverse manipulation contexts. To address these gaps, we introduce HOVA-500K, a large-scale, affordance-annotated dataset comprising 500,000 images across 1,726 object categories and 675 actions. We also release a standardized benchmarking suite for multi-modal affordance reasoning. Built upon HOVA-500K, we present GLOVER++, a global-to-local affordance training framework that effectively transfers actionable affordance knowledge from human demonstrations to downstream open-vocabulary reasoning tasks. GLOVER++ achieves state-of-the-art results on the HOVA-500K benchmark and demonstrates strong generalization across diverse downstream robotic manipulation tasks. By explicitly modeling actionable affordances, GLOVER++ facilitates robust transfer across scenes, modalities, and tasks. We hope that HOVA-500K and the GLOVER++ framework will serve as valuable resources for bridging the gap between human demonstrations and robotic manipulation capabilities.