GelFusion: Enhancing Robotic Manipulation under Visual Constraints via Visuotactile Fusion
作者: Shulong Jiang, Shiqi Zhao, Yuxuan Fan, Peng Yin
分类: cs.RO
发布日期: 2025-05-12
💡 一句话要点
GelFusion:通过视觉触觉融合增强视觉约束下的机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉触觉融合 机器人操作 模仿学习 交叉注意力 GelSight传感器
📋 核心要点
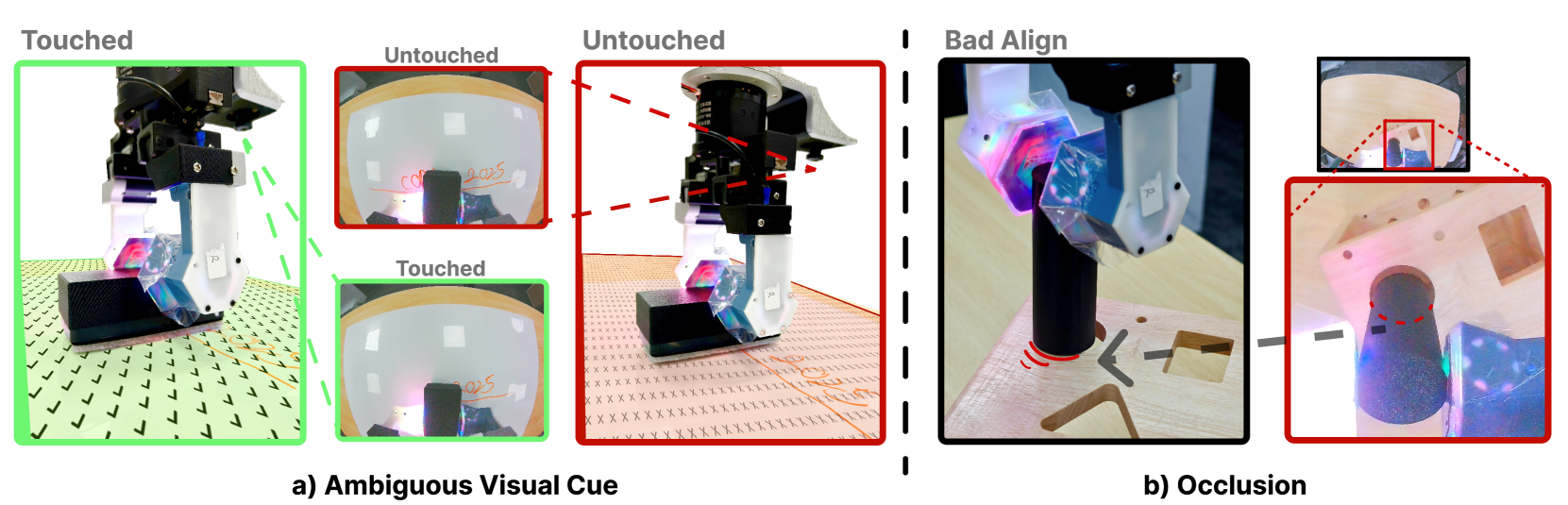
- 在视觉受限或遮挡情况下,机器人操作面临挑战,现有方法难以有效利用触觉信息。
- GelFusion框架通过视觉主导的交叉注意力融合机制,整合高分辨率GelSight传感器的视觉触觉反馈,增强策略学习。
- 实验表明,GelFusion在表面擦拭、插销和易碎物品拾取放置等任务中,显著优于基线方法,验证了其有效性。
📝 摘要(中文)
视觉触觉传感提供丰富的接触信息,有助于缓解模仿学习中的性能瓶颈,尤其是在视觉受限的条件下,例如模糊的视觉线索或遮挡。然而,有效地融合视觉和视觉触觉模态仍然面临挑战。我们提出了GelFusion,一个旨在通过整合视觉触觉反馈(特别是来自高分辨率GelSight传感器)来增强策略的框架。GelFusion使用以视觉为主的交叉注意力融合机制,将视觉触觉信息融入策略学习中。为了更好地提供丰富的接触信息,该框架的核心组件是我们的双通道视觉触觉特征表示,同时利用纹理几何特征和动态交互特征。我们在三个接触丰富的任务上评估了GelFusion:表面擦拭、插销和易碎物品的拾取放置。GelFusion优于基线方法,表明其结构在提高策略学习成功率方面的价值。
🔬 方法详解
问题定义:论文旨在解决视觉受限环境下机器人操作的难题。现有方法在处理模糊视觉线索或遮挡时,难以充分利用触觉信息来提升操作的鲁棒性和成功率。因此,如何有效地融合视觉和触觉信息,成为一个关键问题。
核心思路:GelFusion的核心思路是设计一个以视觉为主导的交叉注意力融合机制,将高分辨率GelSight传感器提供的视觉触觉信息融入到策略学习中。这种方法侧重于利用视觉信息引导触觉信息的整合,从而在视觉信息不足时,触觉信息能够有效地补充和增强策略的学习。
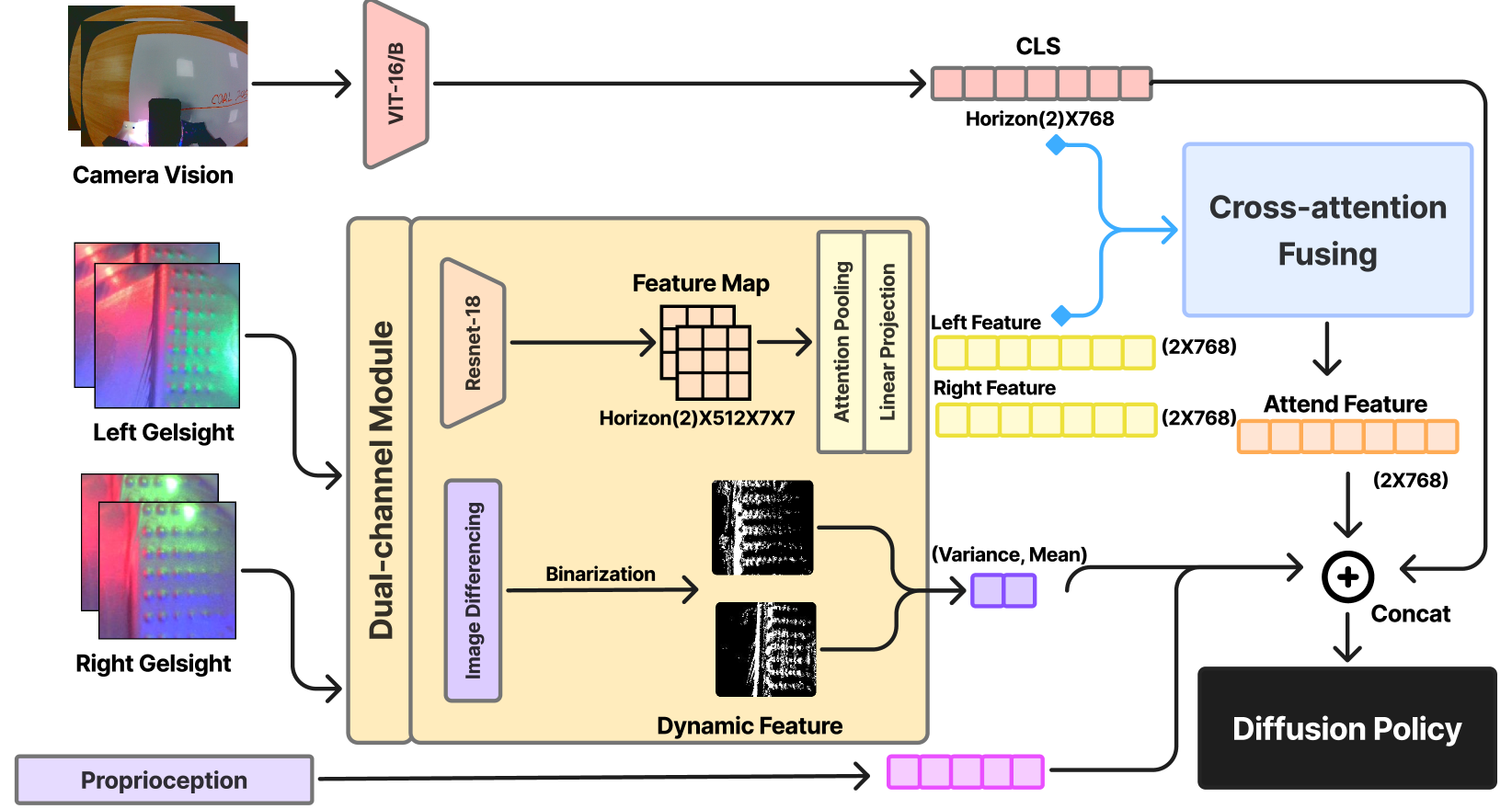
技术框架:GelFusion框架包含以下主要模块:1) 双通道视觉触觉特征提取模块,分别提取纹理几何特征和动态交互特征;2) 视觉主导的交叉注意力融合模块,利用视觉特征引导触觉特征的融合;3) 策略学习模块,基于融合后的特征学习机器人操作策略。整体流程是,首先通过视觉和触觉传感器获取数据,然后提取特征,进行融合,最后训练策略。
关键创新:GelFusion的关键创新在于其双通道视觉触觉特征表示和视觉主导的交叉注意力融合机制。双通道特征表示能够同时捕捉纹理几何和动态交互信息,更全面地描述接触状态。视觉主导的交叉注意力融合机制能够有效地将视觉和触觉信息结合起来,避免了简单拼接或加权平均等方法的不足。
关键设计:在双通道特征提取方面,论文可能采用了卷积神经网络(CNN)等深度学习模型来自动提取特征。在交叉注意力融合方面,可能使用了Transformer中的注意力机制,并对注意力权重进行了视觉主导的调整。具体的损失函数和网络结构等细节在论文中会有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
GelFusion在表面擦拭、插销和易碎物品拾取放置三个任务中均取得了显著的性能提升。实验结果表明,GelFusion的成功率明显高于基线方法,验证了其在视觉受限环境下有效融合视觉和触觉信息的能力。具体的性能数据和提升幅度需要在论文中查找(未知)。
🎯 应用场景
GelFusion技术可应用于各种需要精细操作和对环境感知要求高的机器人应用场景,例如:医疗手术机器人、精密装配机器人、以及在复杂或危险环境中执行任务的机器人。通过提升机器人对环境的感知能力和操作精度,该技术有望提高生产效率、降低操作风险,并拓展机器人的应用范围。
📄 摘要(原文)
Visuotactile sensing offers rich contact information that can help mitigate performance bottlenecks in imitation learning, particularly under vision-limited conditions, such as ambiguous visual cues or occlusions. Effectively fusing visual and visuotactile modalities, however, presents ongoing challenges. We introduce GelFusion, a framework designed to enhance policies by integrating visuotactile feedback, specifically from high-resolution GelSight sensors. GelFusion using a vision-dominated cross-attention fusion mechanism incorporates visuotactile information into policy learning. To better provide rich contact information, the framework's core component is our dual-channel visuotactile feature representation, simultaneously leveraging both texture-geometric and dynamic interaction features. We evaluated GelFusion on three contact-rich tasks: surface wiping, peg insertion, and fragile object pick-and-place. Outperforming baselines, GelFusion shows the value of its structure in improving the success rate of policy learning.