Guiding Data Collection via Factored Scaling Curves
作者: Lihan Zha, Apurva Badithela, Michael Zhang, Justin Lidard, Jeremy Bao, Emily Zhou, David Snyder, Allen Z. Ren, Dhruv Shah, Anirudha Majumdar
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-12
备注: Project website: https://factored-data-scaling.github.io
💡 一句话要点
提出基于分解缩放曲线的数据收集方法,提升通用模仿学习策略在操作任务中的泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 数据收集 分解缩放曲线 机器人操作 泛化能力
📋 核心要点
- 通用模仿学习策略需要大量数据,但环境因素的多样性使得数据收集成本高昂,难以覆盖所有情况。
- 论文提出分解缩放曲线(FSC),通过分析数据量与性能的关系,指导针对性地收集对性能提升最关键的数据。
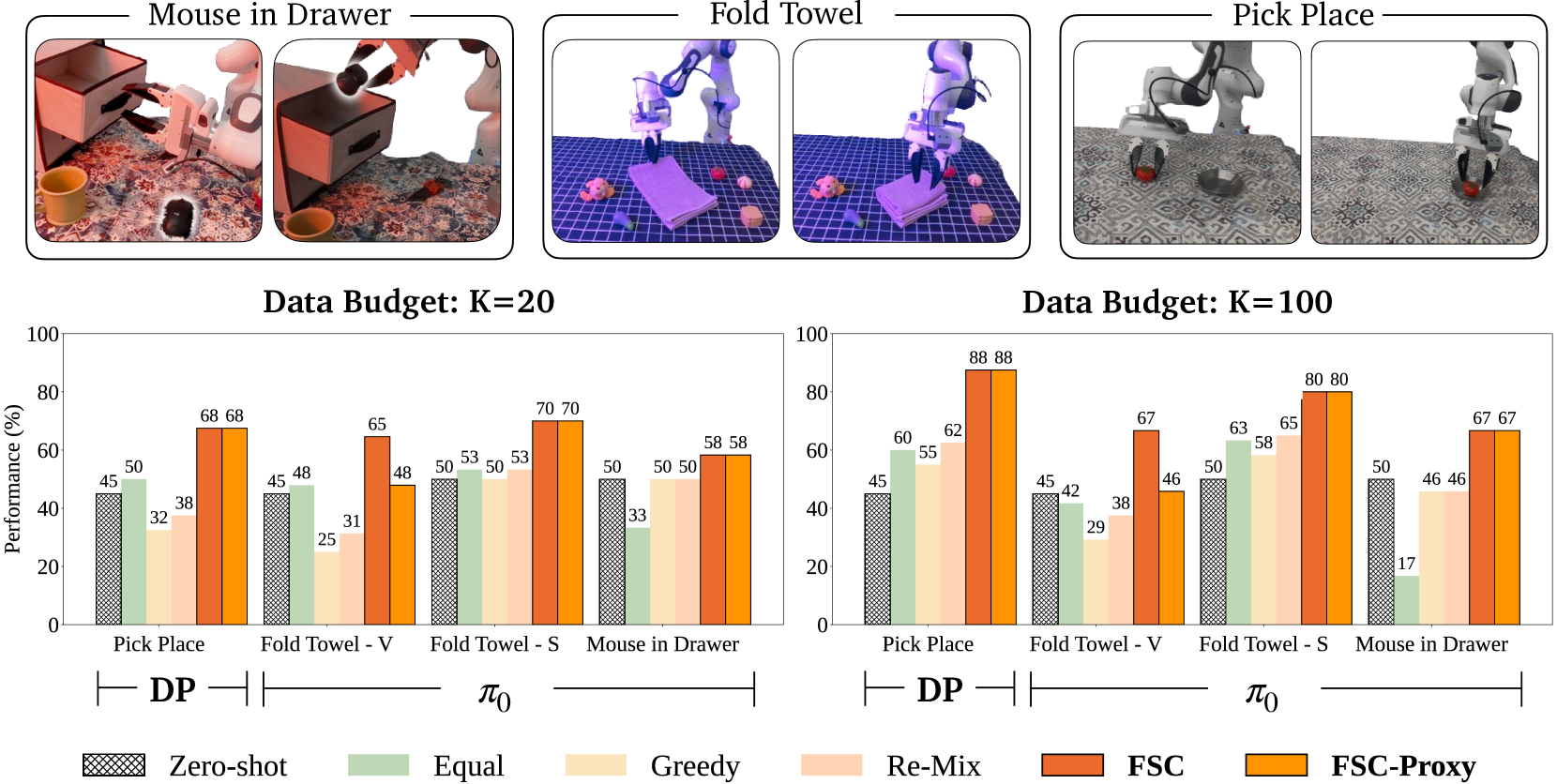
- 实验表明,该方法在真实世界任务中,相比现有数据收集策略,成功率提升高达26%,并能通过离线指标指导数据收集。
📝 摘要(中文)
本文提出了一种系统性的数据收集方法,通过构建分解缩放曲线(FSC)来决定为每个环境因素变体(例如相机姿态、桌面高度、干扰物)收集哪些数据以及收集多少数据。FSC量化了策略性能如何随着数据在单个或成对因素上的缩放而变化。这使得能够在给定预算内,针对最具影响力的因素组合进行有针对性的数据采集。通过广泛的模拟和真实世界实验,包括从头开始训练和微调设置,验证了该方法的有效性。结果表明,与现有数据收集策略相比,该方法在新的真实世界环境中,成功率提高了高达26%。此外,还展示了分解缩放曲线如何使用离线指标有效地指导数据收集,而无需大规模的真实世界评估。
🔬 方法详解
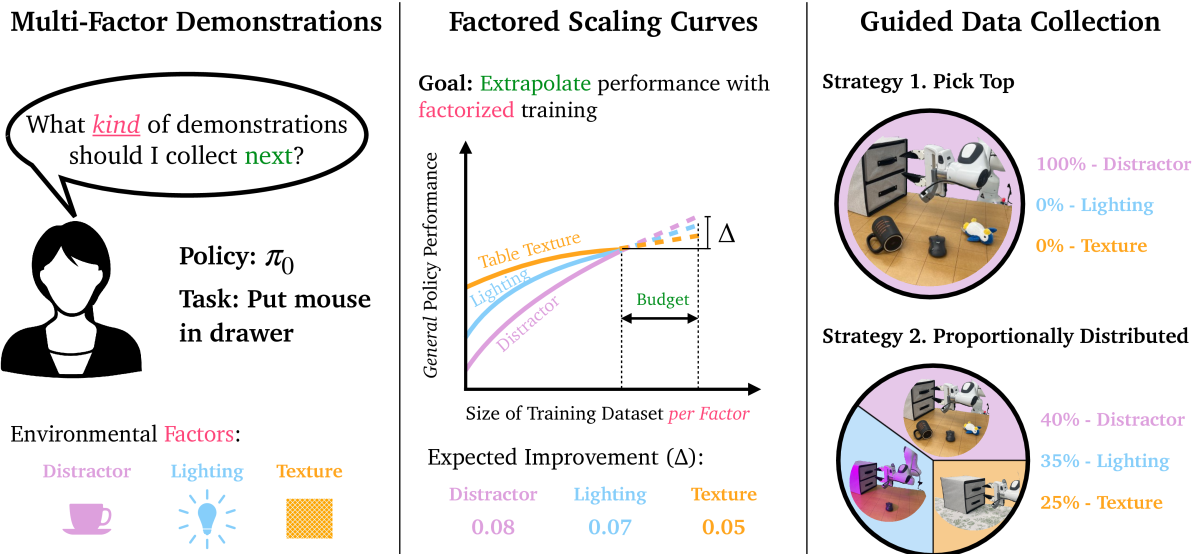
问题定义:通用模仿学习策略在复杂操作任务中面临泛化性挑战,主要原因是环境因素(如相机视角、物体位置等)的多样性。现有数据收集方法通常是随机采样或穷举所有因素组合,效率低下且成本高昂,难以保证策略在未见环境中的表现。因此,需要一种更智能的数据收集策略,能够识别并优先收集对策略性能提升最关键的数据。
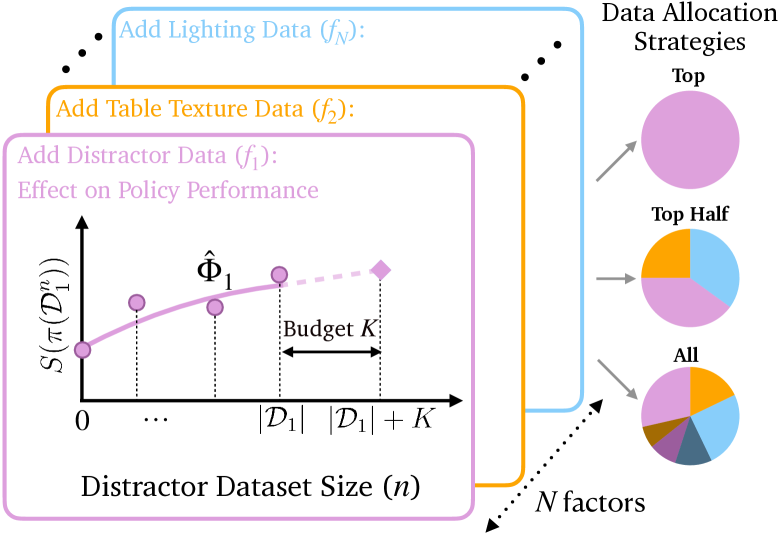
核心思路:论文的核心思路是构建“分解缩放曲线”(Factored Scaling Curves, FSC),将策略性能与不同环境因素的数据量关联起来。通过分析这些曲线,可以确定哪些因素对性能影响最大,从而指导数据收集,优先收集这些关键因素的数据。这种方法避免了盲目地收集所有因素组合的数据,提高了数据收集的效率和针对性。
技术框架:该方法包含以下主要阶段:1) 初始数据收集:首先,使用少量数据进行初步训练,得到一个初始策略。2) FSC构建:针对每个或每对环境因素,逐步增加该因素的数据量,并评估策略性能,从而构建FSC。3) 数据收集策略优化:基于FSC,确定对性能提升最显著的因素组合,并制定数据收集策略,优先收集这些因素组合的数据。4) 策略训练与评估:使用收集到的数据训练策略,并在新的环境中进行评估,验证数据收集策略的有效性。
关键创新:该方法最重要的创新点在于提出了分解缩放曲线(FSC)的概念,并将其应用于指导数据收集。与传统的随机采样或穷举方法相比,FSC能够更准确地量化不同因素对策略性能的影响,从而实现更高效、更有针对性的数据收集。此外,该方法还提出了一种基于离线指标来指导数据收集的策略,避免了大规模的真实世界评估。
关键设计:FSC的构建需要选择合适的性能评估指标,例如成功率、任务完成时间等。数据收集策略的优化可以采用多种方法,例如基于梯度的方法或基于启发式规则的方法。论文中使用了特定的损失函数和网络结构(具体细节未知),以支持模仿学习策略的训练。此外,如何选择合适的因素组合进行分析,以及如何平衡不同因素的数据量,也是关键的设计考虑因素。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在真实世界任务中,相比现有数据收集策略,成功率提升高达26%。在模拟环境中,该方法也表现出显著的性能提升。此外,该方法还展示了使用离线指标指导数据收集的能力,避免了大规模的真实世界评估,进一步降低了数据收集成本。这些结果充分验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、游戏AI等领域。通过智能地指导数据收集,可以显著降低训练成本,提高策略的泛化能力和鲁棒性。尤其是在资源有限的情况下,该方法能够帮助研究人员更有效地利用数据,开发出更强大的AI系统。未来,该方法有望应用于更复杂的任务和环境,推动人工智能技术的进一步发展。
📄 摘要(原文)
Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.