End-to-End Multi-Task Policy Learning from NMPC for Quadruped Locomotion
作者: Anudeep Sajja, Shahram Khorshidi, Sebastian Houben, Maren Bennewitz
分类: cs.RO
发布日期: 2025-05-13
💡 一句话要点
提出基于NMPC专家示教的多任务策略学习框架,用于四足机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 运动控制 多任务学习 非线性模型预测控制 模仿学习
📋 核心要点
- 四足机器人运动控制面临非线性动力学、高自由度和实时计算挑战,传统方法难以兼顾性能与效率。
- 论文提出利用NMPC专家示教,通过多任务学习训练神经网络,直接从传感器数据预测动作,简化控制流程。
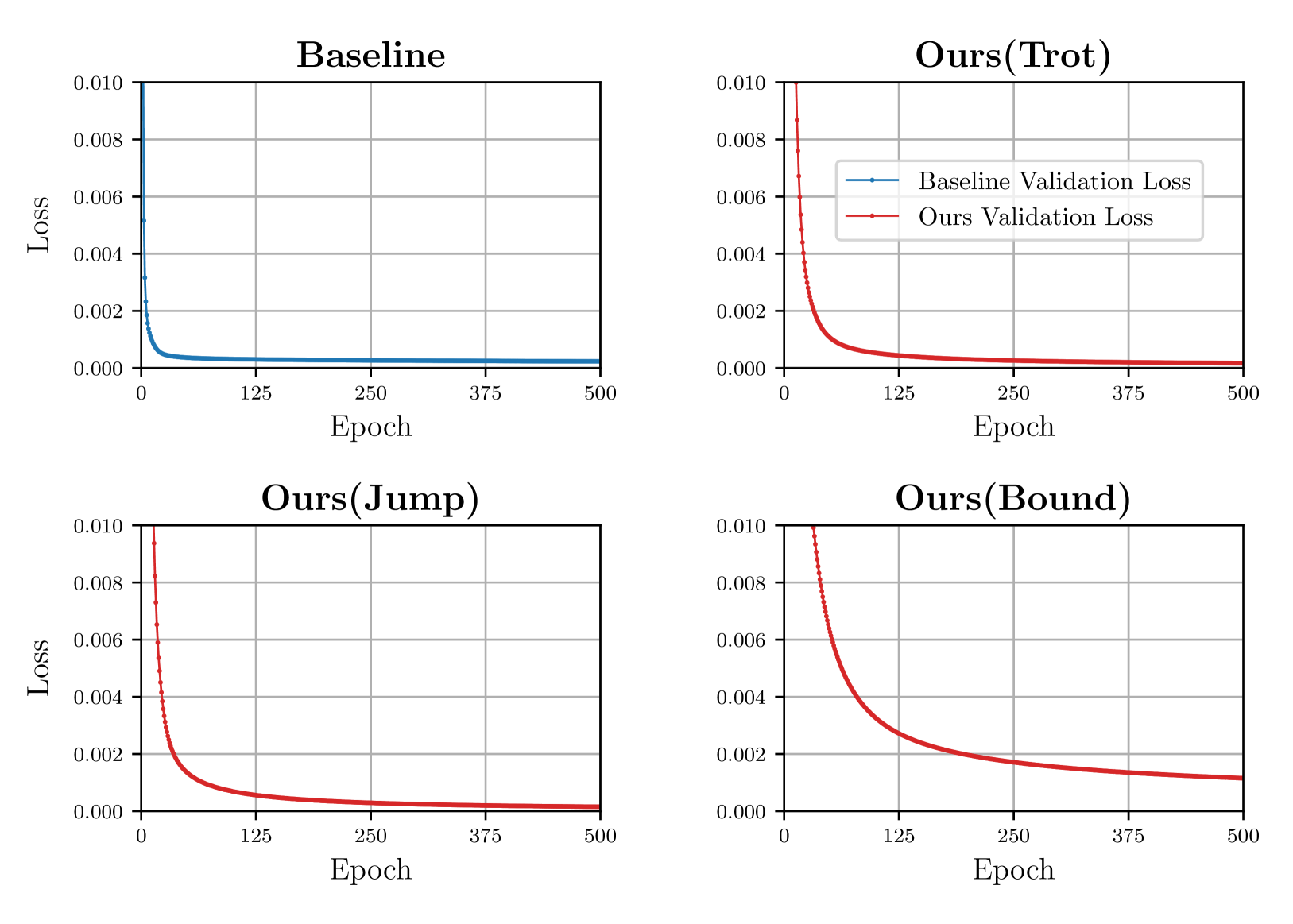
- 在Go1机器人上的实验表明,该方法能准确复现专家行为,实现平滑步态切换,并获得高$R^{2}$分数。
📝 摘要(中文)
本文提出了一种多任务学习(MTL)框架,利用非线性模型预测控制(NMPC)专家演示来训练单个神经网络,直接从原始本体感受传感器输入预测多种运动行为的动作。该方法旨在解决四足机器人由于非线性动力学、高自由度和实时控制的计算需求而难以实现高效和适应性运动的问题。在四足机器人Go1的仿真和真实硬件上进行了广泛的评估,结果表明该方法能够准确地重现专家行为,实现平滑的步态切换,并简化实时部署的控制流程。该MTL架构能够在统一策略中学习不同的步态,并在所有任务中实现预测关节目标的高$R^{2}$分数。
🔬 方法详解
问题定义:四足机器人运动控制面临着复杂环境下的挑战,传统的控制方法,如NMPC,虽然性能优异,但依赖于精确的状态估计和高昂的计算成本,难以在实际场景中部署。因此,需要一种能够从原始传感器数据直接学习控制策略,并具有实时性和适应性的方法。
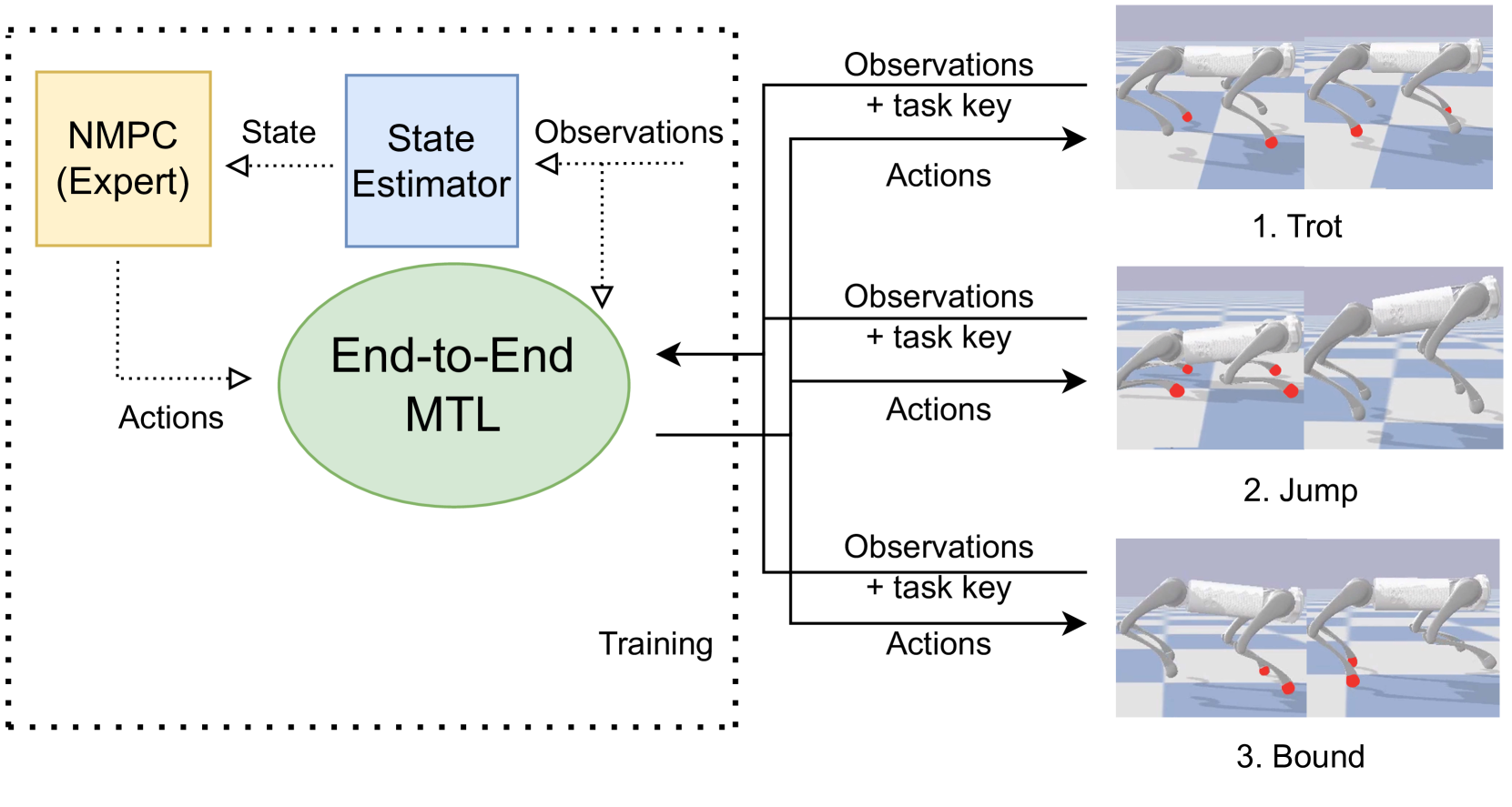
核心思路:论文的核心思路是利用NMPC作为专家,生成高质量的运动轨迹数据,然后使用多任务学习(MTL)框架训练一个神经网络,使其能够从原始本体感受传感器输入直接预测动作。通过模仿学习,神经网络可以学习到NMPC的控制策略,同时避免了NMPC的计算负担和对精确状态估计的依赖。多任务学习允许网络同时学习多种运动行为(例如不同的步态),从而提高泛化能力和效率。
技术框架:整体框架包括两个主要阶段:1) NMPC专家数据生成阶段:使用NMPC控制器在各种运动任务下控制四足机器人,并记录机器人的状态、动作和传感器数据。这些数据作为训练神经网络的专家示教。2) 多任务学习阶段:构建一个神经网络,输入为原始本体感受传感器数据,输出为机器人的关节目标。使用NMPC生成的数据训练该网络,使其能够模仿NMPC的控制策略。该网络采用多任务学习架构,每个任务对应一种运动行为。
关键创新:该论文的关键创新在于将NMPC专家示教与多任务学习相结合,实现了一种端到端的四足机器人运动控制方法。与传统的基于优化的控制方法相比,该方法具有更高的实时性和适应性。与直接从数据中学习控制策略的方法相比,该方法利用了NMPC的先验知识,能够更快地学习到高质量的控制策略。此外,多任务学习架构使得网络能够同时学习多种运动行为,提高了泛化能力。
关键设计:神经网络的输入为原始本体感受传感器数据,包括关节角度、角速度、加速度等。输出为机器人的关节目标。网络结构可以采用多层感知机(MLP)或循环神经网络(RNN),具体结构需要根据实际情况进行调整。损失函数采用均方误差(MSE),用于衡量网络预测的关节目标与NMPC生成的关节目标之间的差异。多任务学习通过共享网络参数来实现,每个任务对应一个独立的输出层。训练过程中,可以使用Adam优化器进行优化,并采用适当的学习率衰减策略。
🖼️ 关键图片

📊 实验亮点
在Go1四足机器人上的实验结果表明,该方法能够准确地重现NMPC专家的行为,实现平滑的步态切换。在仿真和真实硬件上的评估结果均表明,该方法能够获得较高的$R^{2}$分数,表明网络能够很好地学习到NMPC的控制策略。此外,该方法还能够简化控制流程,降低计算成本,使其能够在实时系统中部署。
🎯 应用场景
该研究成果可应用于各种四足机器人应用场景,例如搜救、巡检、物流等。通过学习不同的运动步态,四足机器人可以在复杂地形上实现高效和稳定的运动。此外,该方法还可以用于开发更智能的四足机器人,使其能够自主地适应不同的环境和任务。
📄 摘要(原文)
Quadruped robots excel in traversing complex, unstructured environments where wheeled robots often fail. However, enabling efficient and adaptable locomotion remains challenging due to the quadrupeds' nonlinear dynamics, high degrees of freedom, and the computational demands of real-time control. Optimization-based controllers, such as Nonlinear Model Predictive Control (NMPC), have shown strong performance, but their reliance on accurate state estimation and high computational overhead makes deployment in real-world settings challenging. In this work, we present a Multi-Task Learning (MTL) framework in which expert NMPC demonstrations are used to train a single neural network to predict actions for multiple locomotion behaviors directly from raw proprioceptive sensor inputs. We evaluate our approach extensively on the quadruped robot Go1, both in simulation and on real hardware, demonstrating that it accurately reproduces expert behavior, allows smooth gait switching, and simplifies the control pipeline for real-time deployment. Our MTL architecture enables learning diverse gaits within a unified policy, achieving high $R^{2}$ scores for predicted joint targets across all tasks.