Unfettered Forceful Skill Acquisition with Physical Reasoning and Coordinate Frame Labeling
作者: William Xie, Max Conway, Yutong Zhang, Nikolaus Correll
分类: cs.RO
发布日期: 2025-05-14
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
利用物理推理和坐标系标注,实现VLM驱动的通用力控技能学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉语言模型 力控 机器人操作 物理推理 坐标系标注
📋 核心要点
- 现有方法难以让VLM显式推理力,限制了其在操作任务中的泛化能力和鲁棒性。
- 通过提示VLM生成力(wrenches)而非轨迹,并结合坐标系标注,使VLM能显式推理力。
- 实验表明,该方法在多个操作任务中实现了零样本泛化,并能从任务失败中恢复。
📝 摘要(中文)
视觉语言模型(VLM)展现了对物理世界的广泛知识,包括对物理和空间属性、可供性和运动的直觉。通过微调,VLM也可以原生生成机器人轨迹。本文证明,激发力(wrenches)而非轨迹,能使VLM显式地推理力,并在一系列操作任务中实现零样本泛化,而无需预训练。通过在机器人相机图像上叠加相关坐标系的视觉表示来增强查询,从而实现这一点。首先,展示了这种添加如何实现一个通用的运动控制框架,并在四个任务(打开和关闭盖子、推动杯子或椅子)中进行评估,涵盖平移和旋转运动、不同数量级的力和位置、不同的相机视角、标注方案和两个机器人平台,超过220次实验,在四个任务中实现了51%的成功率。然后,证明了所提出的框架使VLM能够持续推理交互反馈,以从任务失败或未完成中恢复,无论是否有人工监督。最后,观察到带有视觉注释和具身推理的提示方案可以绕过VLM的安全措施。描述了提示组件对有害行为引发的贡献,并讨论了其对开发具身推理的影响。代码、视频和数据可在https://scalingforce.github.io/上找到。
🔬 方法详解
问题定义:论文旨在解决如何让视觉语言模型(VLM)更好地理解和利用力信息,从而在机器人操作任务中实现更好的泛化性和鲁棒性。现有方法通常直接让VLM生成轨迹,而忽略了力在操作过程中的重要作用,导致VLM难以处理复杂的物理交互,并且容易受到环境变化的影响。
核心思路:论文的核心思路是让VLM显式地推理力(wrenches),而不是直接生成轨迹。通过将力作为VLM的输出,并结合坐标系标注,使VLM能够更好地理解物体之间的物理关系和交互作用,从而实现更好的操作性能。这种方法类似于人类在操作物体时会考虑施加的力和物体的受力情况,从而更好地控制操作过程。
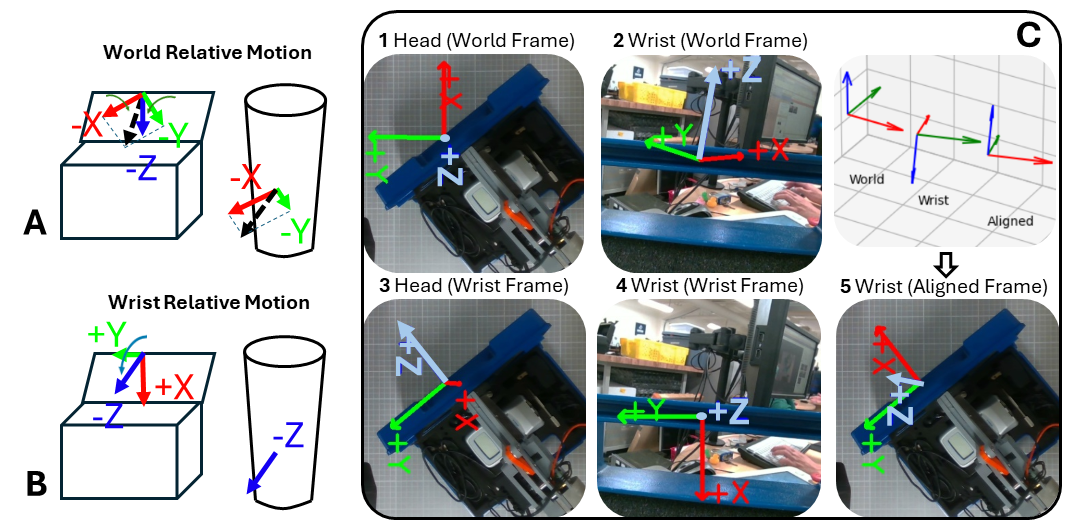
技术框架:整体框架包括以下几个主要模块:1) 图像输入:从机器人相机获取图像;2) 坐标系标注:在图像上叠加相关的坐标系视觉表示;3) VLM查询:使用带有坐标系标注的图像和自然语言指令查询VLM,要求其输出力(wrenches);4) 力控执行:将VLM输出的力转化为机器人控制指令,控制机器人执行操作。该框架允许VLM持续推理交互反馈,以从任务失败或未完成中恢复。
关键创新:最重要的技术创新点在于让VLM显式地推理力,而不是直接生成轨迹。这种方法与现有方法的本质区别在于,它更加注重物理交互过程中的力信息,从而使VLM能够更好地理解和控制操作过程。此外,通过坐标系标注,可以帮助VLM更好地理解物体之间的空间关系,从而提高操作的准确性和鲁棒性。
关键设计:论文的关键设计包括:1) 使用力(wrenches)作为VLM的输出;2) 在图像上叠加相关的坐标系视觉表示,以帮助VLM理解物体之间的空间关系;3) 设计合适的提示语,引导VLM生成正确的力;4) 使用力控方法将VLM输出的力转化为机器人控制指令。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
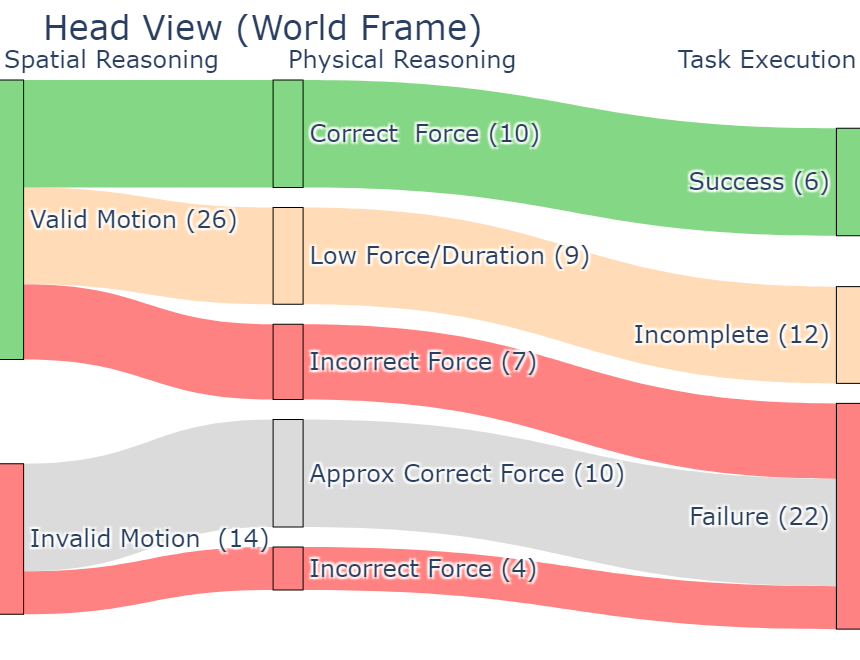
实验结果表明,该方法在四个不同的操作任务(打开和关闭盖子、推动杯子或椅子)中实现了51%的成功率。这些任务涵盖了平移和旋转运动、不同数量级的力和位置、不同的相机视角、标注方案和两个机器人平台。此外,该方法还能够使VLM持续推理交互反馈,以从任务失败或未完成中恢复,展示了其良好的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要精细操作和力控制的机器人任务,例如装配、抓取、操作工具等。通过利用VLM的强大推理能力,可以使机器人更好地理解和适应复杂的物理环境,从而实现更智能、更灵活的操作。未来,该技术有望在工业自动化、医疗机器人、家庭服务机器人等领域发挥重要作用。
📄 摘要(原文)
Vision language models (VLMs) exhibit vast knowledge of the physical world, including intuition of physical and spatial properties, affordances, and motion. With fine-tuning, VLMs can also natively produce robot trajectories. We demonstrate that eliciting wrenches, not trajectories, allows VLMs to explicitly reason about forces and leads to zero-shot generalization in a series of manipulation tasks without pretraining. We achieve this by overlaying a consistent visual representation of relevant coordinate frames on robot-attached camera images to augment our query. First, we show how this addition enables a versatile motion control framework evaluated across four tasks (opening and closing a lid, pushing a cup or chair) spanning prismatic and rotational motion, an order of force and position magnitude, different camera perspectives, annotation schemes, and two robot platforms over 220 experiments, resulting in 51% success across the four tasks. Then, we demonstrate that the proposed framework enables VLMs to continually reason about interaction feedback to recover from task failure or incompletion, with and without human supervision. Finally, we observe that prompting schemes with visual annotation and embodied reasoning can bypass VLM safeguards. We characterize prompt component contribution to harmful behavior elicitation and discuss its implications for developing embodied reasoning. Our code, videos, and data are available at: https://scalingforce.github.io/.