GRoQ-LoCO: Generalist and Robot-agnostic Quadruped Locomotion Control using Offline Datasets
作者: Narayanan PP, Sarvesh Prasanth Venkatesan, Srinivas Kantha Reddy, Shishir Kolathaya
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-16 (更新: 2025-05-24)
备注: 18pages, 16figures, 6tables
💡 一句话要点
GRoQ-LoCO:基于离线数据的通用且机器人无关的四足机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 四足机器人 运动控制 离线学习 通用策略 注意力机制
📋 核心要点
- 现有方法难以在连续动力学和实时适应不同地形和机器人形态的需求下,将大规模离线训练应用于四足机器人运动控制。
- GRoQ-LoCO利用离线数据集,通过注意力机制学习跨多种四足机器人和地形的通用运动策略,实现行为融合。
- 实验表明,该方法能够实现跨多种四足机器人的零样本迁移,并在Unitree Go1和Stoch 5等机器人上成功部署。
📝 摘要(中文)
本文提出GRoQ-LoCO,一个可扩展的、基于注意力机制的框架,仅使用离线数据集学习跨多种四足机器人和地形的通用运动策略。该方法利用来自两种不同运动行为(楼梯穿越和平面地形穿越)的专家演示,这些数据来自多个四足机器人,以训练能够进行行为融合的通用模型。重要的是,该框架仅使用来自所有机器人的本体感受数据,而不包含任何机器人特定的编码。该策略可以直接部署在Intel i7 nuc上,产生低延迟的控制输出,无需任何测试时优化。实验结果表明,该方法能够在高度不同的四足机器人和地形上实现零样本迁移,包括在商用12kg的Unitree Go1上的硬件部署。即使在不同机器人上运动技能分布不均的交叉机器人训练设置中,也能成功地将平面行走和楼梯穿越行为迁移到所有机器人。初步结果还显示,无需任何微调,即可在Stoch 5(一个70kg的四足机器人)上在平面和室外地形上行走。这些结果证明了离线、数据驱动学习在不同四足机器人形态和行为之间泛化的潜力。
🔬 方法详解
问题定义:现有的四足机器人运动控制方法通常需要针对特定机器人和环境进行调整,泛化能力差。此外,在线学习方法需要大量的试错,对机器人硬件有较高风险。离线学习虽然可以避免在线试错,但如何利用多源异构的离线数据,训练出能够适应多种机器人和地形的通用策略,仍然是一个挑战。
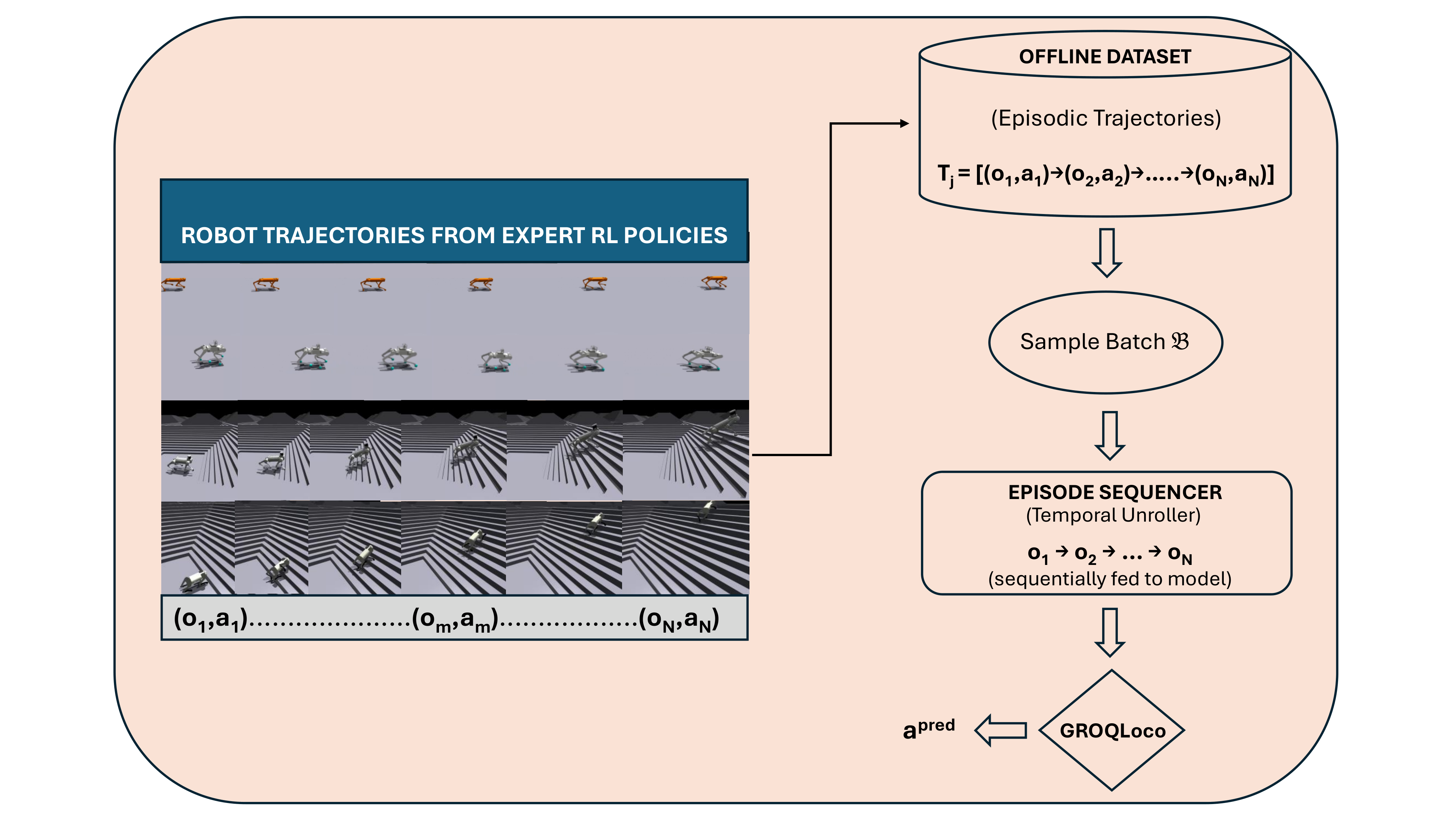
核心思路:GRoQ-LoCO的核心思路是利用大规模离线数据集,学习一个通用的运动控制策略,该策略能够适应不同的四足机器人和地形。通过将不同机器人和地形的数据混合在一起训练,并采用注意力机制来学习不同数据之间的关系,从而提高策略的泛化能力。同时,该方法只使用本体感受数据作为输入,避免了对机器人特定信息的依赖,进一步提高了策略的通用性。
技术框架:GRoQ-LoCO的整体框架包括数据收集、模型训练和策略部署三个阶段。首先,收集来自不同四足机器人和地形的运动数据,包括平面行走和楼梯穿越等。然后,使用这些数据训练一个基于注意力机制的神经网络模型,该模型以本体感受数据作为输入,输出机器人的关节控制指令。最后,将训练好的模型部署到机器人上,实现运动控制。
关键创新:GRoQ-LoCO的关键创新在于其通用性和可扩展性。该方法能够利用来自不同机器人和地形的离线数据,学习一个通用的运动控制策略,而无需针对特定机器人和环境进行调整。此外,该方法采用注意力机制,能够有效地学习不同数据之间的关系,从而提高策略的泛化能力。
关键设计:GRoQ-LoCO的关键设计包括以下几个方面:1) 使用Transformer架构作为策略网络的主体,利用其强大的序列建模能力和注意力机制来处理时间序列的本体感受数据。2) 采用混合数据集训练,将来自不同机器人和地形的数据混合在一起,并使用数据增强技术来增加数据的多样性。3) 使用行为克隆作为训练目标,直接从专家演示数据中学习控制策略。4) 策略网络直接输出关节力矩控制指令,避免了中间状态估计的误差累积。
🖼️ 关键图片


📊 实验亮点
GRoQ-LoCO在多个四足机器人和地形上进行了实验验证。结果表明,该方法能够在Unitree Go1和Stoch 5等机器人上实现零样本迁移,无需任何微调。即使在不同机器人上运动技能分布不均的情况下,也能成功地将平面行走和楼梯穿越行为迁移到所有机器人。这些结果表明,GRoQ-LoCO具有很强的泛化能力和实用价值。
🎯 应用场景
GRoQ-LoCO具有广泛的应用前景,例如搜救、物流、巡检等领域。该方法可以使四足机器人能够在复杂和未知的环境中自主运动,完成各种任务。此外,该方法还可以用于开发更智能、更灵活的机器人,提高机器人的适应性和可靠性。未来,该技术有望推动四足机器人在各行各业的广泛应用。
📄 摘要(原文)
Recent advancements in large-scale offline training have demonstrated the potential of generalist policy learning for complex robotic tasks. However, applying these principles to legged locomotion remains a challenge due to continuous dynamics and the need for real-time adaptation across diverse terrains and robot morphologies. In this work, we propose GRoQ-LoCO, a scalable, attention-based framework that learns a single generalist locomotion policy across multiple quadruped robots and terrains, relying solely on offline datasets. Our approach leverages expert demonstrations from two distinct locomotion behaviors - stair traversal (non-periodic gaits) and flat terrain traversal (periodic gaits) - collected across multiple quadruped robots, to train a generalist model that enables behavior fusion. Crucially, our framework operates solely on proprioceptive data from all robots without incorporating any robot-specific encodings. The policy is directly deployable on an Intel i7 nuc, producing low-latency control outputs without any test-time optimization. Our extensive experiments demonstrate zero-shot transfer across highly diverse quadruped robots and terrains, including hardware deployment on the Unitree Go1, a commercially available 12kg robot. Notably, we evaluate challenging cross-robot training setups where different locomotion skills are unevenly distributed across robots, yet observe successful transfer of both flat walking and stair traversal behaviors to all robots at test time. We also show preliminary walking on Stoch 5, a 70kg quadruped, on flat and outdoor terrains without requiring any fine tuning. These results demonstrate the potential of offline, data-driven learning to generalize locomotion across diverse quadruped morphologies and behaviors.