Training Strategies for Efficient Embodied Reasoning
作者: William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, Sergey Levine
分类: cs.RO
发布日期: 2025-05-13 (更新: 2025-05-17)
备注: Updated figure layout, added project page link
💡 一句话要点
提出高效具身推理训练策略,加速推理并提升机器人策略泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人推理 思维链 视觉-语言-动作模型 具身智能 表征学习
📋 核心要点
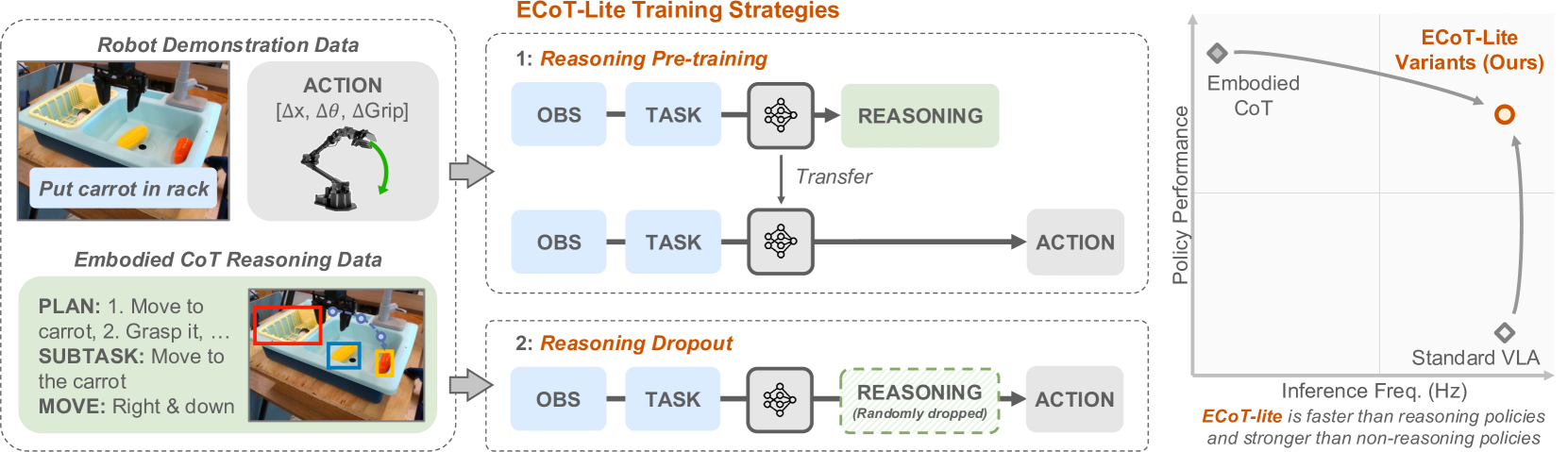
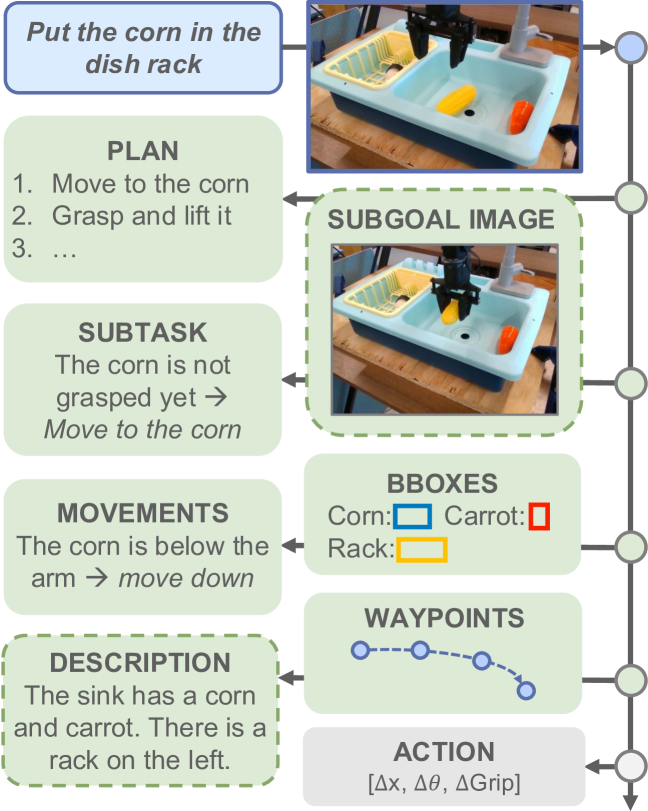
- 现有机器人思维链推理方法依赖专用数据,且推理速度慢,限制了其应用。
- 论文通过分析推理的机制,提出了两种轻量级的机器人推理替代方案。
- 实验表明,新方法在LIBERO-90基准上取得SOTA结果,并加速了推理过程。
📝 摘要(中文)
机器人思维链(CoT)推理,即模型在选择动作前预测有用的中间表示,为提高机器人策略(特别是视觉-语言-动作模型,VLAs)的泛化性和性能提供了一种有效方法。虽然这种方法已被证明可以提高性能和泛化性,但它们存在核心限制,例如需要专门的机器人推理数据和缓慢的推理速度。为了设计解决这些问题的新型机器人推理方法,全面了解推理为何有助于策略性能至关重要。我们假设机器人推理通过以下几种机制改进策略:(1)更好的表征学习,(2)改进的学习课程,以及(3)增加的表达能力。然后,我们设计了机器人CoT推理的简单变体,以分离和测试每一个机制。我们发现,学习生成推理确实可以带来更好的VLA表征,而关注推理有助于实际利用这些特征来改进动作预测。我们的结果让我们更好地理解了CoT推理为何能够帮助VLA,并用它来介绍两种简单而轻量级的机器人推理替代方案。我们提出的方法在LIBERO-90基准测试中实现了优于非推理策略的显著性能提升和最先进的结果,并且推理速度比标准机器人推理快3倍。
🔬 方法详解
问题定义:现有机器人思维链(CoT)推理方法虽然能提升视觉-语言-动作模型(VLA)的性能和泛化能力,但存在两个主要痛点:一是需要大量的、专门设计的机器人推理数据进行训练,数据获取成本高昂;二是推理速度较慢,难以满足实时性要求较高的应用场景。因此,如何设计一种既能保持推理带来的性能提升,又能降低数据依赖和加速推理过程的机器人推理方法是本文要解决的核心问题。
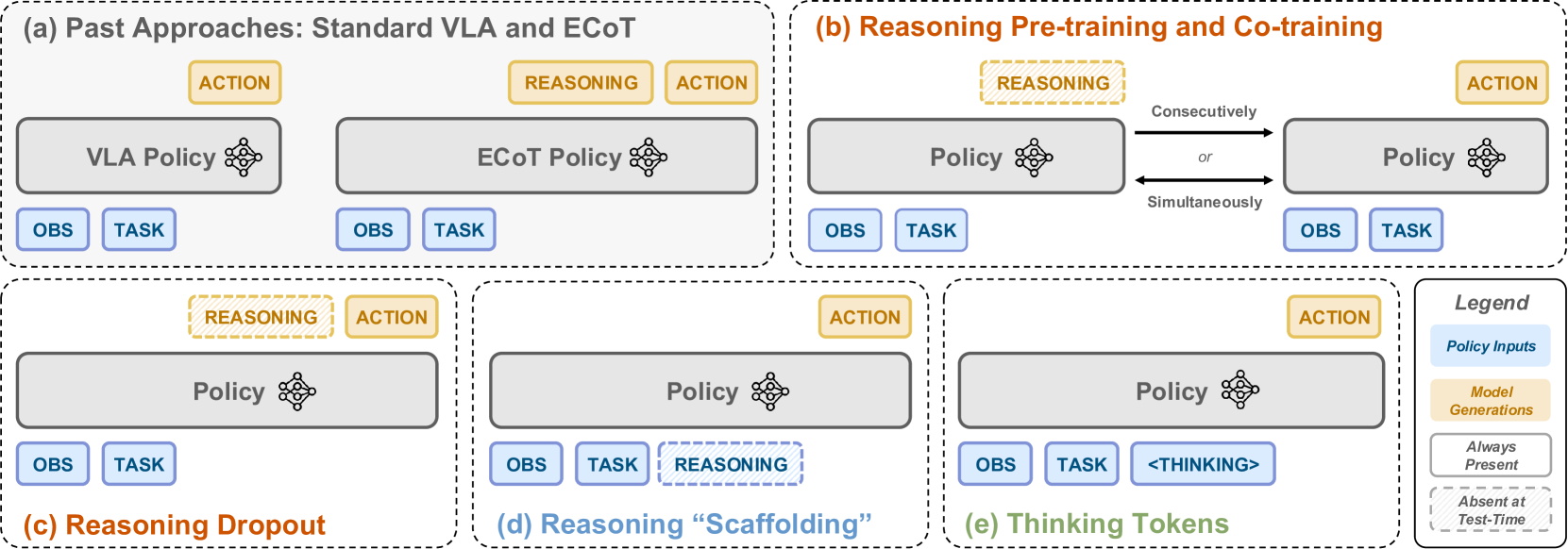
核心思路:论文的核心思路是通过深入分析机器人CoT推理提升策略性能的内在机制,包括更好的表征学习、改进的学习课程和增加的表达能力,然后基于这些理解设计更高效的推理方法。具体而言,论文通过实验验证了学习生成推理确实能带来更好的VLA表征,而关注推理有助于实际利用这些特征来改进动作预测。基于此,论文提出了两种轻量级的机器人推理替代方案,旨在在不牺牲性能的前提下,降低数据需求和加速推理过程。
技术框架:论文的技术框架主要包括以下几个阶段:首先,对机器人CoT推理的内在机制进行假设,包括更好的表征学习、改进的学习课程和增加的表达能力。其次,设计机器人CoT推理的简单变体,以分离和测试每一个机制,验证假设的正确性。然后,基于对推理机制的理解,提出两种轻量级的机器人推理替代方案。最后,在LIBERO-90基准测试中评估新方法的性能,并与现有方法进行比较。
关键创新:论文最重要的技术创新点在于对机器人CoT推理内在机制的深入分析和理解,并基于此提出了两种轻量级的机器人推理替代方案。与现有方法相比,这些新方法在保持甚至提升性能的同时,显著降低了对专门设计数据的依赖,并实现了更快的推理速度。这使得机器人推理更易于应用到实际场景中。
关键设计:论文的关键设计包括:(1) 设计实验来分离和测试机器人CoT推理的各个机制,例如通过不同的训练策略来考察表征学习的效果;(2) 提出两种轻量级的机器人推理替代方案,具体的技术细节未知,但强调了在不牺牲性能的前提下,降低数据需求和加速推理过程;(3) 在LIBERO-90基准测试中进行全面的实验评估,并与现有方法进行比较,以验证新方法的有效性。
🖼️ 关键图片
📊 实验亮点
论文提出的两种轻量级机器人推理方法在LIBERO-90基准测试中取得了显著的性能提升,超越了现有的非推理策略,并达到了最先进水平。更重要的是,新方法实现了3倍的推理速度提升,使其更适用于实时性要求高的应用场景。这些实验结果充分验证了论文提出的方法在效率和性能上的优势。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、智能家居等领域。通过提升机器人的推理能力和决策效率,可以使其更好地理解环境、执行复杂任务,并与人类进行更自然的交互。未来,该研究有望推动机器人技术在工业自动化、医疗健康、服务业等领域的广泛应用。
📄 摘要(原文)
Robot chain-of-thought reasoning (CoT) -- wherein a model predicts helpful intermediate representations before choosing actions -- provides an effective method for improving the generalization and performance of robot policies, especially vision-language-action models (VLAs). While such approaches have been shown to improve performance and generalization, they suffer from core limitations, like needing specialized robot reasoning data and slow inference speeds. To design new robot reasoning approaches that address these issues, a more complete characterization of why reasoning helps policy performance is critical. We hypothesize several mechanisms by which robot reasoning improves policies -- (1) better representation learning, (2) improved learning curricularization, and (3) increased expressivity -- then devise simple variants of robot CoT reasoning to isolate and test each one. We find that learning to generate reasonings does lead to better VLA representations, while attending to the reasonings aids in actually leveraging these features for improved action prediction. Our results provide us with a better understanding of why CoT reasoning helps VLAs, which we use to introduce two simple and lightweight alternative recipes for robot reasoning. Our proposed approaches achieve significant performance gains over non-reasoning policies, state-of-the-art results on the LIBERO-90 benchmark, and a 3x inference speedup compared to standard robot reasoning.