Let Humanoids Hike! Integrative Skill Development on Complex Trails
作者: Kwan-Yee Lin, Stella X. Yu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-05-09
备注: CVPR 2025. Project page: https://lego-h-humanoidrobothiking.github.io/
💡 一句话要点
提出LEGO-H框架,解决复杂地形下人形机器人自主行走难题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 视觉Transformer 具身智能 复杂地形 自主行走 分层强化学习
📋 核心要点
- 现有方法在复杂地形下人形机器人行走方面存在不足,运动控制缺乏长期目标,语义导航忽略了机器人本体和地形变化。
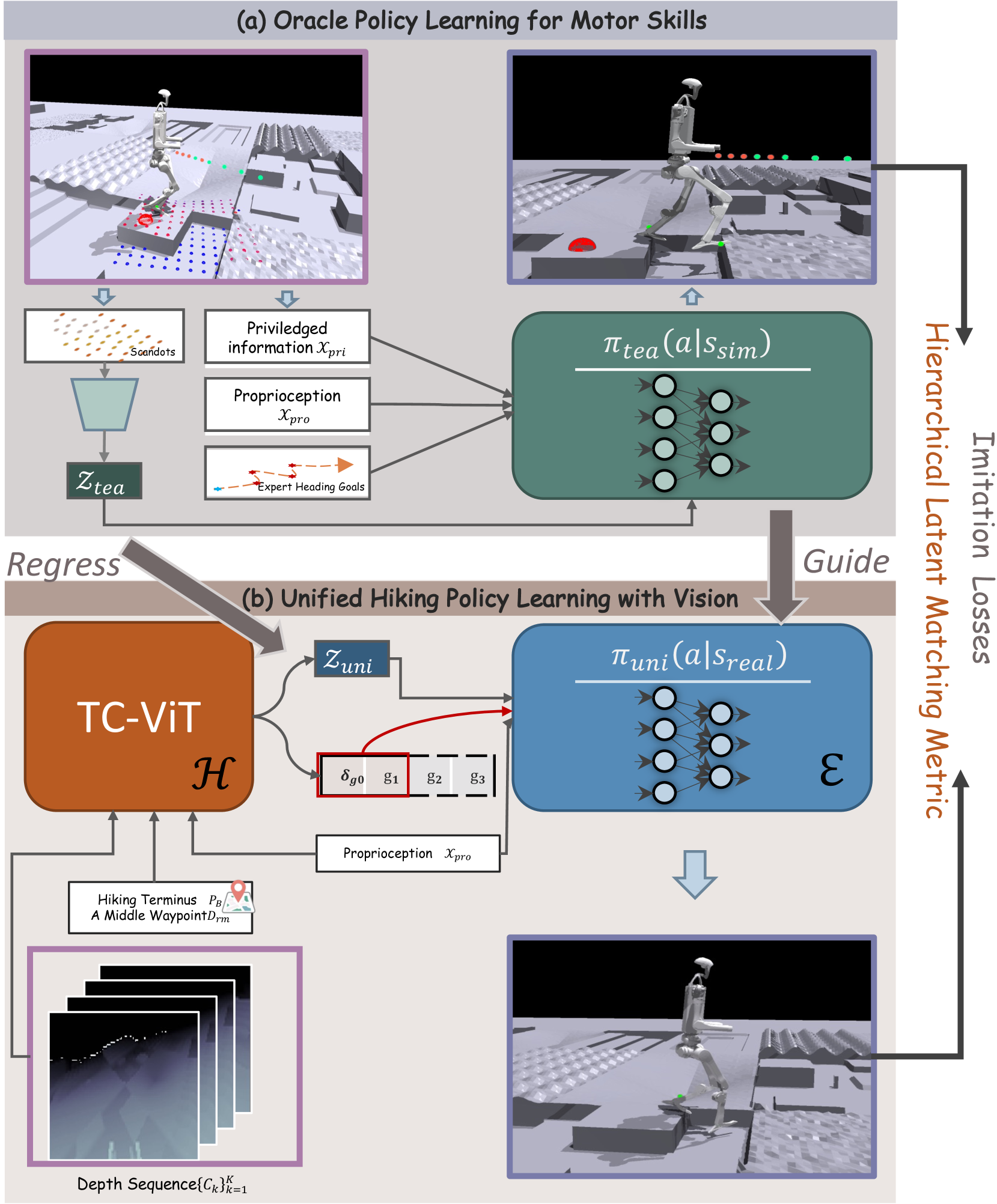
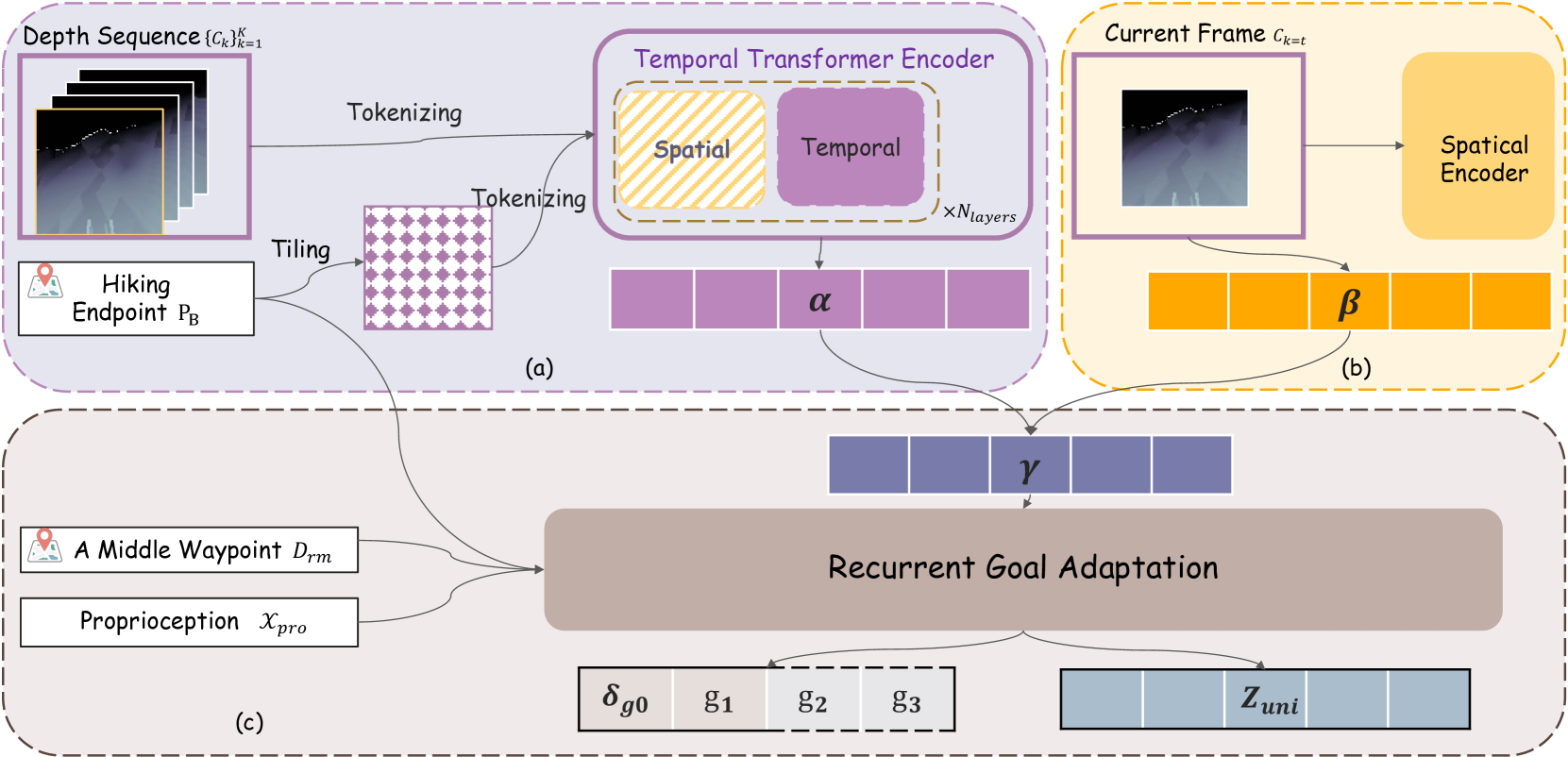
- LEGO-H框架通过时序视觉Transformer预测未来局部目标,指导运动,并结合分层强化学习实现运动控制与导航的融合。
- 实验表明,LEGO-H在不同地形和机器人形态下表现出通用性和鲁棒性,为具身自主提供了一个有价值的测试平台。
📝 摘要(中文)
在复杂地形上行走需要平衡性、灵活性以及对不可预测地形的自适应决策能力。目前的人形机器人研究仍然是分散的,不足以支持行走任务:运动控制侧重于运动技能,缺乏长期目标或情境感知;而语义导航忽略了真实的机器人本体和局部地形变化。我们提出训练人形机器人在复杂地形上行走,从而驱动视觉感知、决策制定和运动执行的综合技能发展。我们开发了一个名为LEGO-H的学习框架,使配备视觉系统的人形机器人能够自主地在复杂地形上行走。我们引入了两项技术创新:1) 一种时序视觉Transformer变体,被定制到分层强化学习框架中,预测未来的局部目标以指导运动,无缝地将运动控制与目标导向的导航相结合。2) 关节运动模式的潜在表示,结合分层度量学习,增强了特权学习方案,实现了从特权训练到板载执行的平滑策略迁移。这些组件使LEGO-H能够处理各种物理和环境挑战,而无需依赖预定义的运动模式。在各种模拟地形和机器人形态上的实验突出了LEGO-H的通用性和鲁棒性,将行走定位为具身自主的一个引人注目的测试平台,并将LEGO-H定位为未来人形机器人开发的基线。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂地形上自主行走的问题。现有方法的痛点在于,传统的运动控制方法缺乏对长期目标的考虑和情境感知能力,而语义导航方法则忽略了机器人自身的物理限制以及局部地形的细微变化,导致难以在实际环境中应用。
核心思路:论文的核心思路是将视觉感知、决策制定和运动控制三个方面进行整合,通过学习的方式使人形机器人能够自主地适应复杂地形。具体来说,利用视觉信息预测未来的局部目标,并将其融入到分层强化学习框架中,从而指导机器人的运动。同时,利用特权学习的方式,在训练阶段提供额外的状态信息,以提高策略的鲁棒性,并最终将学习到的策略迁移到实际的机器人上。
技术框架:LEGO-H框架包含以下几个主要模块:1) 时序视觉Transformer:用于从视觉输入中提取特征,并预测未来的局部目标。2) 分层强化学习:将行走任务分解为多个层次,高层负责导航,低层负责运动控制。3) 特权学习:在训练阶段,利用额外的状态信息(例如地形高度图)来提高策略的鲁棒性。4) 运动模式的潜在表示:利用潜在空间来表示不同的运动模式,从而实现平滑的策略迁移。
关键创新:论文的关键创新在于:1) 提出了一个时序视觉Transformer变体,能够预测未来的局部目标,从而将视觉感知与运动控制相结合。2) 提出了一个基于分层度量学习的特权学习方案,能够有效地利用额外的状态信息来提高策略的鲁棒性,并实现从模拟环境到真实环境的策略迁移。
关键设计:在时序视觉Transformer中,使用了注意力机制来关注重要的视觉特征,并利用时间序列模型来预测未来的局部目标。在分层强化学习中,使用了不同的奖励函数来鼓励机器人完成导航和运动控制任务。在特权学习中,使用了分层度量学习来学习一个潜在空间,使得相似的运动模式在潜在空间中距离较近。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LEGO-H框架在各种模拟地形和机器人形态下都表现出良好的通用性和鲁棒性。与传统的运动控制方法相比,LEGO-H能够更好地适应复杂地形,并实现更高效的行走。此外,通过特权学习,LEGO-H能够有效地将学习到的策略迁移到实际的机器人上,从而提高了机器人的实用性。
🎯 应用场景
该研究成果可应用于搜救、勘探、巡检等领域,使人形机器人能够在复杂、崎岖的地形中执行任务,降低人类的风险和成本。此外,该研究也为人形机器人的具身智能发展提供了新的思路,促进了机器人技术在更广泛领域的应用。
📄 摘要(原文)
Hiking on complex trails demands balance, agility, and adaptive decision-making over unpredictable terrain. Current humanoid research remains fragmented and inadequate for hiking: locomotion focuses on motor skills without long-term goals or situational awareness, while semantic navigation overlooks real-world embodiment and local terrain variability. We propose training humanoids to hike on complex trails, driving integrative skill development across visual perception, decision making, and motor execution. We develop a learning framework, LEGO-H, that enables a vision-equipped humanoid robot to hike complex trails autonomously. We introduce two technical innovations: 1) A temporal vision transformer variant - tailored into Hierarchical Reinforcement Learning framework - anticipates future local goals to guide movement, seamlessly integrating locomotion with goal-directed navigation. 2) Latent representations of joint movement patterns, combined with hierarchical metric learning - enhance Privileged Learning scheme - enable smooth policy transfer from privileged training to onboard execution. These components allow LEGO-H to handle diverse physical and environmental challenges without relying on predefined motion patterns. Experiments across varied simulated trails and robot morphologies highlight LEGO-H's versatility and robustness, positioning hiking as a compelling testbed for embodied autonomy and LEGO-H as a baseline for future humanoid development.