Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
作者: Justin Yu, Letian Fu, Huang Huang, Karim El-Refai, Rares Andrei Ambrus, Richard Cheng, Muhammad Zubair Irshad, Ken Goldberg
分类: cs.RO
发布日期: 2025-05-14
💡 一句话要点
提出Real2Render2Real以解决机器人数据收集成本高的问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 数据生成 3D重建 视觉-语言-动作模型 模仿学习 成本降低 高保真度演示
📋 核心要点
- 现有的机器人数据收集方法依赖于人类遥操作,成本高且效率低,限制了数据的多样性和规模。
- 本文提出的R2R2R方法通过3D重建和视频演示生成高质量的机器人训练数据,避免了传统方法的局限。
- 实验结果显示,使用R2R2R生成的数据训练的模型在性能上与使用大量遥操作数据训练的模型相当,显著提高了数据利用效率。
📝 摘要(中文)
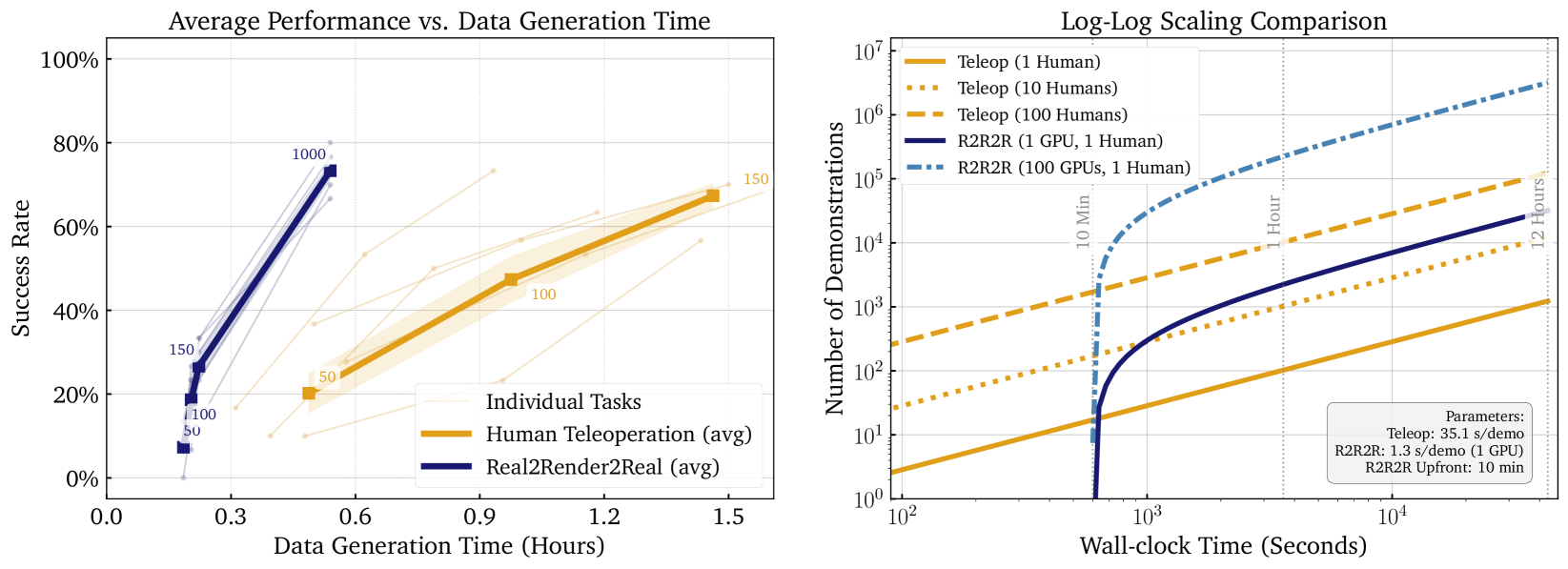
随着机器人学习的需求增加,获取大量多样化的数据集变得至关重要。然而,现有的数据收集方式——人类遥操作,成本高且受限于人工努力和物理机器人访问。本文提出了一种新方法Real2Render2Real(R2R2R),无需依赖物体动力学仿真或机器人硬件的遥操作,即可生成机器人训练数据。该方法通过智能手机捕获的物体扫描和人类演示视频,重建详细的3D物体几何形状和外观,并跟踪6自由度的物体运动,从而渲染出数千个高视觉保真度的机器人无关演示。实验表明,基于R2R2R数据训练的模型性能可与基于150个遥操作演示训练的模型相媲美。
🔬 方法详解
问题定义:本文旨在解决机器人学习中数据收集成本高、效率低的问题。现有的遥操作方法不仅耗时耗力,而且难以获取多样化的数据集。
核心思路:R2R2R方法通过智能手机扫描和人类演示视频,重建3D物体的几何形状和外观,生成高保真度的机器人演示数据,避免了物体动力学仿真和遥操作的需求。
技术框架:R2R2R的整体架构包括数据输入(手机扫描和视频)、3D重建模块、运动跟踪模块以及渲染模块。通过3D Gaussian Splatting技术,灵活生成和合成物体轨迹,最终输出可与现有机器人学习模型兼容的数据。
关键创新:R2R2R的核心创新在于其无需依赖物体动力学仿真,利用3D重建和视频演示生成高质量数据,显著降低了数据收集的成本和复杂性。
关键设计:该方法采用3D Gaussian Splatting技术进行灵活的资产生成和轨迹合成,生成的3D表示转换为网格以保持与可扩展渲染引擎的兼容性,同时关闭碰撞建模以简化计算。实验中,模型训练使用的损失函数和网络结构经过优化,以提高生成数据的质量和模型的学习效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于R2R2R生成的数据训练的模型在性能上与使用150个遥操作演示训练的模型相当,展示了R2R2R在数据效率上的显著提升。这一成果表明,单一的人类演示足以训练出高效的机器人模型,极大地降低了数据收集的需求。
🎯 应用场景
该研究的潜在应用领域包括机器人学习、自动化制造、智能家居等。通过降低数据收集成本,R2R2R能够加速机器人技术的开发和应用,推动智能机器人在各行业的普及与应用,具有重要的实际价值和长远影响。
📄 摘要(原文)
Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com