LaDi-WM: A Latent Diffusion-based World Model for Predictive Manipulation
作者: Yuhang Huang, Jiazhao Zhang, Shilong Zou, Xinwang Liu, Ruizhen Hu, Kai Xu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-13 (更新: 2025-09-12)
备注: CoRL 2025
💡 一句话要点
提出LaDi-WM,一种基于潜在扩散的世界模型,用于预测性操作任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 预测性操作 扩散模型 具身智能 视觉基础模型
📋 核心要点
- 现有世界模型难以准确预测机器人与物体交互的未来视觉状态,尤其是在像素级别上生成高质量图像。
- LaDi-WM通过扩散模型预测未来状态的潜在空间,该潜在空间与预训练视觉基础模型对齐,包含几何和语义特征。
- 实验表明,LaDi-WM显著提升了策略性能,在LIBERO-LONG基准上提升27.9%,在真实世界场景中提升20%,并具有良好的泛化性。
📝 摘要(中文)
预测性操作因其通过预测状态来提升机器人策略性能的潜力,近年来在具身智能领域受到了广泛关注。然而,从世界模型中生成准确的机器人-物体交互的未来视觉状态仍然是一个众所周知的挑战,尤其是在实现高质量的像素级表示方面。为此,我们提出了LaDi-WM,一种利用扩散模型预测未来状态潜在空间的世界模型。具体来说,LaDi-WM利用了与预训练视觉基础模型(VFMs)对齐的成熟潜在空间,该空间包含几何特征(基于DINO)和语义特征(基于CLIP)。我们发现,预测潜在空间的演变比直接预测像素级图像更容易学习且更具泛化性。在LaDi-WM的基础上,我们设计了一种扩散策略,通过结合预测状态迭代地优化输出动作,从而生成更一致和准确的结果。在合成和真实世界基准上的大量实验表明,LaDi-WM显著提高了策略性能,在LIBERO-LONG基准上提高了27.9%,在真实世界场景中提高了20%。此外,我们的世界模型和策略在真实世界实验中实现了令人印象深刻的泛化能力。
🔬 方法详解
问题定义:论文旨在解决预测性操作任务中,世界模型难以准确预测机器人与物体交互的未来视觉状态,特别是生成高质量像素级图像的问题。现有方法通常直接预测像素级别的图像,这使得模型难以学习和泛化,尤其是在复杂的交互场景中。
核心思路:论文的核心思路是将世界模型的预测目标从像素空间转移到潜在空间。通过预测与预训练视觉基础模型(VFMs)对齐的潜在空间的演变,模型可以更好地捕捉场景的几何和语义信息,从而更容易学习和泛化。这种方法利用了预训练模型的先验知识,降低了学习难度。
技术框架:LaDi-WM的整体框架包括以下几个主要模块:1) 编码器:将当前状态的图像编码到潜在空间中。2) 潜在空间预测器:使用扩散模型预测未来状态的潜在表示。3) 解码器:将预测的潜在表示解码回图像空间(可选,用于可视化)。4) 策略优化器:基于预测的未来状态优化机器人策略。整个流程是,首先将当前状态编码到潜在空间,然后使用扩散模型预测未来状态的潜在表示,最后基于预测的潜在表示优化机器人策略。
关键创新:最重要的技术创新点在于使用扩散模型预测与预训练视觉基础模型对齐的潜在空间。与直接预测像素级图像相比,这种方法具有更好的学习能力和泛化能力。此外,论文还设计了一种扩散策略,通过迭代地优化输出动作,从而生成更一致和准确的结果。
关键设计:LaDi-WM的关键设计包括:1) 使用DINO和CLIP提取几何和语义特征,构建潜在空间。2) 使用扩散模型预测潜在空间的演变,扩散模型具体结构未知。3) 设计扩散策略,通过结合预测状态迭代地优化输出动作,具体优化方法未知。损失函数的设计也未知。
🖼️ 关键图片
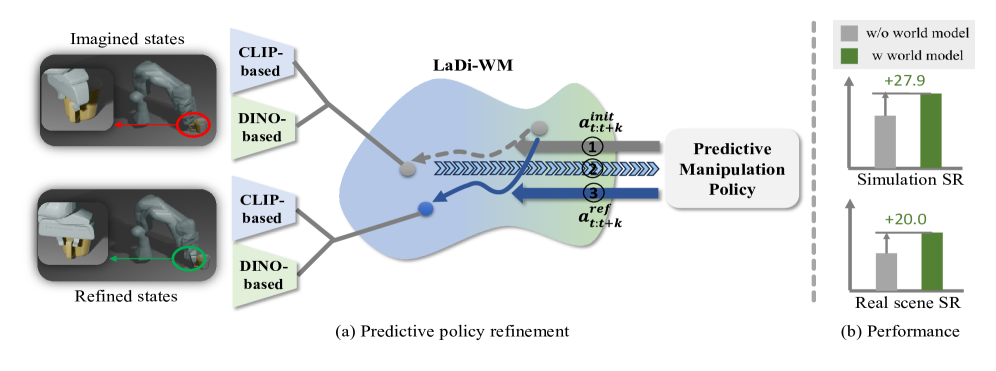
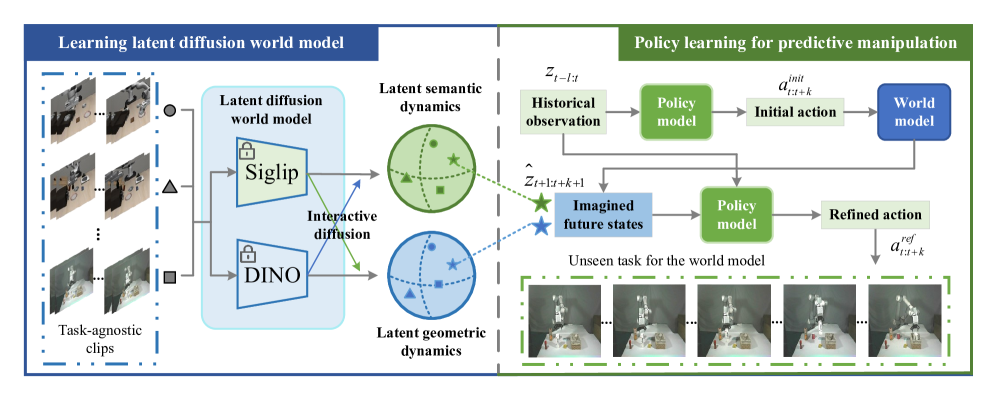
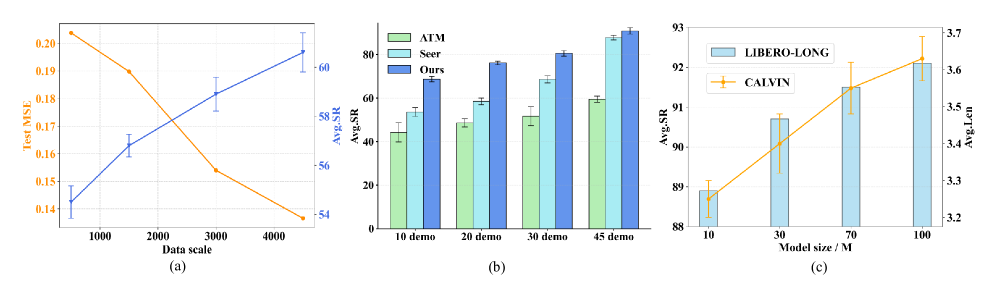
📊 实验亮点
LaDi-WM在LIBERO-LONG基准上将策略性能提高了27.9%,在真实世界场景中提高了20%。实验结果表明,LaDi-WM不仅在合成环境中表现出色,而且在真实世界中也具有良好的泛化能力。这些结果验证了LaDi-WM在预测性操作任务中的有效性和优越性。
🎯 应用场景
LaDi-WM在机器人操作领域具有广泛的应用前景,例如自动化装配、物流分拣、家庭服务机器人等。通过准确预测未来状态,机器人可以更好地规划动作,提高操作效率和安全性。该研究还有助于提升机器人在复杂环境中的适应性和泛化能力,推动具身智能的发展。
📄 摘要(原文)
Predictive manipulation has recently gained considerable attention in the Embodied AI community due to its potential to improve robot policy performance by leveraging predicted states. However, generating accurate future visual states of robot-object interactions from world models remains a well-known challenge, particularly in achieving high-quality pixel-level representations. To this end, we propose LaDi-WM, a world model that predicts the latent space of future states using diffusion modeling. Specifically, LaDi-WM leverages the well-established latent space aligned with pre-trained Visual Foundation Models (VFMs), which comprises both geometric features (DINO-based) and semantic features (CLIP-based). We find that predicting the evolution of the latent space is easier to learn and more generalizable than directly predicting pixel-level images. Building on LaDi-WM, we design a diffusion policy that iteratively refines output actions by incorporating forecasted states, thereby generating more consistent and accurate results. Extensive experiments on both synthetic and real-world benchmarks demonstrate that LaDi-WM significantly enhances policy performance by 27.9\% on the LIBERO-LONG benchmark and 20\% on the real-world scenario. Furthermore, our world model and policies achieve impressive generalizability in real-world experiments.