ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
作者: Jiahui Zhang, Yusen Luo, Abrar Anwar, Sumedh Anand Sontakke, Joseph J Lim, Jesse Thomason, Erdem Biyik, Jesse Zhang
分类: cs.RO
发布日期: 2025-05-16 (更新: 2025-09-19)
备注: CoRL 2025 Oral
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ReWiND:无需新示教,通过语言引导奖励学习机器人策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 语言引导 强化学习 奖励函数 离线学习
📋 核心要点
- 传统强化学习和模仿学习需要针对每个新任务设计奖励函数或提供专家示教,成本高昂且难以泛化。
- ReWiND通过学习语言条件化的奖励函数,并使用离线强化学习预训练策略,实现仅通过语言指令学习机器人操作任务。
- 实验表明,ReWiND在奖励泛化和策略对齐方面显著优于基线,并在模拟和真实世界环境中实现了高效的任务适应。
📝 摘要(中文)
我们提出了ReWiND,一个仅从语言指令学习机器人操作任务的框架,无需针对每个任务进行示教。标准的强化学习(RL)和模仿学习方法需要人为设计的奖励函数或针对每个新任务的专家示教。相比之下,ReWiND从一个小型的示教数据集开始学习:(1)一个数据高效的、语言条件化的奖励函数,用奖励标记数据集;(2)一个使用这些奖励通过离线RL预训练的语言条件化策略。对于未见过的任务变体,ReWiND使用学习到的奖励函数微调预训练的策略,只需要最少的在线交互。我们表明,ReWiND的奖励模型可以有效地泛化到未见过的任务,在奖励泛化和策略对齐指标上优于基线方法高达2.4倍。最后,我们证明了ReWiND能够高效地适应新任务,在模拟中优于基线方法2倍,并在真实世界的预训练双臂策略上提高了5倍,朝着可扩展的真实世界机器人学习迈出了一步。
🔬 方法详解
问题定义:现有机器人学习方法,如强化学习和模仿学习,通常需要针对每个新任务手动设计奖励函数或提供大量的专家示教数据。这使得机器人难以快速适应新的任务,并且限制了其在真实世界中的应用。痛点在于缺乏一种能够仅通过语言指令就能引导机器人学习新任务的方法,从而降低学习成本并提高泛化能力。
核心思路:ReWiND的核心思路是学习一个语言条件化的奖励函数,该函数能够根据语言指令评估机器人行为的优劣。通过离线强化学习,利用少量示教数据和学习到的奖励函数预训练一个语言条件化的策略。当面对新的任务时,只需使用学习到的奖励函数对预训练策略进行微调,从而实现快速适应。
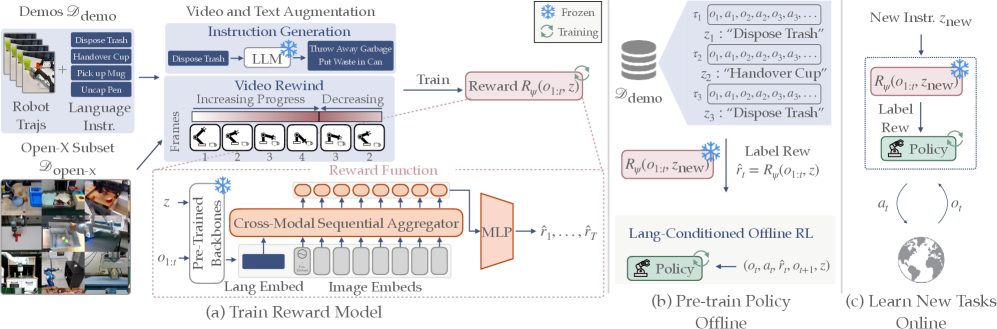
技术框架:ReWiND框架包含两个主要阶段:奖励函数学习和策略学习。首先,利用少量示教数据学习一个语言条件化的奖励函数,该函数将语言指令和机器人状态作为输入,输出一个奖励值。然后,使用学习到的奖励函数和离线强化学习算法,预训练一个语言条件化的策略。最后,对于新的任务,使用学习到的奖励函数对预训练策略进行微调,以适应新的任务要求。
关键创新:ReWiND的关键创新在于学习了一个能够泛化到未见任务的语言条件化奖励函数。该奖励函数能够根据语言指令准确评估机器人行为的优劣,从而引导机器人学习新的任务。与传统的奖励函数设计方法相比,ReWiND的方法更加灵活和高效,并且能够实现仅通过语言指令学习机器人操作任务。
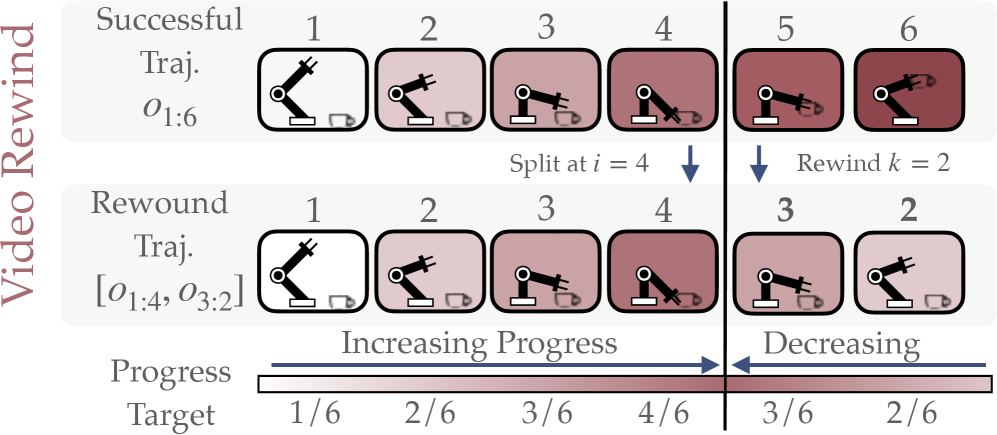
关键设计:奖励函数通常采用神经网络结构,输入包括语言指令的嵌入向量和机器人状态。损失函数的设计目标是使奖励函数能够准确预测示教数据中的奖励值,并且能够区分好的行为和坏的行为。策略学习阶段采用离线强化学习算法,例如Behavior Cloning或CQL,以提高策略的稳定性和泛化能力。微调阶段采用在线强化学习算法,例如PPO,以快速适应新的任务。
🖼️ 关键图片

📊 实验亮点
ReWiND在奖励泛化和策略对齐指标上优于基线方法高达2.4倍。在模拟环境中,ReWiND能够以2倍的效率适应新任务。在真实世界的预训练双臂策略上,ReWiND实现了5倍的性能提升。这些结果表明,ReWiND是一种高效且通用的机器人学习方法。
🎯 应用场景
ReWiND具有广泛的应用前景,例如在智能制造、家庭服务、医疗康复等领域。它可以帮助机器人快速适应新的任务,提高生产效率和服务质量。例如,在智能制造中,可以通过语言指令引导机器人完成不同的装配任务;在家庭服务中,可以通过语言指令引导机器人完成不同的家务任务。
📄 摘要(原文)
We introduce ReWiND, a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Standard reinforcement learning (RL) and imitation learning methods require expert supervision through human-designed reward functions or demonstrations for every new task. In contrast, ReWiND starts from a small demonstration dataset to learn: (1) a data-efficient, language-conditioned reward function that labels the dataset with rewards, and (2) a language-conditioned policy pre-trained with offline RL using these rewards. Given an unseen task variation, ReWiND fine-tunes the pre-trained policy using the learned reward function, requiring minimal online interaction. We show that ReWiND's reward model generalizes effectively to unseen tasks, outperforming baselines by up to 2.4x in reward generalization and policy alignment metrics. Finally, we demonstrate that ReWiND enables sample-efficient adaptation to new tasks, beating baselines by 2x in simulation and improving real-world pretrained bimanual policies by 5x, taking a step towards scalable, real-world robot learning. See website at https://rewind-reward.github.io/.