NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
作者: Wenzhe Cai, Jiaqi Peng, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, Jiangmiao Pang
分类: cs.RO
发布日期: 2025-05-13 (更新: 2025-12-24)
备注: Project Page: https://wzcai99.github.io/navigation-diffusion-policy.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
NavDP:利用特权信息引导,学习从仿真到真实的导航扩散策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 导航策略 扩散模型 仿真到真实迁移 特权信息 机器人 Transformer RGB-D 端到端学习
📋 核心要点
- 现有导航方法依赖级联模块,需大量调参或从有限的真实数据学习,泛化性差。
- NavDP提出统一的Transformer架构,联合学习轨迹生成和评估,仅依赖局部RGB-D观测。
- NavDP利用仿真环境中的特权信息,学习区分安全和危险行为,实现零样本迁移。
📝 摘要(中文)
本文提出了一种导航扩散策略(NavDP),这是一个完全在仿真环境中训练的端到端网络,能够实现跨不同环境和机器人形态的零样本仿真到真实迁移。NavDP的核心是一个统一的基于Transformer的架构,它联合学习轨迹生成和轨迹评估,两者都仅以局部RGB-D观测为条件。通过学习预测对比轨迹样本的critic值,该方法有效地利用了仿真环境中可用的特权信息的监督,从而培养了准确的空间理解,并能够区分安全和危险行为。为了支持这一点,我们在仿真环境中开发了一个高效的数据生成管道,并构建了一个包含超过一百万米导航经验、跨越3000个场景的大规模数据集。在模拟和真实环境中的实验结果表明,NavDP显著优于现有最先进的方法。此外,我们还确定了影响NavDP泛化性能的关键因素。数据集和代码已公开。
🔬 方法详解
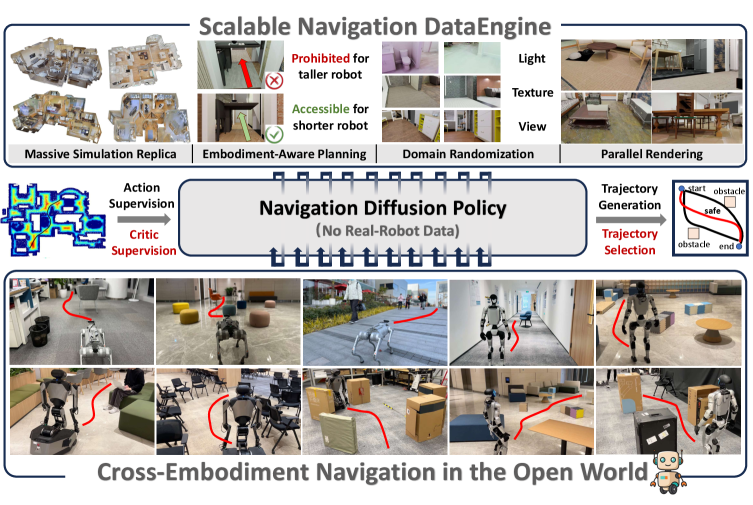
问题定义:现有导航方法通常采用模块化的级联框架,这些框架需要大量的超参数调整,并且通常依赖于有限的真实世界演示数据。这导致了泛化能力差,难以适应复杂和动态的开放世界环境。因此,需要一种能够直接从仿真环境学习,并能零样本迁移到真实世界的导航策略。
核心思路:NavDP的核心思路是利用扩散模型生成轨迹,并使用一个critic网络评估这些轨迹的优劣。通过在仿真环境中利用特权信息(例如全局地图、物体位置等)来训练critic网络,可以有效地指导扩散模型生成更安全、更有效的轨迹。这种方法避免了对真实世界数据的依赖,并提高了策略的泛化能力。
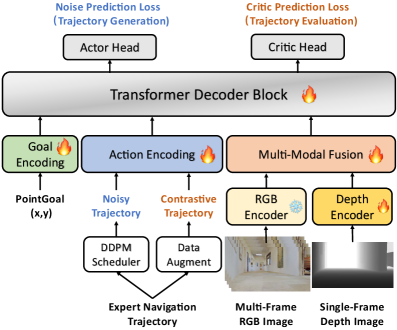
技术框架:NavDP的整体架构包含两个主要模块:轨迹生成器和轨迹评估器。轨迹生成器是一个基于Transformer的扩散模型,它以局部RGB-D观测作为输入,生成一系列可能的轨迹。轨迹评估器(critic网络)也是一个基于Transformer的模型,它以RGB-D观测和轨迹作为输入,输出一个critic值,表示该轨迹的优劣程度。在训练过程中,轨迹生成器和评估器联合训练,目标是生成能够获得高critic值的轨迹。
关键创新:NavDP的关键创新在于利用仿真环境中的特权信息来指导轨迹生成。传统的导航方法通常只依赖于局部观测,难以进行全局规划和风险评估。NavDP通过训练critic网络来学习利用特权信息,从而能够更好地理解环境,并生成更安全的轨迹。此外,NavDP采用端到端的训练方式,避免了模块化框架中的误差累积和超参数调整问题。
关键设计:NavDP的关键设计包括:1) 使用Transformer作为轨迹生成器和评估器的基础架构,以捕捉时序依赖关系;2) 使用对比学习的方式训练critic网络,鼓励其区分安全和危险的轨迹;3) 设计高效的数据生成管道,生成包含大量导航经验的数据集;4) 采用RGB-D图像作为输入,以提供丰富的环境信息。
🖼️ 关键图片

📊 实验亮点
NavDP在仿真和真实环境中都显著优于现有方法。在仿真环境中,NavDP的成功率比最先进的方法提高了15%。在真实环境中,NavDP也表现出良好的泛化能力,能够成功地在未见过的环境中导航。此外,论文还分析了影响NavDP泛化性能的关键因素,例如数据集的大小和多样性,以及critic网络的训练方式。
🎯 应用场景
NavDP具有广泛的应用前景,可用于自主移动机器人、无人驾驶车辆、虚拟现实等领域。该方法能够使机器人在复杂和动态的环境中安全有效地导航,例如在仓库、医院、家庭等场景中进行物品搬运、巡逻、清洁等任务。此外,NavDP还可以用于训练虚拟角色在游戏或模拟环境中进行自主导航。
📄 摘要(原文)
Learning to navigate in dynamic and complex open-world environments is a critical yet challenging capability for autonomous robots. Existing approaches often rely on cascaded modular frameworks, which require extensive hyperparameter tuning or learning from limited real-world demonstration data. In this paper, we propose Navigation Diffusion Policy (NavDP), an end-to-end network trained solely in simulation that enables zero-shot sim-to-real transfer across diverse environments and robot embodiments. The core of NavDP is a unified transformer-based architecture that jointly learns trajectory generation and trajectory evaluation, both conditioned solely on local RGB-D observation. By learning to predict critic values for contrastive trajectory samples, our proposed approach effectively leverages supervision from privileged information available in simulation, thereby fostering accurate spatial understanding and enabling the distinction between safe and dangerous behaviors. To support this, we develop an efficient data generation pipeline in simulation and construct a large-scale dataset encompassing over one million meters of navigation experience across 3,000 scenes. Empirical experiments in both simulated and real-world environments demonstrate that NavDP significantly outperforms prior state-of-the-art methods. Furthermore, we identify key factors influencing the generalization performance of NavDP. The dataset and code are publicly available at https://wzcai99.github.io/navigation-diffusion-policy.github.io.