ORACLE-Grasp: Zero-Shot Task-Oriented Robotic Grasping using Large Multimodal Models
作者: Avihai Giuili, Rotem Atari, Avishai Sintov
分类: cs.RO
发布日期: 2025-05-13
💡 一句话要点
ORACLE-Grasp:利用大型多模态模型实现零样本任务导向的机器人抓取
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 大型多模态模型 零样本学习 任务导向 语义理解
📋 核心要点
- 现有机器人抓取方法依赖密集训练数据或显式几何建模,难以扩展到真实场景。
- ORACLE-Grasp利用大型多模态模型作为语义预言机,指导抓取选择,无需额外训练。
- 实验表明,该方法预测的抓取姿态误差小,真实场景拾取成功率高。
📝 摘要(中文)
本文提出ORACLE-Grasp,一个零样本框架,利用大型多模态模型(LMMs)作为语义预言机来指导抓取选择,无需额外训练或人工输入。该系统将抓取预测建模为一个结构化的迭代决策过程,使用双提示工具调用首先提取高层次的对象上下文,然后选择任务相关的抓取区域。通过离散化图像空间并推理候选区域,ORACLE-Grasp缓解了LMMs中常见的空间不精确性,并产生类似人类的任务驱动的抓取建议。提前停止和基于深度的细化步骤进一步提高了效率和物理抓取的可靠性。实验表明,预测的抓取相对于人工标注的真实值实现了较低的位置和方向误差,并在真实世界的拾取任务中实现了较高的成功率。这些结果突出了将语言驱动的推理与轻量级视觉技术相结合,以实现鲁棒的自主抓取的潜力,而无需特定任务的数据集或重新训练。
🔬 方法详解
问题定义:在非结构化环境中抓取未知物体是机器人领域的一个基本挑战。现有方法通常需要大量的训练数据或精确的几何模型,这限制了它们在实际任务中的可扩展性。此外,如何使机器人能够理解任务需求并选择合适的抓取姿态也是一个难题。
核心思路:ORACLE-Grasp的核心思路是利用大型多模态模型(LMMs)的强大语义理解能力,将其作为“语义预言机”,指导机器人进行抓取。通过语言提示,LMMs可以理解任务目标,并根据场景信息选择合适的抓取区域,从而实现零样本的任务导向抓取。
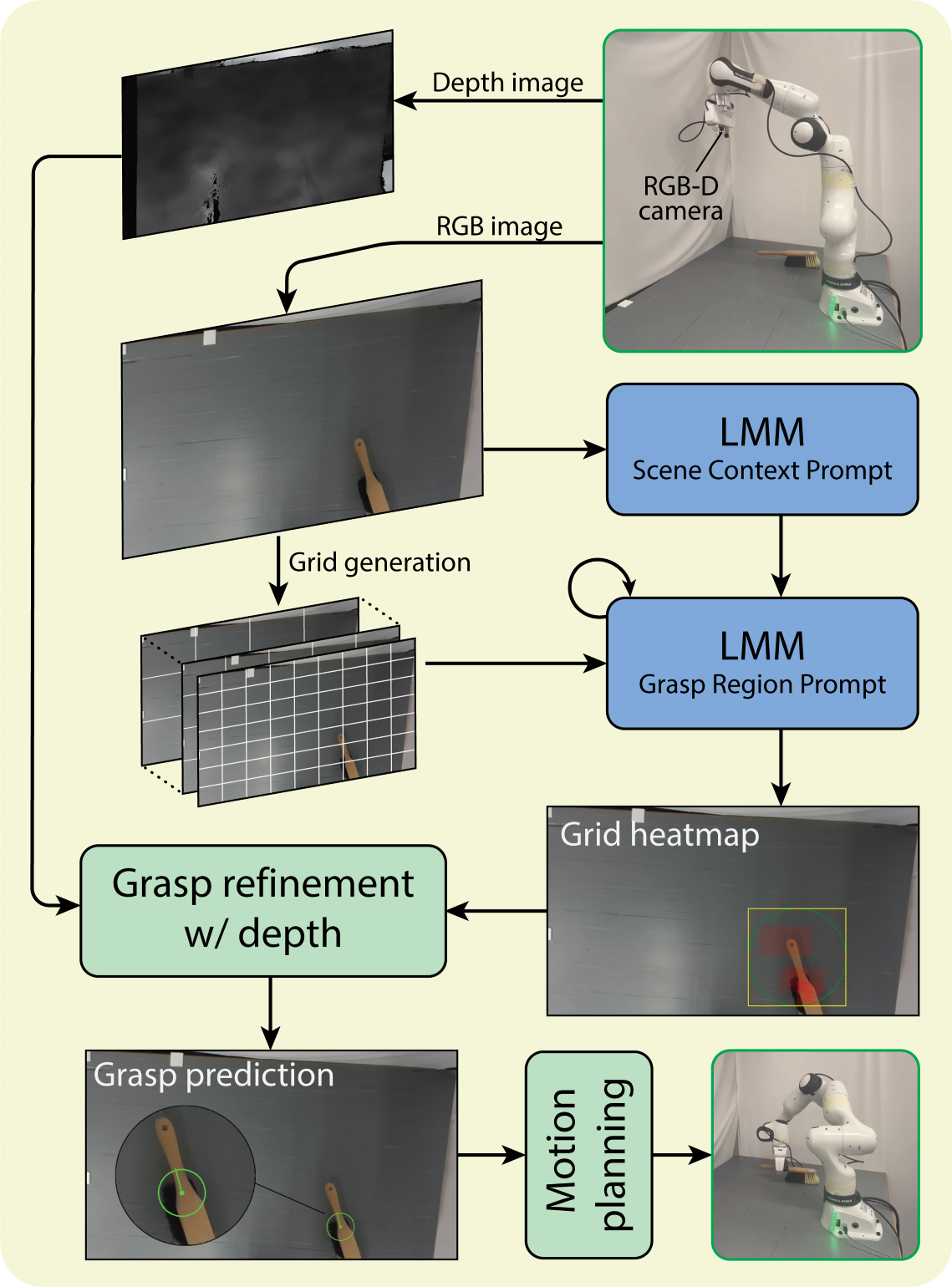
技术框架:ORACLE-Grasp系统包含以下主要模块:1) 双提示工具调用:首先使用LMMs提取高层次的对象上下文信息,然后选择任务相关的抓取区域。2) 图像空间离散化:将图像空间离散化为候选区域,以缓解LMMs的空间不精确性。3) 抓取区域推理:在候选区域上进行推理,选择最佳抓取区域。4) 提前停止机制:在达到一定迭代次数后停止搜索,提高效率。5) 基于深度的细化:利用深度信息细化抓取姿态,提高抓取可靠性。
关键创新:ORACLE-Grasp的关键创新在于将大型多模态模型应用于机器人抓取任务,并将其作为语义预言机来指导抓取选择。与传统方法相比,该方法无需额外的训练数据或人工标注,即可实现零样本的任务导向抓取。此外,通过图像空间离散化和基于深度的细化,有效缓解了LMMs的空间不精确性,提高了抓取性能。
关键设计:该方法使用双提示策略,分别提取对象上下文和抓取区域。图像空间离散化的粒度需要根据具体任务进行调整。提前停止机制的迭代次数和基于深度的细化参数也需要根据实验结果进行优化。损失函数未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ORACLE-Grasp预测的抓取姿态相对于人工标注的真实值具有较低的位置和方向误差。在真实世界的拾取任务中,该方法实现了较高的成功率,验证了其有效性和鲁棒性。具体性能数据未知,但强调了相对于人工标注的低误差和高成功率。
🎯 应用场景
ORACLE-Grasp可应用于各种需要机器人进行物体抓取的场景,例如智能仓储、自动化装配、家庭服务机器人等。该方法无需针对特定任务进行训练,具有很强的通用性和适应性,能够显著降低机器人部署成本,提高工作效率。未来,该技术有望进一步扩展到更复杂的机器人操作任务中。
📄 摘要(原文)
Grasping unknown objects in unstructured environments remains a fundamental challenge in robotics, requiring both semantic understanding and spatial reasoning. Existing methods often rely on dense training datasets or explicit geometric modeling, limiting their scalability to real-world tasks. Recent advances in Large Multimodal Models (LMMs) offer new possibilities for integrating vision and language understanding, but their application to autonomous robotic grasping remains largely unexplored. We present ORACLE-Grasp, a zero-shot framework that leverages LMMs as semantic oracles to guide grasp selection without requiring additional training or human input. The system formulates grasp prediction as a structured, iterative decision process, using dual-prompt tool calling to first extract high-level object context and then select task-relevant grasp regions. By discretizing the image space and reasoning over candidate areas, ORACLE-Grasp mitigates the spatial imprecision common in LMMs and produces human-like, task-driven grasp suggestions. Early stopping and depth-based refinement steps further enhance efficiency and physical grasp reliability. Experiments demonstrate that the predicted grasps achieve low positional and orientation errors relative to human-annotated ground truth and lead to high success rates in real-world pick up tasks. These results highlight the potential of combining language-driven reasoning with lightweight vision techniques to enable robust, autonomous grasping without task-specific datasets or retraining.