Scaling Multi Agent Reinforcement Learning for Underwater Acoustic Tracking via Autonomous Vehicles
作者: Matteo Gallici, Ivan Masmitja, Mario Martín
分类: cs.RO, cs.AI, cs.DC, cs.PF
发布日期: 2025-05-13 (更新: 2025-10-17)
💡 一句话要点
提出基于蒸馏和Transformer的多智能体强化学习方法,用于水下声学跟踪。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 水下声学跟踪 自主水下航行器 蒸馏训练 Transformer 课程学习
📋 核心要点
- 多智能体强化学习在水下跟踪中面临计算挑战,高保真模拟器无法有效加速多智能体场景。
- 提出迭代蒸馏方法,将高保真模拟知识迁移到GPU加速的简化环境,实现高效训练。
- 引入Transformer架构TransfMAPPO,学习对智能体和目标数量不变的策略,提高样本效率,并在Gazebo中验证了有效性。
📝 摘要(中文)
自主水下航行器(AV)为水下跟踪等科学任务提供了一种经济高效的解决方案。近年来,强化学习(RL)已成为控制复杂海洋环境中AV的强大方法。然而,将这些技术扩展到多智能体系统——对于多目标跟踪或快速、不可预测运动的目标至关重要——带来了巨大的计算挑战。多智能体强化学习(MARL)的样本效率非常低。虽然像Gazebo的LRAUV这样的高保真模拟器提供比实时快100倍的单机器人模拟,但它们不能显著加速多车辆场景,使得MARL训练不切实际。为了解决这些限制,我们提出了一种迭代蒸馏方法,将高保真模拟转移到简化的、GPU加速的环境中,同时保留高层动态。这种方法通过并行化实现了高达30,000倍于Gazebo的加速,从而可以通过端到端GPU加速进行高效训练。此外,我们引入了一种新颖的基于Transformer的架构(TransfMAPPO),该架构学习对智能体和目标数量不变的多智能体策略,显著提高了样本效率。在完全在GPU上进行的大规模课程学习之后,我们在Gazebo中进行了广泛的评估,表明即使在存在多个快速移动目标的情况下,我们的方法也能在较长时间内将跟踪误差保持在5米以下。这项工作弥合了大规模MARL训练和高保真部署之间的差距,为实际海洋任务中的自主舰队控制提供了一个可扩展的框架。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习(MARL)在水下声学跟踪应用中,由于计算复杂度高和样本效率低而难以扩展的问题。现有的高保真水下环境模拟器,如Gazebo的LRAUV,虽然能加速单智能体仿真,但在多智能体场景下加速效果不明显,导致MARL训练时间过长,难以实际应用。
核心思路:论文的核心思路是通过迭代蒸馏,将高保真模拟器中的知识迁移到简化的、GPU加速的环境中,从而大幅提高训练速度。同时,设计一种对智能体和目标数量不变的策略网络,以提高样本效率和泛化能力。通过这种方式,可以在可承受的计算资源下训练出适用于复杂水下环境的多智能体控制策略。
技术框架:整体框架包含以下几个主要阶段:1) 在高保真模拟器(Gazebo/LRAUV)中生成训练数据;2) 使用迭代蒸馏方法,将高保真数据迁移到简化的GPU加速环境;3) 在GPU加速环境中,使用TransfMAPPO算法进行MARL训练;4) 在高保真模拟器中进行策略验证和评估。TransfMAPPO算法是基于MAPPO (Multi-Agent Proximal Policy Optimization) 的改进,使用了Transformer架构来处理多智能体之间的交互信息。
关键创新:论文的关键创新点在于:1) 提出了迭代蒸馏方法,有效解决了高保真模拟器计算量大的问题,实现了训练速度的大幅提升;2) 设计了基于Transformer的TransfMAPPO算法,该算法能够学习对智能体和目标数量不变的策略,提高了样本效率和泛化能力。
关键设计:TransfMAPPO算法使用Transformer编码器来处理每个智能体的观测信息,并使用注意力机制来建模智能体之间的交互。损失函数包括策略梯度损失、值函数损失和熵正则化项。课程学习策略用于逐步增加训练难度,例如增加目标数量和速度。具体参数设置未知。
🖼️ 关键图片

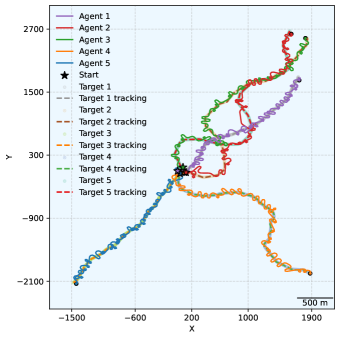
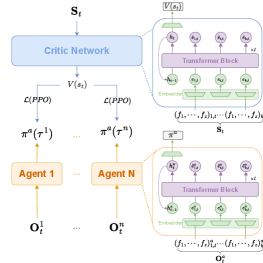
📊 实验亮点
实验结果表明,所提出的方法在GPU加速环境下实现了高达30,000倍于Gazebo的训练速度提升。在Gazebo高保真模拟环境中,即使在存在多个快速移动目标的情况下,该方法也能将跟踪误差保持在5米以下,证明了其有效性和鲁棒性。TransfMAPPO算法相比于其他基线算法,在样本效率和泛化能力方面均有显著提升。
🎯 应用场景
该研究成果可应用于水下环境监测、水下搜救、水下资源勘探等领域。通过自主水下航行器集群,可以更高效、更安全地完成这些任务。该方法为大规模多智能体系统在复杂环境中的应用提供了新的思路,具有重要的实际价值和潜在的未来影响。
📄 摘要(原文)
Autonomous vehicles (AV) offer a cost-effective solution for scientific missions such as underwater tracking. Recently, reinforcement learning (RL) has emerged as a powerful method for controlling AVs in complex marine environments. However, scaling these techniques to a fleet--essential for multi-target tracking or targets with rapid, unpredictable motion--presents significant computational challenges. Multi-Agent Reinforcement Learning (MARL) is notoriously sample-inefficient, and while high-fidelity simulators like Gazebo's LRAUV provide 100x faster-than-real-time single-robot simulations, they offer no significant speedup for multi-vehicle scenarios, making MARL training impractical. To address these limitations, we propose an iterative distillation method that transfers high-fidelity simulations into a simplified, GPU-accelerated environment while preserving high-level dynamics. This approach achieves up to a 30,000x speedup over Gazebo through parallelization, enabling efficient training via end-to-end GPU acceleration. Additionally, we introduce a novel Transformer-based architecture (TransfMAPPO) that learns multi-agent policies invariant to the number of agents and targets, significantly improving sample efficiency. Following large-scale curriculum learning conducted entirely on GPU, we perform extensive evaluations in Gazebo, demonstrating that our method maintains tracking errors below 5 meters over extended durations, even in the presence of multiple fast-moving targets. This work bridges the gap between large-scale MARL training and high-fidelity deployment, providing a scalable framework for autonomous fleet control in real-world sea missions.