Beyond Static Perception: Integrating Temporal Context into VLMs for Cloth Folding
作者: Oriol Barbany, Adrià Colomé, Carme Torras
分类: cs.RO, cs.CV
发布日期: 2025-05-12
备注: Accepted at ICRA 2025 Workshop "Reflections on Representations and Manipulating Deformable Objects". Project page https://barbany.github.io/bifold/
💡 一句话要点
BiFold:融合时序上下文的视觉语言模型用于服装折叠
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 服装折叠 视觉语言模型 时序上下文 机器人操作 端到端学习
📋 核心要点
- 服装折叠任务因其高自由度和自遮挡特性,难以进行精确的状态估计,是机器人操作中的一个挑战性问题。
- BiFold模型通过端到端学习,隐式地编码服装状态,并利用时序上下文信息来提升对复杂状态的理解和处理能力。
- 实验结果表明,BiFold模型通过微调和时序上下文学习,能够有效对齐文本和图像区域,并保证时序一致性。
📝 摘要(中文)
由于衣物复杂的动力学特性、高度的形变能力以及频繁的自遮挡,衣物操作极具挑战性。服装呈现出几乎无限数量的配置,使得显式状态表示难以定义。本文分析了BiFold,一个从视觉观察中预测语言条件下的抓取和放置动作的模型,同时通过端到端学习隐式地编码服装状态。为了解决诸如褶皱衣物或从失败操作中恢复等场景,BiFold利用时间上下文来改进状态估计。我们检查了模型的内部表示,并提供了证据表明,其微调和时间上下文能够有效地对齐文本和图像区域,并实现时间一致性。
🔬 方法详解
问题定义:服装折叠任务的核心难点在于服装的高度可变形和频繁的自遮挡,导致难以建立精确的显式状态表示。现有方法在处理褶皱或操作失败后的恢复等复杂场景时,往往表现不佳,缺乏鲁棒性。
核心思路:BiFold的核心思路是利用视觉语言模型(VLM)的强大表征能力,通过端到端学习隐式地编码服装状态。此外,引入时序上下文信息,使模型能够理解服装状态随时间的变化,从而更好地处理复杂场景。这样设计的原因在于,时序信息可以帮助模型从连续的观察中推断出更准确的状态,提高操作的鲁棒性。
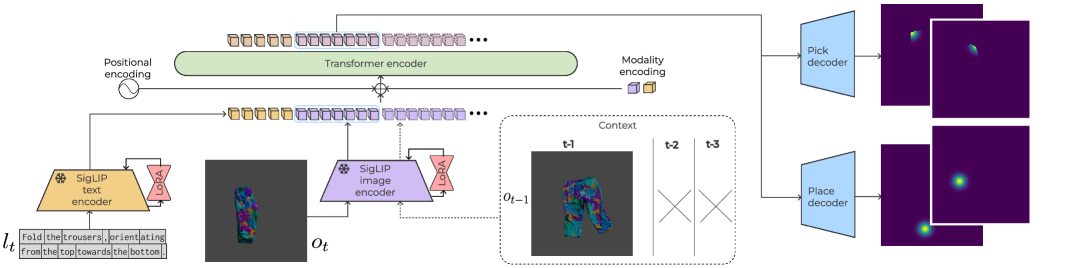
技术框架:BiFold模型接收视觉观察和语言指令作为输入,输出抓取和放置动作。其整体架构包含视觉编码器、语言编码器和一个策略网络。视觉编码器负责提取图像特征,语言编码器负责提取文本特征,策略网络则根据融合后的视觉和语言特征,预测下一步的动作。模型采用端到端的方式进行训练,直接优化动作预测的准确性。
关键创新:BiFold的关键创新在于将时序上下文信息融入到视觉语言模型中,用于服装折叠任务。传统方法通常只关注单帧图像,而忽略了服装状态随时间的变化。BiFold通过引入时序信息,能够更好地理解服装的动态特性,从而提高操作的成功率。
关键设计:BiFold的具体实现细节未知,摘要中没有明确说明视觉编码器、语言编码器和策略网络的具体结构。但是,可以推断,模型可能使用了循环神经网络(RNN)或Transformer等结构来处理时序信息。损失函数可能包括动作预测的交叉熵损失和用于鼓励时序一致性的正则化项。具体的参数设置和网络结构未知。
🖼️ 关键图片


📊 实验亮点
论文重点在于模型设计和概念验证,摘要中没有提供具体的实验数据或与其他基线的比较。亮点在于提出了将时序上下文融入视觉语言模型用于服装折叠这一思路,并验证了其可行性。通过分析模型的内部表示,作者发现微调和时序上下文能够有效对齐文本和图像区域,并实现时序一致性,这为进一步优化模型提供了指导。
🎯 应用场景
该研究成果可应用于自动化服装整理、家政服务机器人、以及服装制造等领域。通过提升机器人对服装状态的理解和操作能力,可以实现更高效、更智能的服装处理流程,从而降低人工成本,提高生产效率。未来,该技术有望扩展到其他柔性物体的操作任务中。
📄 摘要(原文)
Manipulating clothes is challenging due to their complex dynamics, high deformability, and frequent self-occlusions. Garments exhibit a nearly infinite number of configurations, making explicit state representations difficult to define. In this paper, we analyze BiFold, a model that predicts language-conditioned pick-and-place actions from visual observations, while implicitly encoding garment state through end-to-end learning. To address scenarios such as crumpled garments or recovery from failed manipulations, BiFold leverages temporal context to improve state estimation. We examine the internal representations of the model and present evidence that its fine-tuning and temporal context enable effective alignment between text and image regions, as well as temporal consistency.