LLM-Land: Large Language Models for Context-Aware Drone Landing
作者: Siwei Cai, Yuwei Wu, Lifeng Zhou
分类: cs.RO
发布日期: 2025-05-09
💡 一句话要点
提出LLM-Land框架,利用大语言模型实现上下文感知的无人机自主着陆。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机自主着陆 大语言模型 上下文感知 模型预测控制 视觉-语言编码器
📋 核心要点
- 传统无人机自主着陆方法在动态、非结构化环境中表现不佳,缺乏语义感知,依赖固定的、对上下文不敏感的安全裕度。
- LLM-Land框架利用视觉-语言模型提取场景信息,通过大语言模型推理安全距离,并结合模型预测控制进行轨迹规划。
- 实验结果表明,该框架能有效减少与动态障碍物的碰撞风险,并在复杂环境中保持较高的着陆精度,优于传统方法。
📝 摘要(中文)
本文提出了一种混合框架,将大语言模型(LLM)与模型预测控制(MPC)相结合,用于上下文感知的无人机自主着陆。该方法首先利用视觉-语言编码器(VLE),如BLIP,将实时图像转换为简洁的文本场景描述。然后,轻量级LLM(如Qwen 2.5 1.5B或LLaMA 3.2 1B)配备检索增强生成(RAG)来分类场景元素并推断上下文感知的安全缓冲区,例如行人3米,车辆5米。生成的语义标志和不安全区域被输入到MPC模块,实现实时轨迹重规划,避免碰撞,同时保持高着陆精度。在ROS-Gazebo模拟器中的验证表明,该框架始终优于传统的基于视觉的MPC基线,显著减少了与动态障碍物的近距离碰撞事件,同时在杂乱环境中保持了精确的着陆。
🔬 方法详解
问题定义:无人机自主着陆在应急物资运送、灾后响应等大规模任务中至关重要。然而,现有方法在动态、非结构化环境中面临挑战,主要痛点在于缺乏对环境的语义理解,导致无法根据上下文调整安全距离,容易发生碰撞风险。
核心思路:本文的核心思路是利用大语言模型(LLM)的强大推理能力,结合视觉信息,实现对环境的上下文感知,从而动态调整无人机的安全缓冲区。通过将视觉信息转化为文本描述,LLM可以识别场景中的元素(如行人、车辆),并根据常识知识推断出合理的安全距离。
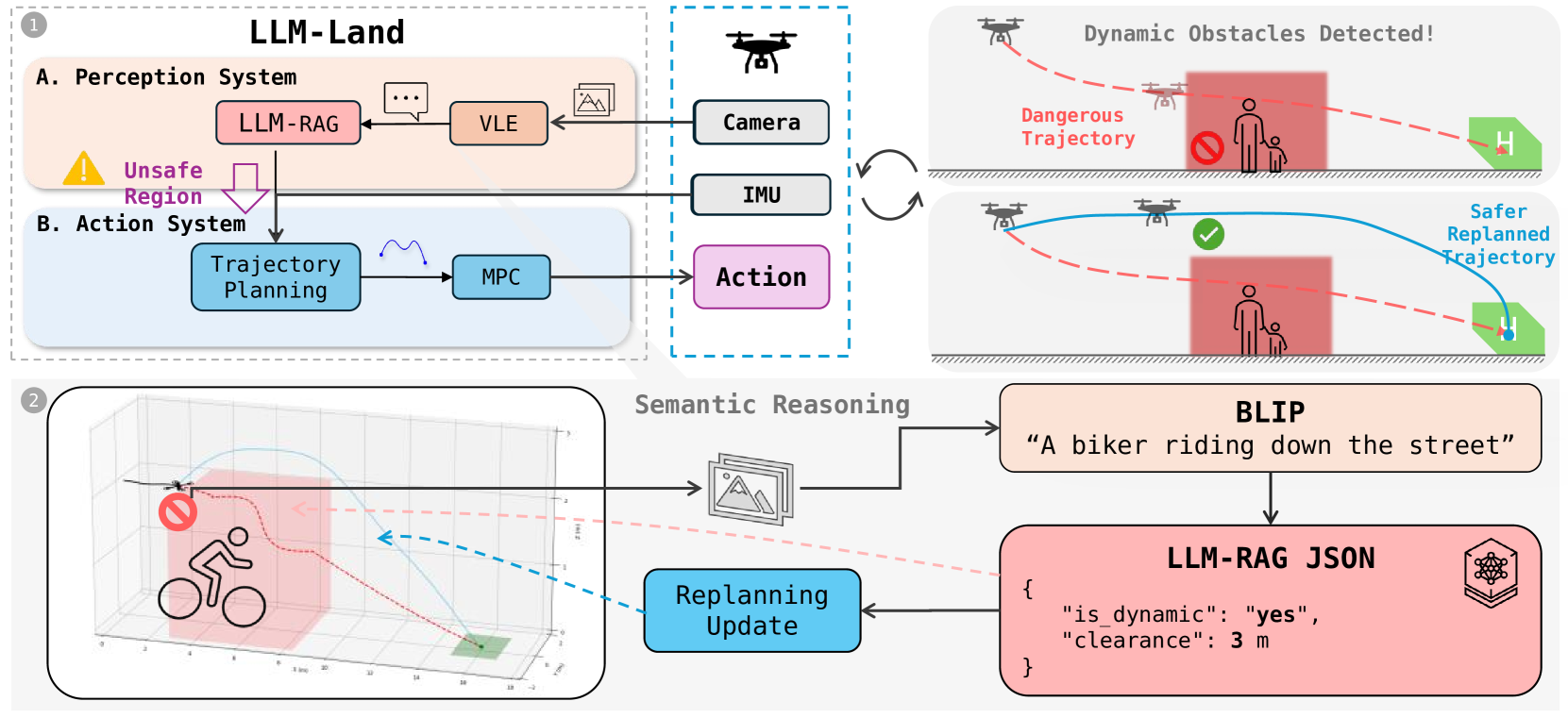
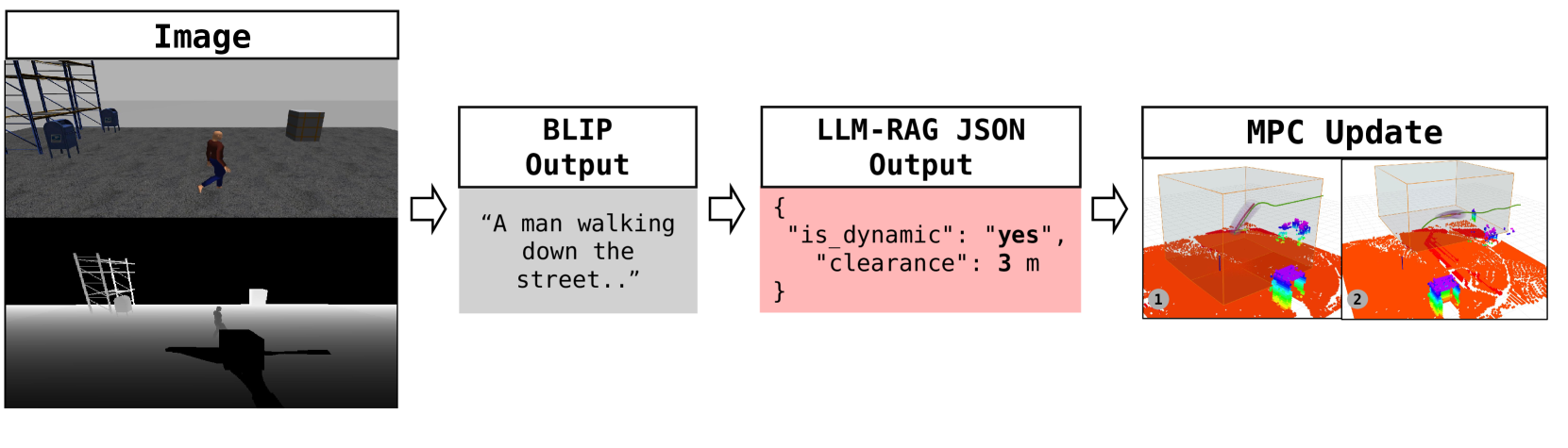
技术框架:LLM-Land框架主要包含三个模块:视觉-语言编码器(VLE)、大语言模型(LLM)和模型预测控制(MPC)。首先,VLE将无人机摄像头捕获的图像转换为文本描述。然后,LLM利用检索增强生成(RAG)技术,结合外部知识库,对场景元素进行分类,并推断出上下文相关的安全缓冲区。最后,MPC模块根据LLM提供的语义信息和安全区域,进行实时轨迹重规划,确保无人机安全着陆。
关键创新:该方法最重要的创新在于将大语言模型引入无人机自主着陆任务中,实现了上下文感知的安全裕度调整。与传统方法相比,LLM-Land能够根据场景的实际情况,动态调整安全距离,从而在复杂环境中实现更安全、更高效的着陆。
关键设计:VLE可以选择BLIP等模型,LLM可以选择Qwen 2.5 1.5B或LLaMA 3.2 1B等轻量级模型,以满足实时性要求。RAG技术用于增强LLM的知识储备,使其能够更好地理解场景信息。MPC模块采用标准的模型预测控制算法,根据LLM提供的安全区域进行轨迹规划。具体参数设置和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM-Land框架在ROS-Gazebo模拟器中优于传统的基于视觉的MPC基线。该框架显著减少了与动态障碍物的近距离碰撞事件,同时保持了精确的着陆性能。具体的性能提升数据未在摘要中给出,属于未知信息,但整体效果优于基线方法。
🎯 应用场景
该研究成果可广泛应用于应急物资运送、灾后救援、物流配送等领域。通过提高无人机在复杂环境中的自主着陆能力,可以显著提升任务效率和安全性。未来,该技术有望应用于更广泛的机器人自主导航领域,例如自动驾驶汽车、服务机器人等。
📄 摘要(原文)
Autonomous landing is essential for drones deployed in emergency deliveries, post-disaster response, and other large-scale missions. By enabling self-docking on charging platforms, it facilitates continuous operation and significantly extends mission endurance. However, traditional approaches often fall short in dynamic, unstructured environments due to limited semantic awareness and reliance on fixed, context-insensitive safety margins. To address these limitations, we propose a hybrid framework that integrates large language model (LLMs) with model predictive control (MPC). Our approach begins with a vision-language encoder (VLE) (e.g., BLIP), which transforms real-time images into concise textual scene descriptions. These descriptions are processed by a lightweight LLM (e.g., Qwen 2.5 1.5B or LLaMA 3.2 1B) equipped with retrieval-augmented generation (RAG) to classify scene elements and infer context-aware safety buffers, such as 3 meters for pedestrians and 5 meters for vehicles. The resulting semantic flags and unsafe regions are then fed into an MPC module, enabling real-time trajectory replanning that avoids collisions while maintaining high landing precision. We validate our framework in the ROS-Gazebo simulator, where it consistently outperforms conventional vision-based MPC baselines. Our results show a significant reduction in near-miss incidents with dynamic obstacles, while preserving accurate landings in cluttered environments.