Exploring Pose-Guided Imitation Learning for Robotic Precise Insertion
作者: Han Sun, Yizhao Wang, Zhenning Zhou, Shuai Wang, Haibo Yang, Jingyuan Sun, Qixin Cao
分类: cs.RO
发布日期: 2025-05-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于姿态引导的模仿学习方法,用于机器人高精度插入任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 机器人操作 高精度插入 姿态估计 扩散模型
📋 核心要点
- 现有模仿学习方法在精密操作任务中表现不佳,且依赖低效的图像/点云观测。
- 利用物体SE(3)姿态信息引导模仿学习,设计姿态引导的扩散策略,提升学习效率。
- 实验表明,该方法仅需少量演示即可完成间隙0.01mm的精密插入任务,泛化性更强。
📝 摘要(中文)
本文探索将SE(3)物体姿态引入模仿学习,提出基于姿态引导的高效模仿学习方法,用于机器人高精度插入任务。首先,提出了一种精确插入扩散策略,该策略利用相对SE(3)姿态作为观察-动作对,对源物体相对于目标物体的SE(3)姿态轨迹进行建模。其次,探索将RGBD数据引入姿态引导的扩散策略。具体而言,设计了一个目标条件RGBD编码器来捕获当前状态和目标状态之间的差异。此外,提出了一种姿态引导的残差门控融合方法,该方法以姿态特征为骨干,通过自适应门控机制选择性地补偿姿态特征的不足。在6个机器人高精度插入任务上评估了我们的方法,证明了仅使用7-10个演示即可获得具有竞争力的性能。实验表明,所提出的方法可以成功完成间隙约为0.01毫米的精密插入任务。实验结果突出了其相对于现有基线的卓越效率和泛化能力。
🔬 方法详解
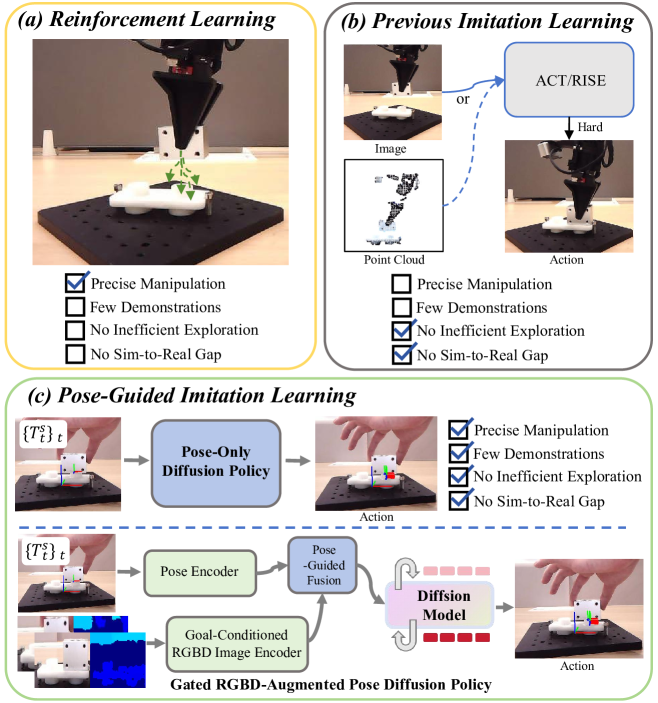
问题定义:现有机器人模仿学习方法在处理高精度插入任务时面临挑战。传统方法依赖于图像或点云等高维、低效的观测数据,导致学习效率低下,难以泛化到新的场景。此外,精确插入任务对位姿精度要求极高,现有方法难以满足。
核心思路:论文的核心思路是将物体的SE(3)姿态信息融入模仿学习框架中。SE(3)姿态能够精确描述物体的位置和姿态,相比于原始图像或点云,具有更高的信息密度和更强的表达能力。通过直接学习基于姿态的策略,可以显著提高学习效率和精度。
技术框架:该方法包含两个主要组成部分:1) 精确插入扩散策略,利用相对SE(3)姿态作为观察-动作对,学习源物体相对于目标物体的姿态轨迹。2) 姿态引导的RGBD融合模块,使用目标条件RGBD编码器提取视觉特征,并通过残差门控融合机制,选择性地补偿姿态特征的不足。整体流程是,首先利用RGBD数据估计物体姿态,然后将姿态信息输入到扩散策略中,生成动作序列,控制机器人完成插入任务。
关键创新:该方法最重要的创新点在于将SE(3)姿态信息作为模仿学习的核心输入。与直接从图像或点云学习相比,基于姿态的学习能够更有效地利用专家演示数据,提高学习效率和精度。此外,提出的姿态引导的残差门控融合机制,能够有效地融合姿态信息和视觉信息,进一步提升策略的鲁棒性。
关键设计:精确插入扩散策略使用扩散模型学习姿态轨迹的分布。目标条件RGBD编码器使用卷积神经网络提取RGBD图像的特征,并将其与目标姿态信息进行融合。残差门控融合机制使用门控单元控制RGBD特征对姿态特征的补偿程度,从而实现自适应的特征融合。损失函数包括姿态预测损失和动作预测损失,用于优化扩散模型和RGBD编码器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在6个机器人高精度插入任务上取得了显著的性能提升。仅使用7-10个演示,即可成功完成间隙约为0.01毫米的精密插入任务,显著优于现有的基于图像或点云的模仿学习方法。实验还验证了该方法具有良好的泛化能力,能够在不同的场景和物体上实现精确插入。
🎯 应用场景
该研究成果可应用于各种需要高精度操作的机器人任务,例如电子元件组装、医疗器械操作、精密仪器维修等。通过模仿学习,机器人可以快速学习并执行复杂的插入动作,提高生产效率和操作精度,降低人工成本,并有望在自动化生产线和智能制造领域发挥重要作用。
📄 摘要(原文)
Recent studies have proved that imitation learning shows strong potential in the field of robotic manipulation. However, existing methods still struggle with precision manipulation task and rely on inefficient image/point cloud observations. In this paper, we explore to introduce SE(3) object pose into imitation learning and propose the pose-guided efficient imitation learning methods for robotic precise insertion task. First, we propose a precise insertion diffusion policy which utilizes the relative SE(3) pose as the observation-action pair. The policy models the source object SE(3) pose trajectory relative to the target object. Second, we explore to introduce the RGBD data to the pose-guided diffusion policy. Specifically, we design a goal-conditioned RGBD encoder to capture the discrepancy between the current state and the goal state. In addition, a pose-guided residual gated fusion method is proposed, which takes pose features as the backbone, and the RGBD features selectively compensate for pose feature deficiencies through an adaptive gating mechanism. Our methods are evaluated on 6 robotic precise insertion tasks, demonstrating competitive performance with only 7-10 demonstrations. Experiments demonstrate that the proposed methods can successfully complete precision insertion tasks with a clearance of about 0.01 mm. Experimental results highlight its superior efficiency and generalization capability compared to existing baselines. Code will be available at https://github.com/sunhan1997/PoseInsert.