Real-time Capable Learning-based Visual Tool Pose Correction via Differentiable Simulation
作者: Shuyuan Yang, Zonghe Chua
分类: cs.RO
发布日期: 2025-05-13
💡 一句话要点
提出基于可微仿真的视觉工具姿态校正方法,实现微创手术机器人实时姿态估计。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱八:物理动画 (Physics-based Animation)
关键词: 微创手术机器人 姿态估计 可微渲染 视觉Transformer 实时性
📋 核心要点
- 微创手术机器人末端执行器本体感受差,导致姿态估计不准确,影响自主控制。
- 利用可微运动学和渲染在仿真环境中训练视觉Transformer,实现实时姿态估计。
- 实验证明该方法在仿真中能够有效校正噪声姿态估计,为未来实物验证奠定基础。
📝 摘要(中文)
微创机器人手术(MIRS)的自主化有潜力减轻外科医生的认知和任务负担,从而提高手术效率。然而,由于末端执行器本体感受较差(这是电缆驱动机构的一个局限性),实现精确的自主控制可能很困难。虽然机器人可能具有用于末端执行器姿态计算的关节编码器,但各种非理想因素使得整个运动学链不准确。现代基于视觉的姿态估计方法缺乏实时性,或者难以训练和泛化。在这项工作中,我们展示了一种基于视觉Transformer的姿态估计方法,该方法具有实时能力,并使用端到端可微运动学和仿真渲染进行训练。我们展示了该方法在仿真中校正噪声姿态估计的潜力,其长期目标是验证我们方法的从仿真到真实的迁移能力。
🔬 方法详解
问题定义:论文旨在解决微创手术机器人中,由于电缆驱动机构的固有缺陷,导致末端执行器姿态估计不准确的问题。现有的基于视觉的姿态估计方法要么计算速度慢,无法满足实时性要求,要么训练困难,泛化能力差,难以应用于实际手术场景。
核心思路:论文的核心思路是利用可微渲染和运动学,在仿真环境中生成大量带有精确姿态标签的训练数据,并训练一个基于视觉Transformer的姿态估计模型。通过端到端的训练方式,模型可以直接从图像像素预测工具的姿态,从而避免了传统方法中复杂的特征提取和姿态解算过程。这种方法可以充分利用仿真环境的优势,降低数据标注成本,并提高模型的鲁棒性和泛化能力。
技术框架:整体框架包含三个主要部分:1) 可微仿真环境:使用可微渲染引擎和运动学模型,生成带有精确姿态标签的合成图像。2) 视觉Transformer姿态估计器:使用视觉Transformer作为姿态估计模型,输入图像,输出工具的姿态。3) 端到端训练:通过最小化预测姿态和真实姿态之间的差异,端到端地训练整个模型。
关键创新:论文的关键创新在于将可微渲染和运动学与视觉Transformer相结合,实现了一种实时、高精度的姿态估计方法。与传统方法相比,该方法无需手动设计特征,可以直接从像素预测姿态,并且可以通过仿真数据进行训练,降低了数据标注成本。此外,可微渲染使得模型可以学习到图像和姿态之间的复杂关系,从而提高了模型的鲁棒性和泛化能力。
关键设计:论文使用了视觉Transformer作为姿态估计模型,并采用了端到端的训练方式。损失函数采用均方误差(MSE)来衡量预测姿态和真实姿态之间的差异。在仿真环境中,通过随机改变光照、纹理和背景等因素,来增加数据的多样性,提高模型的泛化能力。具体的网络结构和参数设置在论文中进行了详细描述。
🖼️ 关键图片
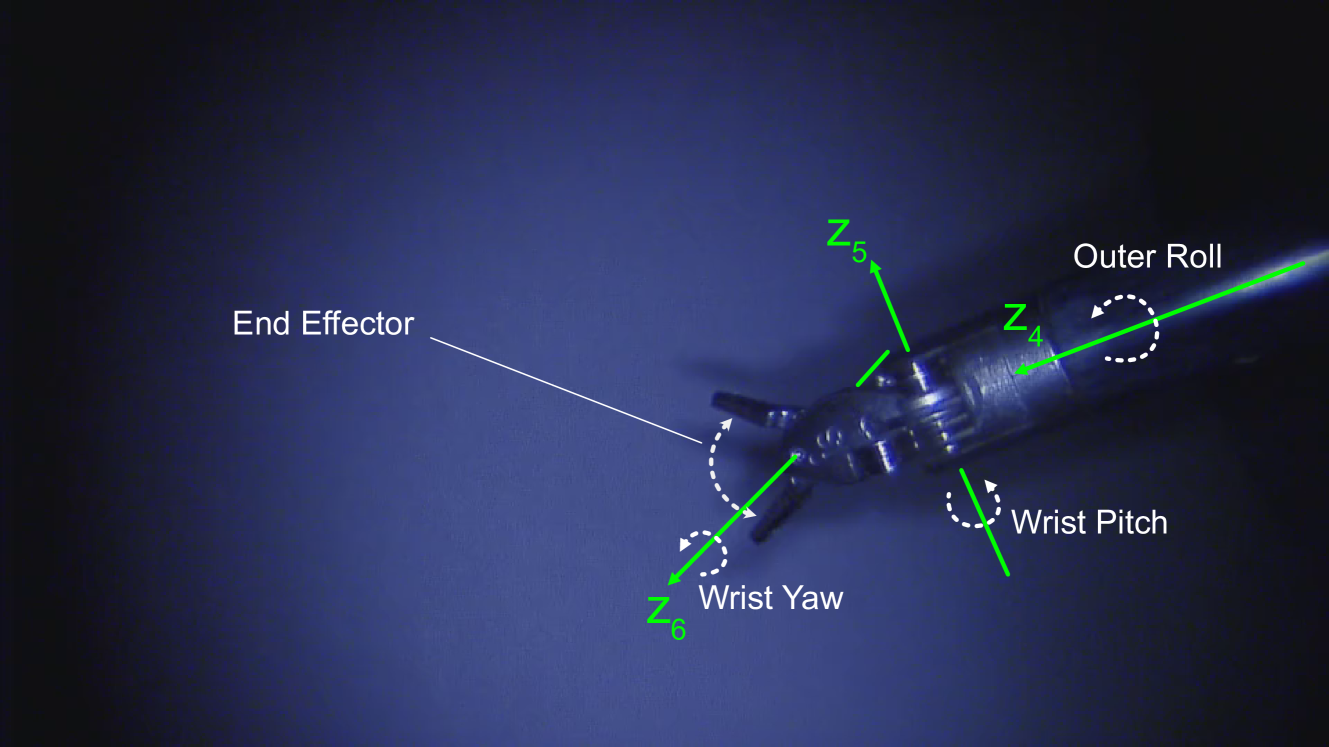
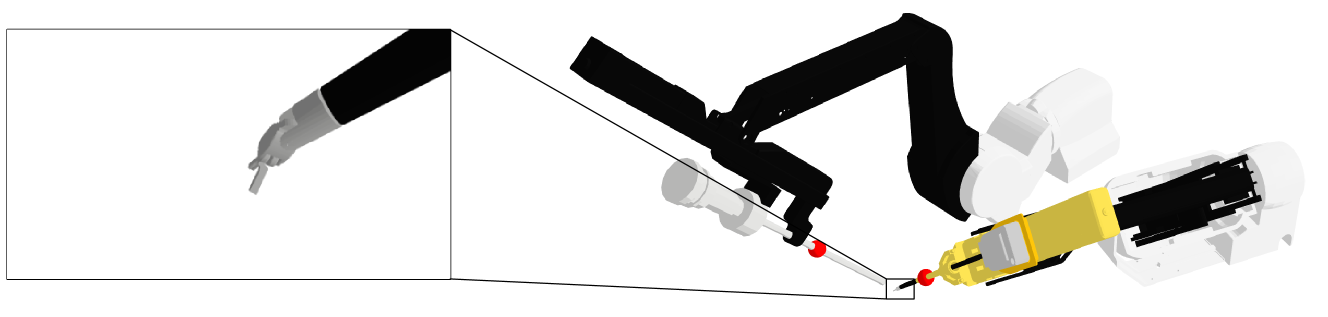

📊 实验亮点
论文在仿真环境中验证了该方法的有效性,证明其能够有效校正噪声姿态估计。虽然论文中没有提供具体的性能数据,但强调了该方法具有实时性,并且可以通过仿真数据进行训练,降低了数据标注成本。未来的工作将集中于验证该方法在真实手术场景中的性能,并探索其在其他机器人应用领域的潜力。
🎯 应用场景
该研究成果可应用于微创手术机器人自主控制、远程手术、术中导航等领域。通过提高机器人末端执行器的姿态估计精度,可以提升手术的安全性、精确性和效率,减轻外科医生的操作负担,并有望实现更复杂的手术操作。未来,该技术还可以扩展到其他机器人应用领域,例如工业机器人、无人机等。
📄 摘要(原文)
Autonomy in Minimally Invasive Robotic Surgery (MIRS) has the potential to reduce surgeon cognitive and task load, thereby increasing procedural efficiency. However, implementing accurate autonomous control can be difficult due to poor end-effector proprioception, a limitation of their cable-driven mechanisms. Although the robot may have joint encoders for the end-effector pose calculation, various non-idealities make the entire kinematics chain inaccurate. Modern vision-based pose estimation methods lack real-time capability or can be hard to train and generalize. In this work, we demonstrate a real-time capable, vision transformer-based pose estimation approach that is trained using end-to-end differentiable kinematics and rendering in simulation. We demonstrate the potential of this method to correct for noisy pose estimates in simulation, with the longer term goal of verifying the sim-to-real transferability of our approach.