X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real
作者: Prithwish Dan, Kushal Kedia, Angela Chao, Edward Weiyi Duan, Maximus Adrian Pace, Wei-Chiu Ma, Sanjiban Choudhury
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-11 (更新: 2025-11-09)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
X-Sim:利用真实-模拟-真实迁移学习,实现跨具身机器人操作策略学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 跨具身学习 真实-模拟-真实 强化学习 领域自适应 物体运动 机器人操作 扩散模型
📋 核心要点
- 现有跨具身方法在人类动作到机器人动作的映射中,当具身差异显著时表现不佳,面临挑战。
- X-Sim利用物体运动作为密集可迁移信号,通过真实-模拟-真实框架学习机器人策略,无需机器人遥操作数据。
- 实验表明,X-Sim在任务进度上优于现有方法,数据需求更低,并能泛化到新的视角和环境变化。
📝 摘要(中文)
本文提出X-Sim,一个真实-模拟-真实框架,利用物体运动作为密集且可迁移的信号来学习机器人策略。X-Sim首先从RGBD人类视频重建逼真的模拟环境,并跟踪物体轨迹以定义以物体为中心的奖励。然后,使用这些奖励在模拟环境中训练强化学习(RL)策略。将学习到的策略通过合成数据(改变视角和光照)提炼成图像条件扩散策略。为了迁移到真实世界,X-Sim引入了一种在线领域自适应技术,在部署期间对齐真实和模拟观测。重要的是,X-Sim不需要任何机器人遥操作数据。在两个环境中的5个操作任务中评估了该方法,结果表明:(1)与手部跟踪和模拟到真实基线相比,任务进度平均提高了30%;(2)匹配了行为克隆,但数据收集时间减少了10倍;(3)推广到新的相机视角和测试时的变化。
🔬 方法详解
问题定义:现有跨具身模仿学习方法在将人类动作迁移到机器人动作时,当人类和机器人的形态差异较大时,性能会显著下降。这些方法通常依赖于直接映射人类的关节运动到机器人的关节运动,忽略了物体层面的交互信息,并且需要大量的机器人遥操作数据。
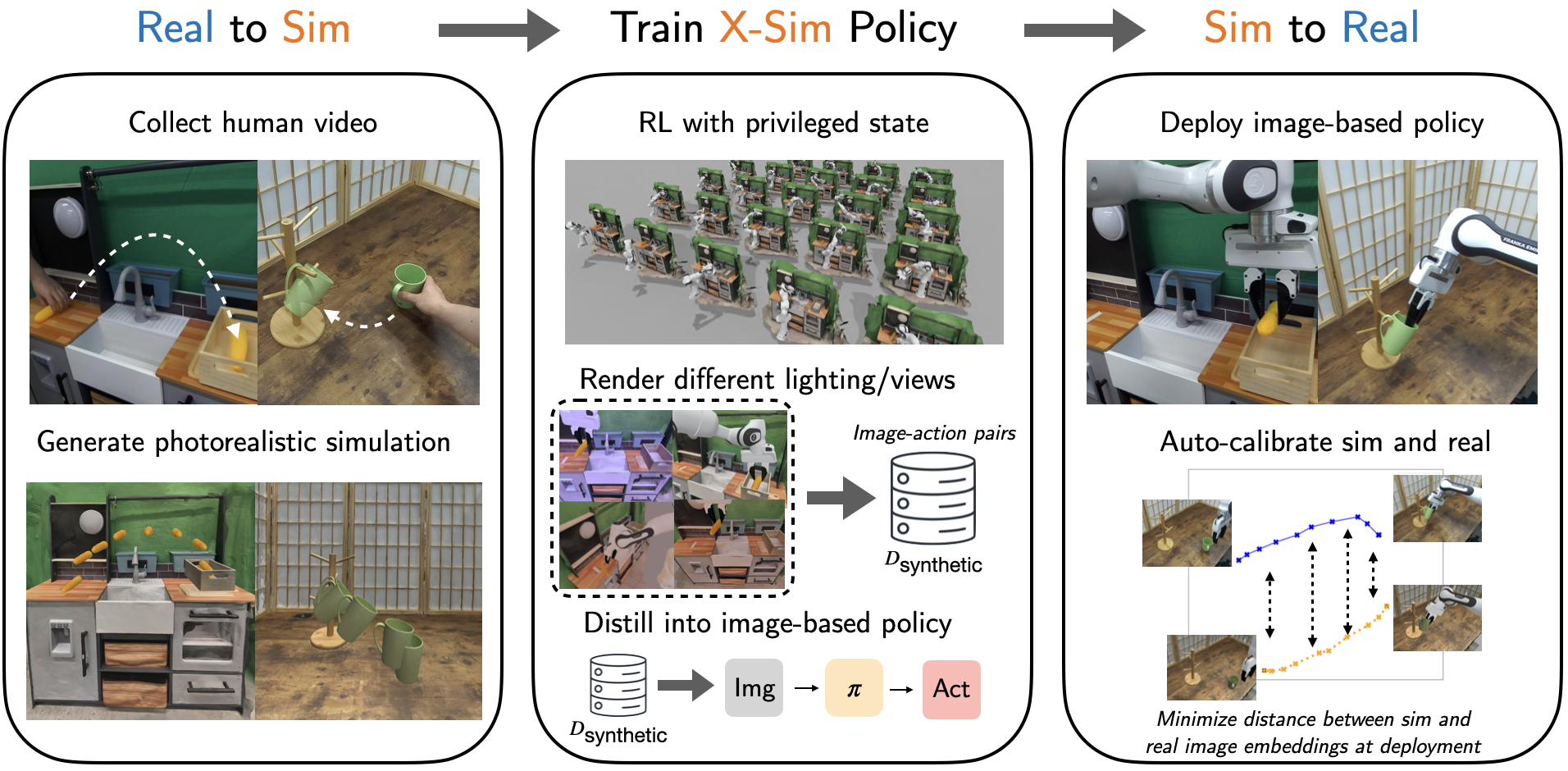
核心思路:X-Sim的核心思路是利用物体运动作为桥梁,将人类视频中的信息迁移到机器人控制策略中。通过重建逼真的模拟环境,并跟踪物体轨迹,可以定义与具身无关的、以物体为中心的奖励函数。这样,机器人就可以在模拟环境中学习如何操纵物体,而无需直接模仿人类的动作。
技术框架:X-Sim框架包含三个主要阶段:1) 真实到模拟 (Real-to-Sim):从RGBD人类视频重建逼真的模拟环境,并跟踪物体轨迹。2) 模拟环境强化学习 (RL in Simulation):使用物体轨迹定义的奖励函数,在模拟环境中训练强化学习策略。3) 模拟到真实 (Sim-to-Real):将学习到的策略提炼成图像条件扩散策略,并使用在线领域自适应技术对齐真实和模拟观测。
关键创新:X-Sim的关键创新在于使用物体运动作为密集且可迁移的信号,避免了直接映射人类和机器人动作的困难。此外,该方法引入了在线领域自适应技术,可以在部署期间动态地调整策略,以适应真实世界的变化。另一个创新点是使用图像条件扩散策略,提高了策略的泛化能力。
关键设计:在真实到模拟阶段,使用RGBD数据重建3D场景,并使用物体跟踪算法获取物体轨迹。在强化学习阶段,奖励函数基于物体与目标位置的距离。在模拟到真实阶段,使用CycleGAN等方法进行图像风格迁移,并使用对抗训练进行在线领域自适应。扩散策略使用U-Net结构,以图像作为条件,预测机器人的动作分布。
🖼️ 关键图片


📊 实验亮点
X-Sim在两个环境中的五个操作任务中进行了评估,结果表明,与手部跟踪和模拟到真实基线相比,任务进度平均提高了30%。此外,X-Sim在性能上与行为克隆相当,但数据收集时间减少了10倍。实验还表明,X-Sim能够泛化到新的相机视角和测试时变化,展示了其良好的泛化能力。
🎯 应用场景
X-Sim具有广泛的应用前景,可用于训练机器人执行各种操作任务,例如家庭服务、工业自动化和医疗辅助。该方法无需人工标注或机器人遥操作数据,降低了机器人学习的成本。通过跨具身学习,可以利用大量的人类视频数据来提升机器人策略的泛化能力和鲁棒性。未来,X-Sim可以扩展到更复杂的任务和环境,实现更智能、更灵活的机器人控制。
📄 摘要(原文)
Human videos offer a scalable way to train robot manipulation policies, but lack the action labels needed by standard imitation learning algorithms. Existing cross-embodiment approaches try to map human motion to robot actions, but often fail when the embodiments differ significantly. We propose X-Sim, a real-to-sim-to-real framework that uses object motion as a dense and transferable signal for learning robot policies. X-Sim starts by reconstructing a photorealistic simulation from an RGBD human video and tracking object trajectories to define object-centric rewards. These rewards are used to train a reinforcement learning (RL) policy in simulation. The learned policy is then distilled into an image-conditioned diffusion policy using synthetic rollouts rendered with varied viewpoints and lighting. To transfer to the real world, X-Sim introduces an online domain adaptation technique that aligns real and simulated observations during deployment. Importantly, X-Sim does not require any robot teleoperation data. We evaluate it across 5 manipulation tasks in 2 environments and show that it: (1) improves task progress by 30% on average over hand-tracking and sim-to-real baselines, (2) matches behavior cloning with 10x less data collection time, and (3) generalizes to new camera viewpoints and test-time changes. Code and videos are available at https://portal-cornell.github.io/X-Sim/.