Counterfactual Behavior Cloning: Offline Imitation Learning from Imperfect Human Demonstrations
作者: Shahabedin Sagheb, Dylan P. Losey
分类: cs.RO
发布日期: 2025-05-16
💡 一句话要点
提出Counter-BC,从不完美的人类演示中进行离线模仿学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 行为克隆 离线学习 反事实推理 机器人学习
📋 核心要点
- 现有模仿学习方法直接模仿人类演示,但人类演示通常包含噪声和次优行为,限制了学习效果。
- Counter-BC通过扩展数据集,包含人类可能意图但未展示的反事实动作,从而推断潜在的策略。
- 实验证明Counter-BC在模拟和真实环境中,能从不完美的人类演示中学习,优于现有方法。
📝 摘要(中文)
从人类学习充满挑战,因为人类并非完美的老师。当普通人向机器人展示一项新任务时,他们不可避免地会犯错(例如,输入有噪声的动作)并提供次优示例(例如,目标超调)。现有方法通过模仿人类教师提供的确切行为来进行学习,但这种方法从根本上受到限制,因为演示本身并不完美。本文通过使机器人能够推断人类教师的意图,而不仅仅是考虑人类实际展示的内容,从而推进了离线模仿学习。我们假设人类的所有演示都在试图传达一个单一且一致的策略,而其行为中的噪声和次优性会混淆数据并引入不必要的复杂性。为了恢复潜在的策略并了解人类教师的意图,我们引入了Counter-BC,这是行为克隆的广义版本。Counter-BC扩展了给定的数据集,以包括接近人类展示行为的动作(即,人类教师可能想要但实际上没有展示的反事实动作)。在训练过程中,Counter-BC自主地修改此扩展区域内的人类演示,以达到一个简单且一致的策略,该策略解释了人类数据集中的潜在趋势。从理论上讲,我们证明了Counter-BC可以从不完美的数据、多个用户和不同技能水平的教师那里提取所需的策略。在经验上,我们将Counter-BC与模拟和真实环境中的最先进的替代方案进行比较,这些环境具有嘈杂的演示、标准化数据集和真实的人类教师。
🔬 方法详解
问题定义:论文旨在解决从不完美的人类演示中进行离线模仿学习的问题。现有行为克隆(BC)方法直接模仿人类的动作,但人类演示数据通常包含噪声、次优行为,甚至错误,导致学习到的策略性能受限。痛点在于如何从这些不完美的数据中提取出人类教师的真实意图。
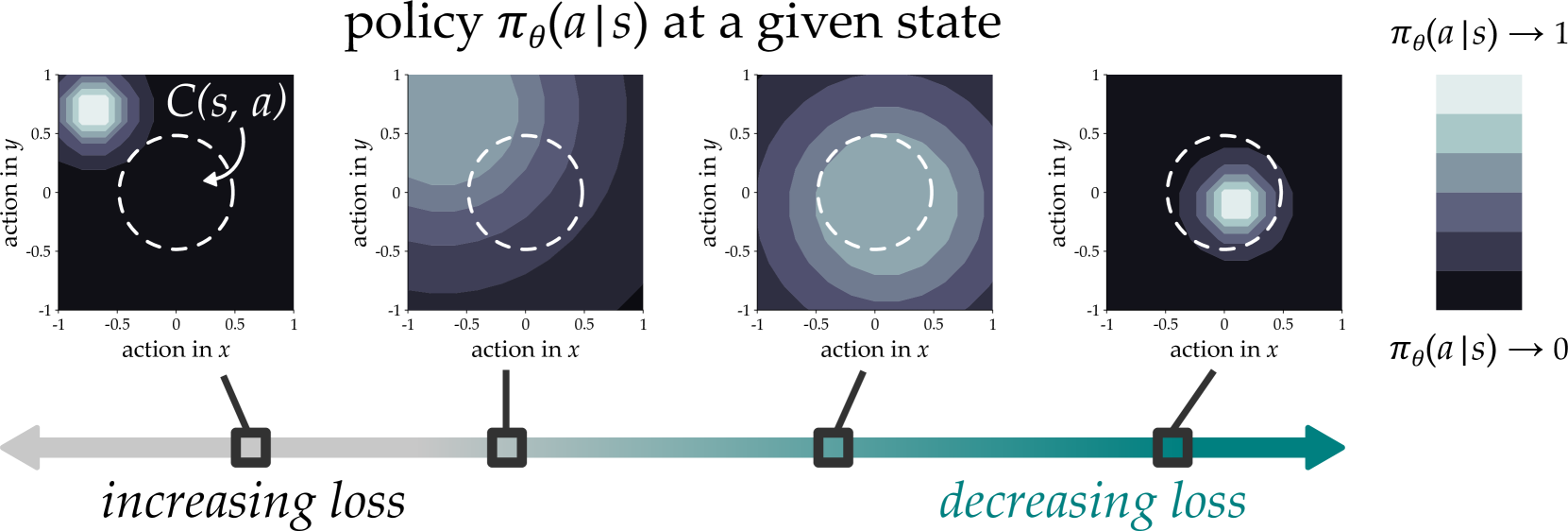
核心思路:论文的核心思路是假设人类教师的演示数据虽然不完美,但都试图表达一个潜在的、一致的策略。Counter-BC通过探索与人类演示数据相近的反事实动作,来推断这个潜在策略。这种方法类似于“如果人类稍微改变一下动作,会发生什么”的反事实推理,从而修正数据中的噪声和次优性。
技术框架:Counter-BC的整体框架可以概括为以下几个步骤:1. 数据集扩展:在原始的人类演示数据集基础上,生成反事实动作,扩展数据集。这些反事实动作与原始动作相近,代表了人类教师可能采取的其他行为。2. 策略学习:使用扩展后的数据集训练策略网络。训练目标是找到一个简单且一致的策略,能够解释原始数据和反事实数据。3. 策略优化:通过某种优化算法,调整策略网络的参数,使其能够更好地拟合扩展后的数据集,并提取出人类教师的潜在策略。
关键创新:Counter-BC的关键创新在于引入了反事实推理的概念,用于修正不完美的人类演示数据。与传统的行为克隆方法直接模仿人类动作不同,Counter-BC试图理解人类的意图,并学习一个更鲁棒、更泛化的策略。这种方法能够有效地处理数据中的噪声和次优性,提高学习效果。
关键设计:论文的关键设计包括:1. 反事实动作的生成方式:如何生成与原始动作相近且有意义的反事实动作?这可能涉及到对动作空间的探索和采样。2. 策略网络的结构:选择合适的网络结构,例如深度神经网络,来表示和学习策略。3. 损失函数的设计:设计合适的损失函数,鼓励策略网络拟合扩展后的数据集,并提取出人类教师的潜在策略。例如,可以使用行为克隆损失,同时加入正则化项,鼓励策略的简单性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Counter-BC在模拟和真实环境中均优于现有的行为克隆方法。在噪声演示数据集中,Counter-BC能够显著提高学习到的策略的性能。与直接模仿人类动作的方法相比,Counter-BC能够更好地泛化到新的环境和任务。论文还提供了消融实验,验证了反事实推理的有效性。
🎯 应用场景
Counter-BC具有广泛的应用前景,例如机器人操作、自动驾驶、游戏AI等领域。它可以帮助机器人从人类的演示中学习复杂的任务,即使人类的演示数据不完美。通过学习人类的意图,机器人可以更好地适应不同的环境和任务,提高自主性和智能化水平。未来,Counter-BC可以与其他模仿学习方法相结合,进一步提高学习效果。
📄 摘要(原文)
Learning from humans is challenging because people are imperfect teachers. When everyday humans show the robot a new task they want it to perform, humans inevitably make errors (e.g., inputting noisy actions) and provide suboptimal examples (e.g., overshooting the goal). Existing methods learn by mimicking the exact behaviors the human teacher provides -- but this approach is fundamentally limited because the demonstrations themselves are imperfect. In this work we advance offline imitation learning by enabling robots to extrapolate what the human teacher meant, instead of only considering what the human actually showed. We achieve this by hypothesizing that all of the human's demonstrations are trying to convey a single, consistent policy, while the noise and sub-optimality within their behaviors obfuscates the data and introduces unintentional complexity. To recover the underlying policy and learn what the human teacher meant, we introduce Counter-BC, a generalized version of behavior cloning. Counter-BC expands the given dataset to include actions close to behaviors the human demonstrated (i.e., counterfactual actions that the human teacher could have intended, but did not actually show). During training Counter-BC autonomously modifies the human's demonstrations within this expanded region to reach a simple and consistent policy that explains the underlying trends in the human's dataset. Theoretically, we prove that Counter-BC can extract the desired policy from imperfect data, multiple users, and teachers of varying skill levels. Empirically, we compare Counter-BC to state-of-the-art alternatives in simulated and real-world settings with noisy demonstrations, standardized datasets, and real human teachers. See videos of our work here: https://youtu.be/XaeOZWhTt68