Extracting Visual Plans from Unlabeled Videos via Symbolic Guidance
作者: Wenyan Yang, Ahmet Tikna, Yi Zhao, Yuying Zhang, Luigi Palopoli, Marco Roveri, Joni Pajarinen
分类: cs.RO
发布日期: 2025-05-13 (更新: 2025-08-07)
💡 一句话要点
Vis2Plan:利用符号指导从无标签视频中提取视觉规划,提升机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉规划 符号指导 机器人操作 无标签视频 视觉基础模型
📋 核心要点
- 现有视觉规划方法依赖视频生成模型,存在模型幻觉问题,且计算成本高昂,限制了其在实际机器人任务中的应用。
- Vis2Plan利用视觉基础模型提取任务符号,构建高级符号转换图,实现高效且可解释的视觉规划,避免了视频生成。
- 实验表明,Vis2Plan在真实机器人任务中成功率显著高于现有方法,同时规划速度更快,证明了其有效性和实用性。
📝 摘要(中文)
视觉规划通过为目标条件下的低级策略提供一系列中间视觉子目标,在长时程操作任务中取得了有希望的性能。为了获得这些子目标,现有方法通常依赖于视频生成模型,但受到模型幻觉和计算成本的困扰。我们提出了Vis2Plan,一个高效、可解释和白盒的视觉规划框架,由符号指导驱动。Vis2Plan从原始的、无标签的演示数据中,利用视觉基础模型自动提取一组紧凑的任务符号,从而构建一个用于多目标、多阶段规划的高级符号转换图。在测试时,给定一个期望的任务目标,我们的规划器在符号级别进行规划,并组装一个由底层符号表示所支持的、在物理上一致的中间子目标图像序列。在真实机器人环境中,Vis2Plan的总体成功率比基于扩散视频生成的强大视觉规划器高出53%,同时生成视觉规划的速度快35倍。结果表明,Vis2Plan能够生成物理上一致的图像目标,同时提供完全可检查的推理步骤。
🔬 方法详解
问题定义:现有视觉规划方法依赖于视频生成模型来生成中间子目标图像,但这些模型容易产生幻觉,生成不真实的图像,并且计算成本很高,难以应用于实际的机器人操作任务。因此,需要一种更高效、更可靠的视觉规划方法,能够生成物理上一致的子目标图像,并降低计算复杂度。
核心思路:Vis2Plan的核心思路是利用视觉基础模型从无标签的演示视频中自动提取任务相关的符号,然后基于这些符号构建一个高级的符号转换图。通过在符号级别进行规划,可以避免直接生成图像,从而降低计算成本,并提高规划的可靠性。最终,将符号规划的结果映射回图像空间,生成物理上一致的子目标图像序列。
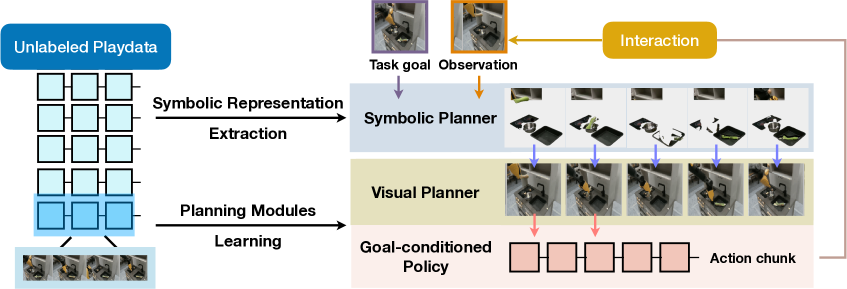
技术框架:Vis2Plan的整体框架包括以下几个主要阶段:1) 符号提取:利用视觉基础模型(例如CLIP)从无标签视频中提取图像特征,并使用聚类算法将这些特征聚类成不同的任务符号。2) 符号转换图构建:通过分析视频中的状态转移,构建一个高级的符号转换图,其中节点表示任务符号,边表示符号之间的转换关系。3) 符号规划:给定一个目标状态,使用搜索算法(例如A)在符号转换图上找到一条从初始状态到目标状态的路径。4) 图像生成*:将符号规划的结果映射回图像空间,生成一系列中间子目标图像,作为低级策略的输入。
关键创新:Vis2Plan的关键创新在于利用符号指导进行视觉规划,避免了直接生成图像,从而降低了计算成本,并提高了规划的可靠性。与现有方法相比,Vis2Plan具有以下优势:1) 高效性:符号规划比图像生成更高效。2) 可解释性:符号转换图提供了清晰的任务结构和推理过程。3) 物理一致性:通过符号约束,可以生成物理上更合理的子目标图像。
关键设计:Vis2Plan的关键设计包括:1) 使用预训练的视觉基础模型(如CLIP)提取图像特征,以提高符号提取的准确性。2) 使用聚类算法(如K-means)将图像特征聚类成不同的任务符号。3) 使用A*搜索算法在符号转换图上进行规划,以找到最优的子目标序列。4) 使用逆运动学(IK)等技术将符号规划的结果映射回图像空间,生成物理上可行的子目标图像。
🖼️ 关键图片


📊 实验亮点
Vis2Plan在真实机器人环境中进行了实验验证,结果表明,与基于扩散视频生成的视觉规划器相比,Vis2Plan的总体成功率提高了53%,同时生成视觉规划的速度快了35倍。这些结果表明,Vis2Plan能够生成物理上一致的图像目标,同时提供完全可检查的推理步骤,具有显著的性能优势。
🎯 应用场景
Vis2Plan具有广泛的应用前景,例如机器人操作、自动化装配、智能家居等领域。它可以帮助机器人更好地理解任务目标,并规划出合理的动作序列,从而实现更复杂、更智能的任务。此外,Vis2Plan的可解释性使其更容易调试和优化,有助于提高机器人系统的可靠性和安全性。未来,可以将Vis2Plan与其他技术(例如强化学习、模仿学习)相结合,进一步提升机器人的自主学习能力。
📄 摘要(原文)
Visual planning, by offering a sequence of intermediate visual subgoals to a goal-conditioned low-level policy, achieves promising performance on long-horizon manipulation tasks. To obtain the subgoals, existing methods typically resort to video generation models but suffer from model hallucination and computational cost. We present Vis2Plan, an efficient, explainable and white-box visual planning framework powered by symbolic guidance. From raw, unlabeled play data, Vis2Plan harnesses vision foundation models to automatically extract a compact set of task symbols, which allows building a high-level symbolic transition graph for multi-goal, multi-stage planning. At test time, given a desired task goal, our planner conducts planning at the symbolic level and assembles a sequence of physically consistent intermediate sub-goal images grounded by the underlying symbolic representation. Our Vis2Plan outperforms strong diffusion video generation-based visual planners by delivering 53\% higher aggregate success rate in real robot settings while generating visual plans 35$\times$ faster. The results indicate that Vis2Plan is able to generate physically consistent image goals while offering fully inspectable reasoning steps.