FlowDreamer: A RGB-D World Model with Flow-based Motion Representations for Robot Manipulation
作者: Jun Guo, Xiaojian Ma, Yikai Wang, Min Yang, Huaping Liu, Qing Li
分类: cs.RO, cs.CV
发布日期: 2025-05-15
备注: Project page: see https://sharinka0715.github.io/FlowDreamer/
💡 一句话要点
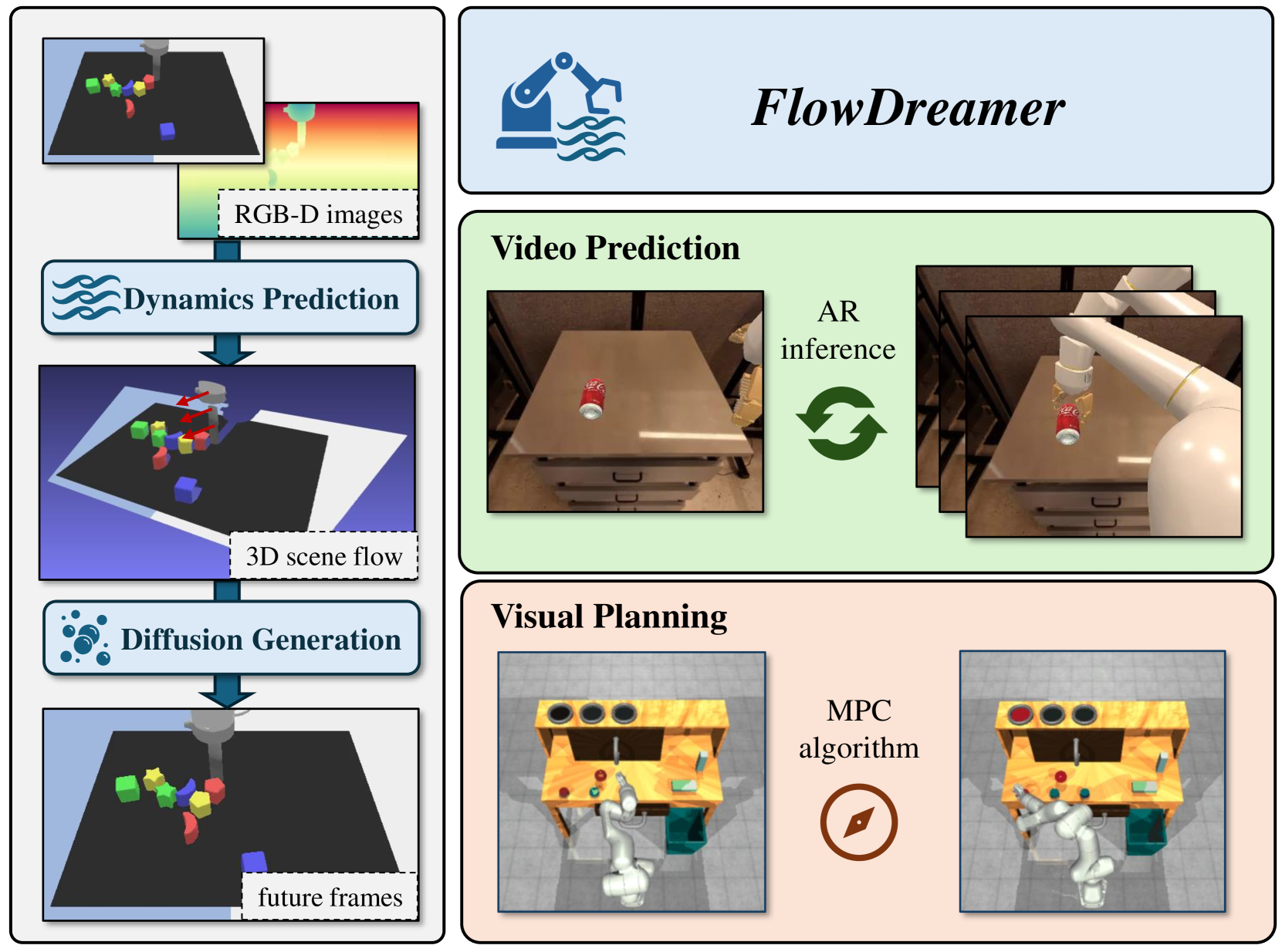
FlowDreamer:基于光流运动表示的RGB-D世界模型,用于机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 世界模型 RGB-D 场景光流 扩散模型
📋 核心要点
- 现有世界模型在机器人操作中,通常隐式处理动态预测,缺乏对运动信息的显式建模,限制了预测精度。
- FlowDreamer通过预测3D场景光流来显式表示运动信息,并结合扩散模型进行未来帧预测,实现更精确的视觉预测。
- 实验结果表明,FlowDreamer在语义相似性、像素质量和机器人操作成功率方面均优于现有RGB-D世界模型。
📝 摘要(中文)
本文研究了如何训练更好的用于机器人操作的视觉世界模型,即能够通过过去帧和机器人动作来预测未来视觉观测的模型。特别地,我们考虑在RGB-D帧上运行的世界模型(RGB-D世界模型)。与主要隐式地处理动态预测并将动态预测与视觉渲染整合在单个模型中的典型方法不同,我们引入了FlowDreamer,它采用3D场景光流作为显式的运动表示。FlowDreamer首先使用U-Net从过去的帧和动作条件预测3D场景光流,然后扩散模型将利用场景光流预测未来帧。尽管FlowDreamer具有模块化的性质,但它是端到端训练的。我们在4个不同的基准上进行了实验,涵盖了视频预测和视觉规划任务。结果表明,在各种机器人操作领域,与其他基线RGB-D世界模型相比,FlowDreamer在语义相似性方面提高了7%,在像素质量方面提高了11%,在成功率方面提高了6%。
🔬 方法详解
问题定义:论文旨在解决机器人操作中视觉世界模型预测精度不高的问题。现有方法通常将动态预测和视觉渲染整合在单个模型中,隐式地处理动态信息,缺乏对运动信息的显式建模,导致预测结果不够准确,难以支持复杂的机器人操作任务。
核心思路:论文的核心思路是将运动信息显式地建模为3D场景光流。通过预测场景光流,模型可以更准确地理解场景中物体的运动轨迹,从而更精确地预测未来的视觉观测。这种显式建模的方式有助于提高模型的可解释性和泛化能力。
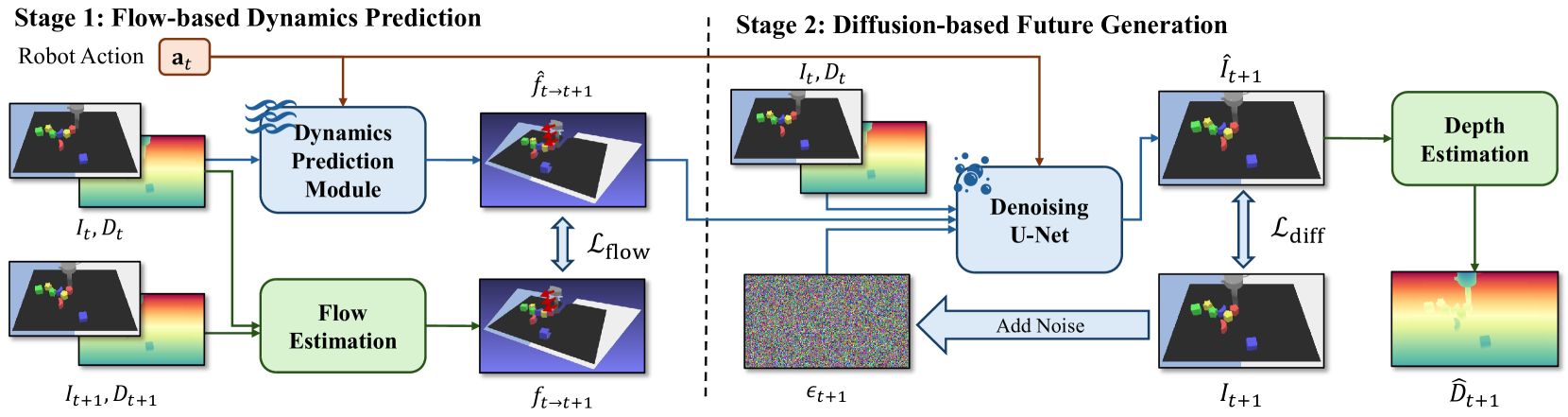
技术框架:FlowDreamer包含两个主要模块:光流预测模块和未来帧预测模块。光流预测模块使用U-Net结构,以过去的帧和机器人动作为输入,预测3D场景光流。未来帧预测模块使用扩散模型,以预测的场景光流为条件,生成未来的RGB-D帧。整个模型采用端到端的方式进行训练。
关键创新:FlowDreamer的关键创新在于使用3D场景光流作为显式的运动表示。与以往隐式地处理动态信息的方法不同,FlowDreamer通过显式地预测场景光流,使得模型能够更准确地理解和预测场景中的运动。此外,结合U-Net和扩散模型,实现了高效且高质量的未来帧预测。
关键设计:光流预测模块采用U-Net结构,能够有效地提取图像特征并预测密集的场景光流场。未来帧预测模块使用扩散模型,通过逐步去噪的方式生成高质量的图像。损失函数包括光流预测损失和图像重建损失,用于优化模型的参数。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FlowDreamer在四个不同的机器人操作基准测试中均取得了显著的性能提升。在语义相似性方面,FlowDreamer比其他基线RGB-D世界模型提高了7%;在像素质量方面,提高了11%;在机器人操作成功率方面,提高了6%。这些结果表明,FlowDreamer能够更准确地预测未来的视觉观测,从而提高机器人操作的性能。
🎯 应用场景
FlowDreamer具有广泛的应用前景,可用于机器人操作、自动驾驶、增强现实等领域。在机器人操作中,它可以帮助机器人更好地理解环境,预测未来的状态,从而实现更智能、更灵活的操作。在自动驾驶中,它可以用于预测周围车辆和行人的运动轨迹,提高驾驶安全性。在增强现实中,它可以用于生成更逼真的虚拟场景,增强用户体验。
📄 摘要(原文)
This paper investigates training better visual world models for robot manipulation, i.e., models that can predict future visual observations by conditioning on past frames and robot actions. Specifically, we consider world models that operate on RGB-D frames (RGB-D world models). As opposed to canonical approaches that handle dynamics prediction mostly implicitly and reconcile it with visual rendering in a single model, we introduce FlowDreamer, which adopts 3D scene flow as explicit motion representations. FlowDreamer first predicts 3D scene flow from past frame and action conditions with a U-Net, and then a diffusion model will predict the future frame utilizing the scene flow. FlowDreamer is trained end-to-end despite its modularized nature. We conduct experiments on 4 different benchmarks, covering both video prediction and visual planning tasks. The results demonstrate that FlowDreamer achieves better performance compared to other baseline RGB-D world models by 7% on semantic similarity, 11% on pixel quality, and 6% on success rate in various robot manipulation domains.